







前言
这篇文章主要用简单的线性回归模型来介绍统计学中一些很重要的概念。比如:置信区间(confidence interval)、t-statistic、p-value、 R2 statistic和F-statistic等一些概念。我会用具体的数据集来分析这些值分别意味着什么?并用具体的R代码来分析数据集并做出一个好的决策?
数据分析之前的几个重要问题
在提出问题之前,我先介绍一下Advertising数据集。数据集包含了200个不同市场的产品销售额,每个销售额对应3种广告媒体,分别是:TV, radio, 和 newspaper
如果我们能分析出广告媒体与销售额之间的关系,我们就可以更好地分配广告开支并且使销售额最大化。换句话说:我们的目标是开发出一个基于这3个广告媒体,准确预测销售额的模型。
下面,我提出几个问题,有着这些问题目标,我们的数据分析才有意义。
- 广告预算与销售额之间存在关系吗?
- 如果存在关系,它们之间的关系有多强?
- 哪个媒体与销售额之间存在关系?
- 每个媒体对销售额有多大的影响?
- 我们对未来销售额的预测有多准确?
这篇文章中,我们假设线性模型是正确的,销售额之间是不存在协同关系的。在以后的文章中,我会写这些问题的。
估算线性回归系数并评估其准确性
为了清楚地解释一些统计学上的概念,在这里我只用最简单的线性回归,也就是只有一个变量的模型。定义如下模型:
在用R估算两个系数之前,我先给出residual sum of squares(RSS)的定义。如下:
least squares方法就是选择出最好的 β0^和β1^ 来最小化RSS.下面我用具体的R代码来做这件事情。
adver <- read.csv("Advertising.csv",colClasses=c("NULL",NA,NA,NA,NA)) # 读取Advertising数据集,跳过第一列
fitadver=lm(Sales~TV,data=adver) # 用线性回归fit
coef(fitadver) # 查看估算出的系数
# plot数据点和已经估算出的线,图形如下
plot(adver$TV, adver$Sales, col="red", xlab='TV', ylab='sales')
abline(fit1)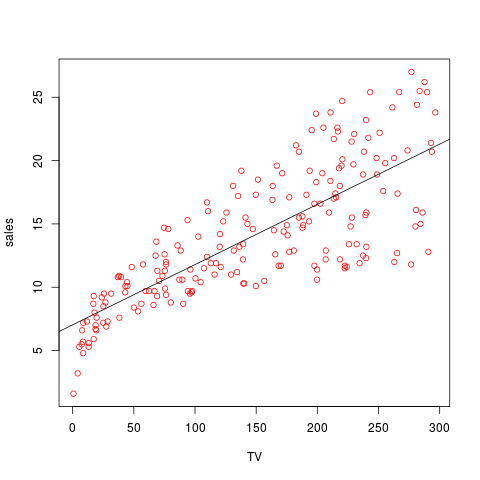
PS:如果你想保存你的Plots作为图片,下面的代码就行,具体其它的格式请参考Saving Plots in R
dev.copy(png,'myplot.png')
dev.off()为了更好地分析数据,下面给大家来点理论知识吧。哈哈!!!
上面我们已经估算出了相应的系数,可是这个系数有多么准确呢?为了更好地解释这个,我先举个例子。假设我们有一个随机变量Y,我们想找出它的平均值 μ ,但是我只知道它可能取到的一部分值 y1,y2,…,yn , 因此这部分值的平均值是对 μ 很合理的一个估算。除非我们非常幸运,否则我们的这个估算值是不可能等于 μ 的,它要么比 μ 小,要么比 μ 大。但是,如果我们有很多这样的集合,我们就可以有很多的估算值,然后我们把这些值平均下来就会等于 μ 了。那么对 β0和β1 的估算是同样的道理。
我们已经知道把很多数据集上估算的值平均下来会很接近真正的 μ 值。但是,单个估算的值会与真正的 μ 值相差多少呢?为了回答这个问题,我们要求出 μ^ 的standard error.记作 SE(μ^) .这里有个非常有名的公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









