







 本文介绍了如何利用Storm技术构建分布式并行计算环境,实现个性化视频推荐算法。算法基于item-based和rand策略,结合用户行为数据和视频元数据生成推荐候选集。Storm拓扑设计包括实时日志Spout、聚合Bolt、计数Bolt和推荐计算Bolt,确保在毫秒级完成实时推荐。
本文介绍了如何利用Storm技术构建分布式并行计算环境,实现个性化视频推荐算法。算法基于item-based和rand策略,结合用户行为数据和视频元数据生成推荐候选集。Storm拓扑设计包括实时日志Spout、聚合Bolt、计数Bolt和推荐计算Bolt,确保在毫秒级完成实时推荐。
随着互联网的蓬勃发展,近年来利用互联网技术实现各类面向个人用户的服务系统层出不穷,其中在线视频网站系统就是其中一类典型的服务场景,利用用户在站点上实际的行为活动数据,准确地为每个用户推荐个性化、时效性和多样化的视频集合,已经成为该类服务场景中所面临的一个巨大挑战。本文主要介绍如何构建“视频推荐”算法应用场景,并利用Storm技术搭建分布式并行计算环境解决以上需求的方案。算法部分主要参考了 Davidson, J. and Liebald, B. and Liu, J. The YouTube video recommendation system. Proceedings of the fourth ACM conference on Recommender systems. 2010和【转】Youtube视频推荐算法:从10页论文到4页论文的变迁,另外,Storm实现方案方面参考了基于storm的在线关联规则。
综述
在大数据的时代里,互联网以及公司的日常运营经常会生成TB级别或以上的数据。在如今的互联网应用服务场景中,“个性化推荐”算法已经成为对于信息数据提取和内容挖掘的一项关键技术。结合搜索和浏览,在面临巨大信息数据量的情况下,为用户高效地定位出令人满意的推荐信息,是系统运营中一个至关重要的技术,尤其是对于一个大型的、流行的在线视频网站系统尤为重要。
用户进入在线视频网站的主要原因是通过搜索引擎系统使用关键字检索,点击链接观看一个视频,而用户深层次的需求是想要观看围绕同一个主题的一系列视频资源,或者是他们仅仅是对某一特定类型的视频内容感兴趣。“个性化视频推荐”算法是解决以上需求的一种方法,它可以实现提供个性化的推荐,帮助用户获取他们所感兴趣的高质量的视频资源,从而保持用户的访问量和持续浏览网站的热情,这些推荐主要是来源于用户在网站上的浏览习惯和实际行为所产生的大量数据,本文将利用关联分析等数据挖掘技术和方法,为采用top-N推荐方式的在线视频网站系统提供一种可行性的方法,实现准确地为每个用户推荐个性化的视频集合。
另外,也将会利用Storm技术为“个性化视频推荐”算法场景实际地设计和搭建分布式并行计算环境。
算法设计
“个性化视频推荐”算法的设计主旨是推荐与用户在站点上实际的行为活动数据相关联的个性化、时效性和多样性的视频集合,该算法主要分为item-based算法和rank算法。
推荐视频集合来源于每个用户的个人行为活动,这些行为活动可包括观看、收藏、评价等。item-based算法将通过以上每个用户行为活动中所产生的全部视频作为一个面向该用户的种子集合,并通过对该种子集合中的每个视频与其他视频的相似关联关系建立成一个有向图,最后寻找它在有向图上的最近邻居,并以此作为推荐的候选。
选择出候选集后,采用rank算法对候选集中的视频进行过滤和排序,从而达到所推荐视频集合的时效性和多样化。
输入数据
两类数据作为整个推荐系统的输入数据,所有的推荐都是基于这些数据进行的,它们是:
(1)视频的元数据,如标题、类型、长度、描述、观看次数等;
(2)用户的交互数据,这些数据分为显示和隐式的,显示的包含收藏、标注、评价等,隐式的包含点击观看相关的行为数据等。
item-based算法
第一步会计算出所有视频的相似视频集合,这个相似视频集合是通过关联挖掘计算出来的。把同一个用户一段时间(通常为24小时)内看的所有视频看做一个Session,属于同一个Session内的视频被认为是相似的,将Session中的视频根据连续性拆分成一个一个的视频对,这样就简化地生成了一系列的二项集。
通过算法挖掘频繁二项集,具体计算公式如下:
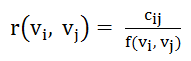
其中Ci和Cj是Vi和Vj在全部Session中所产生的总数,Cij为同时包含Vi、Vj视频对的Session的个数,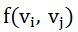
计算得到所有视频的相似视频集合后,将这些相似关系建立成一个有向图video graph,例如V的相似视频集合R,则V节点到R中每个元素Vn存在一条指向该元素的边,而每条边都有一个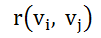
最后,就是根据这个有向图video graph来为某个用户u生成候选推荐视频集合。推荐时,对于某个用户u先利用该用户的交互数据(可能来自于用户的收藏、评星或者简单的收看记录)解析出用户seed video集合,作为推荐的依据。然后从有向图video graph中取出所有seed video寻找它在video graph上的最近邻居(相似度分值最高),并以此作为推荐的候选,从而形成了一个推荐视频候选集。以上item-based方法通常会压缩推荐候选的范围,即这种方法得到的结果通常多样性比较差。可以采用搜索最近邻居的基础上加以扩展来搜索多阶的最近邻居,也可以根据用户seed video集合中视频的多少,通过设置阈值的方式来扩大选取邻居的个数,从而扩大推荐视频候选集。
rand算法
推荐视频候选集会作为rand算法的输入,通过过滤算法和排序算法完成对最终推荐视频集的计算。
(1)过滤算法
过滤算法主要分为两大类的过滤,第一类是排除过滤器,在推荐视频候选集中可能会存在用户已经观看过的视频,因此需要通过与用户seed video集合做差集的操作,排除类似视频;第二类打压热门过滤器,对于在推荐视频候选集中本身就非常热门的视频,该视频实际曝光量已经非常大,并有可能已经在全站推荐视频集中,为个人用户推荐在很大程度是失去了本来的目的,因此需要通过为推荐视频候选集中每个视频被观看的次数设置一个阈值,观看次数大于该阈值的视频便被过滤掉。
(2)排序算法
排序算法可以考虑两种比较典型因素:
1)视频的质量,主要取决于视频上传时间、播放、评星、分享、评论等视频本身的数据
2)跟用户的切合程度,主要取决于用户对种子集中视频的喜好程度,比如用户是否对该seed video进行过收藏,或推荐视频本身的相似度分值很高。
3)多样性,主要取决于推荐视频类型的差异性,比如A类型视频在推荐视频候选集中有10个,B类型视频在推荐视频候选集中有1个,B类型在推荐时就被优先考虑。
然后,把这三方面的因素作一个线性加权,就得到了推荐集中每个视频的权重,接下来通过对权重排序,完成最终推荐视频集。
Storm实现方案
在大数据的业务场景中,有批量分析的场景,这些分析大多以长期积累的大量数据为基础进行各维度的挖掘计算和统计,对于这类场景大多使用Hadoop作为一个批量处理系统,Hadoop在海量静态数据处理上得到了广泛的使用。但是,Hadoop不擅长实时计算,这也是业界一致的共识,而对于在线视频网站为用户推荐视频的场景则要求一定的实时性,这些实时的处理往往要求在毫秒级完成,因为只有这样的处理时限内结果才有意义。而Storm是实时的、分布式以及具备高容错性的并行计算框架,非常适合于高效处理源源不断的数据源,并实时并行计算和输出结果。
拓扑设计
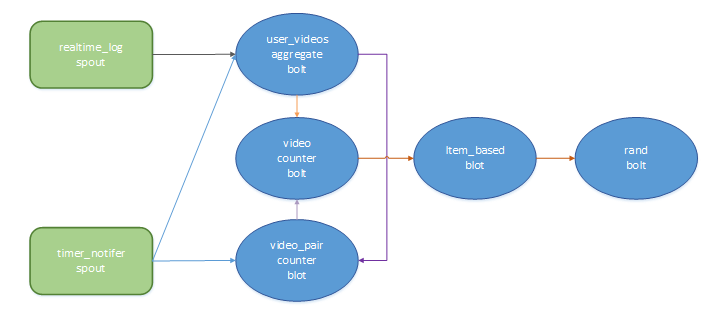
Storm本身是流式计算框架,这里需要用到统计用户看过的视频集,所以需要一个池子不停的收集用户看过的视频,定时的放水(定时放水的任务就由timed_notifier-spout完成)。所以整体计算的流程如下描述:
1)realtime_log-spout按user分组,将数据流推给user_videos-aggregate-bolt;
2)timed_notifer-spout 会定期向下游推送时间窗口关闭的通知;
3)user_videos aggregate-bolt里面维护一个map,里面保存在时间窗口内用户及其观看过的视频集的映射。它每接收到一条日志就会更新这个map,同时向计数器video-counter-bolt发送一组播放数据,也会将map里面的数据构建成视频对组,随机推送给计数器video_pair-counter-bolt;
4)video_pair-counter-bolt也会维护一个map,用以视频对的计数。 当收到timerd_notifer-spout的通知时向video-counter-bolt发送这些统计信息数据stream,并清空这个map;
5)video-counter-bolt也会维护一个map,里面是视频被观看次数的映射。它每接收到一个stream都会分析其类型,如果是计数类型的就会更新这个map,如果收到的是video_pair-counter-bolt的stream,便会将其维护map中的统计信息数据数据与video_pair-counter-bolt的stream数据进行整合后,捆绑成一个stream向下游推送;
6)item_based-bolt接收到video-counter-bolt所发送的stream后,使用item_based的算法计算出每个user的推荐视频候选集,推送给下游;
7)rand-bolt接收到推荐视频候选集stream后,便使用rand算法为每个user计算出该时间窗口内的视频推荐集,最后将推荐集更新到用户空间中,从而达到向用户推荐top-N视频的目的。
代码实现
Mock环境构建
Mock环境采用Redis存储相关的用户点击播放日志、视频全局播放次数,通过InitMocker初始化Mock环境,通过UserMocker不断模拟产生新的用户操作产生数据,代码参考如下:
public class InitMocker {
private final static int USER_NUM = 1000;//模拟用户数
private final static int VIDEO_NUM = 100;//模拟视频数
public void mock(){
clearMock();
videosInitMock();
cilckedInitMock();
}
public void resetMock(){
clearMock();
mock();
}
public void clearMock(){
Jedis jedis = RedisUtil.getJedis();
jedis.flushDB();
RedisUtil.returnResource(jedis);
}
/**
* 用户点击查看视频的模拟数据生成器
*/
private void cilckedInitMock(){
Jedis jedis = RedisUtil.getJedis();
Random rand = new Random();
//为每个用户通过Redis的List类型生成一组顺序的视频观看记录
for(int i = 0; i < USER_NUM; i++){
for(int j = 0; j < (rand.nextInt(20) + 2); j++){
jedis.lpush(String.valueOf(i), String.valueOf(rand.nextInt(VIDEO_NUM)));
}
}
RedisUtil.returnResource(jedis);
}
/**
* 视频全局观看次数模拟数据生成器
*/
private void videosInitMock(){
Jedis jedis = RedisUtil.getJedis();
Random rand = new Random();
//为每个视频生成一定的观看次数记录
for(int i = 0; i < VIDEO_NUM; i++){
jedis.set("video" + i, String.valueOf(rand.nextInt(50)));
}
RedisUtil.returnResource(jedis);
}
public static int getUserNum(){
return USER_NUM;
}
public static int getVideoNum(){
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









