







解码是对于输入序列x找出概率最大的输出序列l,而不是概率最大的一条输出路径,因为输出路径和输出序列是多对一关系。
l
∗
=
a
r
g
m
a
x
{
p
(
l
∣
x
)
}
l^*=argmax \{p(l|x)\}
l∗=argmax{p(l∣x)}
best path decoding
最优路径找出每一帧输出的最大概率组成的输出序列即为最后的解码结果,这种方式会引入问题。
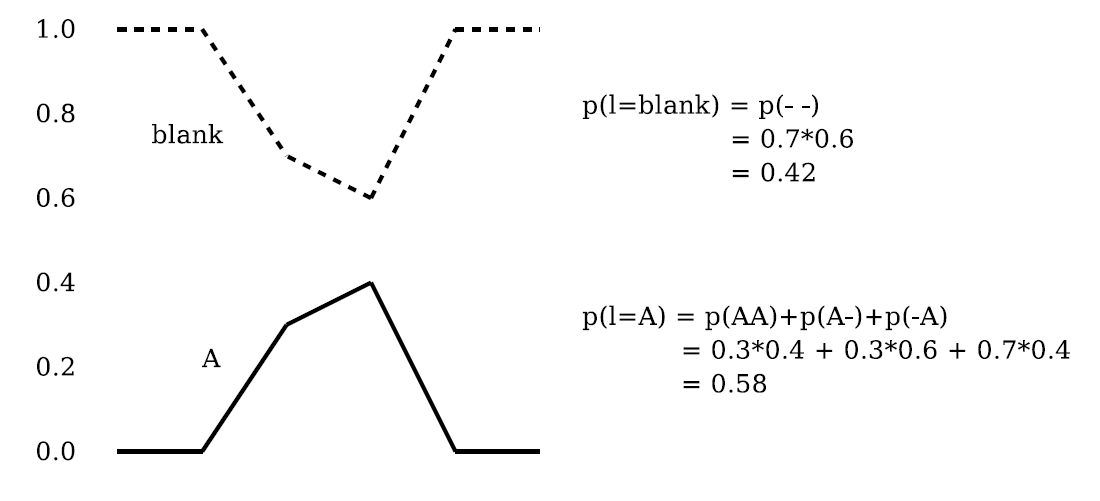
对于上图,这种方法解码出来的结果是blank,但是A的概率反而更高。
constrained decoding
对于语音识别,可以引入语言模型等grammar限制,求解问题变为如下形式:
l
∗
=
a
r
g
m
a
x
{
p
(
l
∣
x
)
}
{
p
(
l
∣
G
)
}
l^*=argmax \{p(l|x)\}\{p(l|G)\}
l∗=argmax{p(l∣x)}{p(l∣G)}
其中G表示grammar。
可以使用传统的token传播算法进行解码。
算法流程图如下:

假设词典D包含2个单词w,分别是{北,京},每个单词对应两个因素,所以
∣
w
′
∣
=
5
|w'|=5
∣w′∣=5
北 b ei
京 j ing
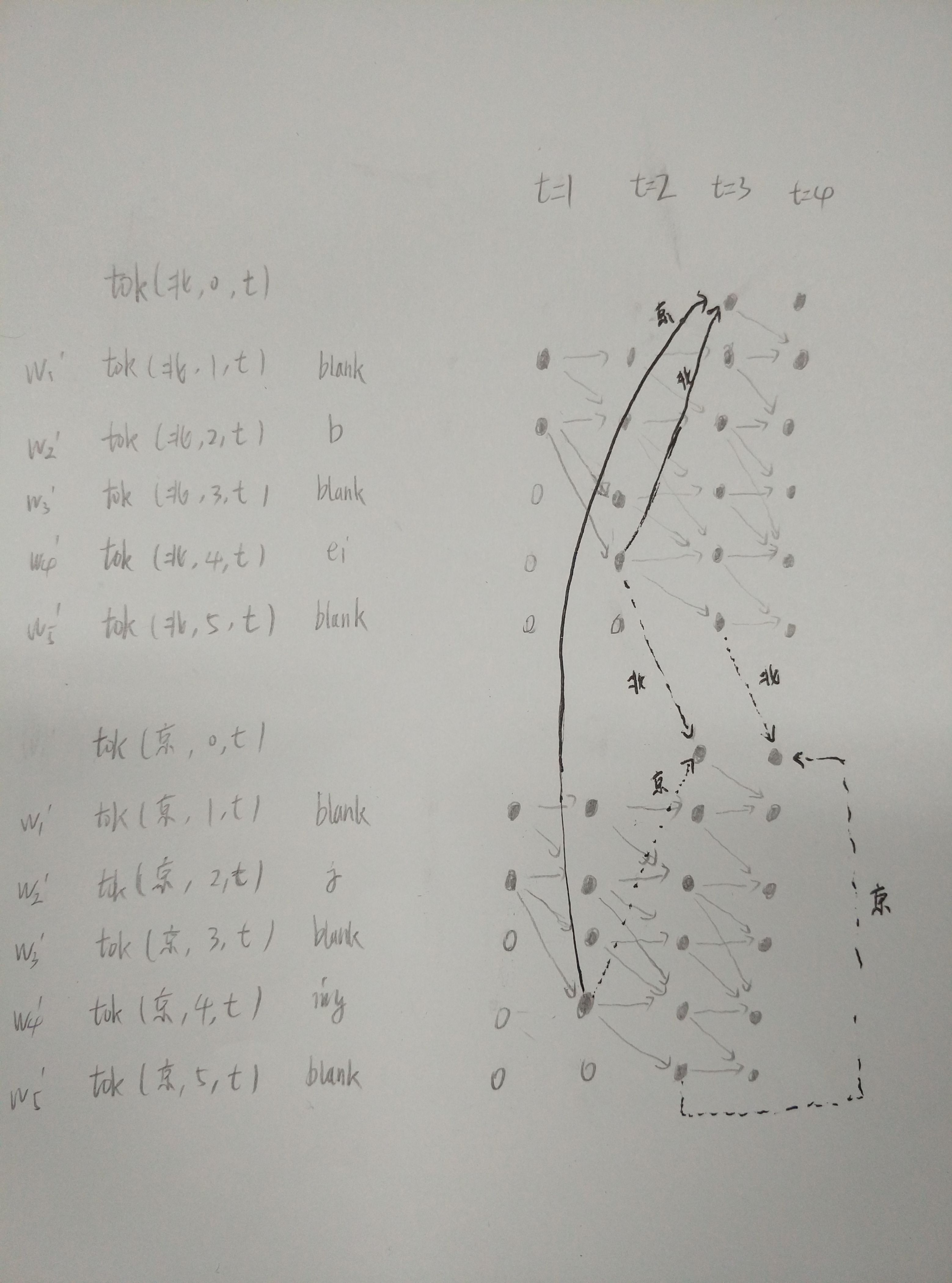
当t=1的时候,每个w的前两个tok被激活
当t=2的时候,每个w的tok只能在单词内传播,对于“北”来说,tok(北,3,2)和tok(北,4,2)将会被激活,同时tok(北,2,2)有两条路径可以达到,这里取两条路径的最大概率,加上b音素在t=2时刻对应的概率的对数值,作为tok(北,2,2)的得分。与此同时,b->ei这条路径完成了“北”这个单词对应的输出,所以此时“北”将会有对应的输出tok(北,-1,2)。
当t=3的时候,对于“京”这个单词,除了正常的单词内tok传播,还将涉及到单词和单词之间的tok传播,找到所有单词w的输出tok得分和p(京|w)之和的最大值,作为tok(京,0,3),并且将该w对应的单词放到tok(京,0,3)的history。tok(京,0,3)将可以向tok(京,1,4)传播。
以此类推…
整体上来看,解码过程类似于hmm的维特比,找出最大概率对应的路径,不同之处在于ctc解码引入了blank节点用于得到最终的输出序列,而不关心每一帧的输出结果。
通过设定beam,可以对每个时刻t对应的word输出tok进行剪枝,加快解码速度。
后面的技术分享转移到微信公众号上面更新了,【欢迎扫码关注交流】















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









