







 本文详细介绍了Hadoop MapReduce的工作流程,包括数据类型、InputFormat、Partitioner、Combiner、GroupingComparator以及二次排序的实现。重点探讨了Partitioner在不同场景下的应用,特别是当Reducer数量为1时的情况。文中还通过代码示例解释了如何自定义Partitioner和GroupingComparator以实现二次排序,确保数据在MapReduce过程中既按Key排序,又按Value排序。
本文详细介绍了Hadoop MapReduce的工作流程,包括数据类型、InputFormat、Partitioner、Combiner、GroupingComparator以及二次排序的实现。重点探讨了Partitioner在不同场景下的应用,特别是当Reducer数量为1时的情况。文中还通过代码示例解释了如何自定义Partitioner和GroupingComparator以实现二次排序,确保数据在MapReduce过程中既按Key排序,又按Value排序。
1. MapReduce 处理的数据类型
1.1 必须实现 org.apache.hadoop.io.Writable 接口。需要实现数据的序列化与反序列化,这样才能在多个节点之间传输数据!
示例:
public class IntWritable implements WritableComparable<IntWritable> ,
public interface WritableComparable<T> extends Writable, Comparable<T>Writable 接口定义如下:
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}在IntWritable中的实现如下:
@Override
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}1.2 Key 必须实现WritableComparable
在MapReduce的过程中,需要对key进行排序,而key也需要在网络流中传输,因此需要实现WritableComparable,这是一个标志接口,实现了Writable, Comparable两个接口。
在IntWritable中的实现如下:
@Override
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable)o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
@Override
public int compareTo(IntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue<thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
}2 InputFormat
接口声明如下:
public interface InputFormat<K, V> {
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;InputFormat负责
1. 将输入文件进行逻辑切分(getSplits),每个分片形成一个InputSplit对象,每个InputSplit对象由一个Mapper对象(里面有我们自己需要实现的map方法)接收和处理,对应一个Map Task 任务。
2. 在一个Mapper对象处理一个InputSplit对象时,由getRecordReader方法提供更细致的切分,比如FileInputFormat是按行切分的,每行作为一个Mapper 的输入。
FileInputFormat的实现:
其中getSplits默认是按Block大小进行切分的。
getRecordReader仍然是个抽象函数。
默认情况下我们使用的是 public class TextInputFormat extends FileInputFormat
public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
String delimiter = job.get("textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter) {
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
}
return new LineRecordReader(job, (FileSplit) genericSplit,
recordDelimiterBytes);
}可见,其先按行切分,然后按delimiter这个值切分得到一条条记录的。
3 Partitioner
3.1
经过InputFormat对数据的切分后,每个Mapper的输出结果是一系列的kv对,需要通过Patitioner把每条kv对标记为属于的某个Reducer,这样Reducer就可以拉取Mapper得到的结果。
接口定义如下:
public interface Partitioner<K2, V2> extends JobConfigurable {
/**
* Get the paritition number for a given key (hence record) given the total
* number of partitions i.e. number of reduce-tasks for the job.
*
* <p>Typically a hash function on a all or a subset of the key.</p>
*
* @param key the key to be paritioned.
* @param value the entry value.
* @param numPartitions the total number of partitions.
* @return the partition number for the <code>key</code>.
*/
int getPartition(K2 key, V2 value, int numPartitions);
}默认情况下,我们使用的是HashPartitioner
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}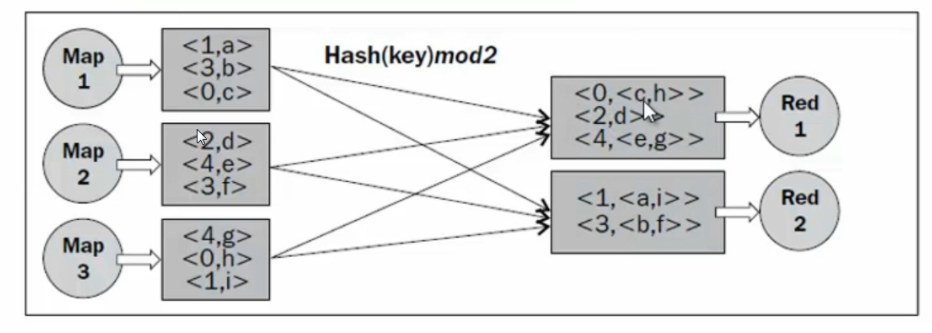
================================图3.1Partition过程================================
使用Hash的方式是所有的key的hashcode对reduce的数目取余数,因此虽然能够保证每个key相同的kv对会发送到同一个Reducer任务进行处理,但是当某个key对应的kv对数非常大,而其他却非常小时,这个Reducer节点就成了高负载节点,造成了计算资源的分配不均衡。
在Map阶段,可以使用job.setPartitionerClass设置的partition类进行自定义Partitioner
我们分析其过程:
job.java
public void setPartitionerClass(Class<? extends Partitioner> cls
) throws IllegalStateException {
ensureState(JobState.DEFINE);
conf.setClass(PARTITIONER_CLASS_ATTR, cls,
Partitioner.class);
}由以上设置过程中,可知,通过用户对job对象的属性设定,Partitioner的类入口被记录在了MRJobConfig.java的PARTITIONER_CLASS_ATTR中:这里PARTITIONER_CLASS_ATTR是一个key值,而 Partitioner.class是其对应的value值。
public static final String PARTITIONER_CLASS_ATTR = "mapreduce.job.partitioner.class";当要找到这个Partitioner类时:
JobContextImpl.java
//public class JobContextImpl implements JobContext
public Class<? extends Partitioner<?,?>> getPartitionerClass()
throws ClassNotFoundException {
return (Class<? extends Partitioner<?,?>>)
conf.getClass(PARTITIONER_CLASS_ATTR, HashPartitioner.class);
}可见默认的是HashPartitioner。
而对于Hadoop2.0 newPAI在JobConf.java中有PartitionerClass的set和get方法。
public void setPartitionerClass(Class<? extends Partitioner> theClass) {
setClass("mapred.partitioner.class", theClass, Partitioner.class);
}而获取Partitioner的类入口为
//JobConf.java
public Class<? extends Partitioner> getPartitionerClass() {
return getClass("mapred.partitioner.class",
HashPartitioner.class, Partitioner.class);
}可见默认的partitioner 仍然是HashPartitioner。
3.2 但是真的是这样吗?
我们思考,当Reducer的数量只有1个的时候,上述的HashPartition而的逻辑岂不是白费了!?
我们在HashPartition类内部做如下修改:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {
@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
int result = (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
System.out.printf("hase-partition:key\t%s,val\t%s,result:%n",key.toString(),value.toString(),result);
(new Exception()).printStackTrace();
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}这样在调用HashPartitioner的过程中就会打印异常栈了。
然而当Reducer只有一个的时候,上述异常并没有被触发!
再次查看3.1节的分析ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4639
4639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









