







 MapReduce2.0是Hadoop生态中的重要组件,主要用于离线大数据处理。本文介绍了MapReduce的典型应用WordCount,详细阐述了Map和Reduce阶段的工作流程,包括InputFormat、Partitioner和Combiner的作用。MapReduce框架具有易于编程、良好扩展性和高容错性的优点,但也存在不适合实时计算和DAG计算的缺点。MapReduce2.0在YARN上运行,提供数据本地性和推测执行等优化机制,增强了系统的容错能力。
MapReduce2.0是Hadoop生态中的重要组件,主要用于离线大数据处理。本文介绍了MapReduce的典型应用WordCount,详细阐述了Map和Reduce阶段的工作流程,包括InputFormat、Partitioner和Combiner的作用。MapReduce框架具有易于编程、良好扩展性和高容错性的优点,但也存在不适合实时计算和DAG计算的缺点。MapReduce2.0在YARN上运行,提供数据本地性和推测执行等优化机制,增强了系统的容错能力。
MapReduce典型应用,WordCount
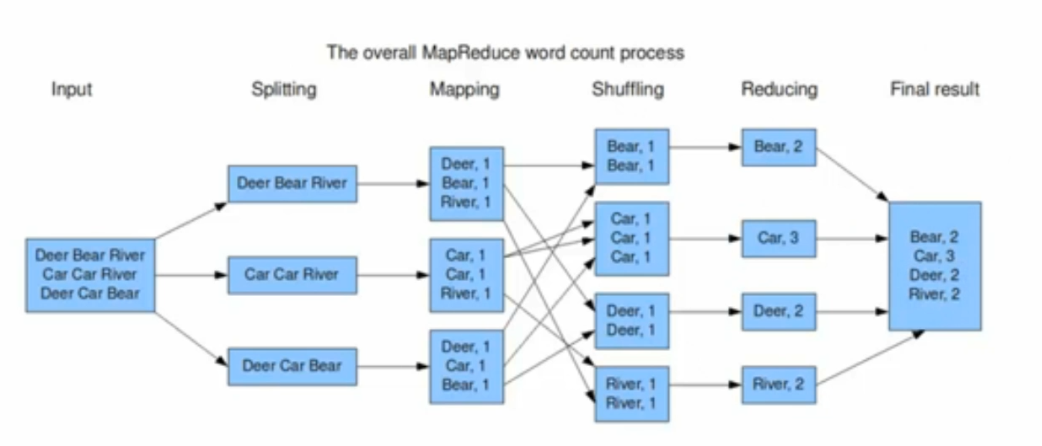
Map阶段:首先将输入数据进行分片,然后对每一片数据执行Mapper程序,计算出每个词的个数,之后对计算结果进行分组,每一组由一个Reducer程序进行处理,到此Map阶段完成。
Reduce阶段:每个Reduce程序从Map的结果中拉取自己要处理的分组(叫做Shuffling过程),进行汇总和排序(桶排序),对排序后的结果运行Reducer程序,最后所有的Reducer结果进行规约写入HDFS。
MapReduce框架的优点:
- 易于编程,用户通常情况下只需要编写Mapper和Reducer程序即可。
- 良好的扩展性,即可以很容易的增加节点
- 高容错性,一个Job默认情况下会尝试启动两次,一个mapper或者reducer默认会尝试4次,如果一个节点挂了,可以向系统申请新的节点来执行这个mapper或者reducer
- 适合PB级别的数据的离线处理
MapReduce框架的缺点
- 不擅长实时计算,像MySQL一样能够立即返回结果
- MapReduce的设计本身决定了处理的数据必须是离线数据,因为涉及到数据切分等等。
- 不擅长DAG(有向图)计算,需要一个Job执行完成之后,另一个Job才能使用他的输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









