







HashTable-散列表/哈希表
是根据关键字(key)而直接访问在内存存储位置的数据结构。
它通过一个关键值的函数将所需的数据映射到表中的位置来访问数据,这个映射函数叫做散列(哈希)函数,存放记录的数组叫做散列表。
构造哈希表的几种方法
1.直接定址法(取关键字的某个线性函数为哈希地址)
2.除留余数法(取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址)
3.平方取中法
4.折叠法
5.随机数法
6.数学分析法
常用方法是
直接定址法和
除留余数法
哈希冲突/哈希碰撞
不同的Key值经过哈希函数Hash(Key)处理以后可能产生相同的值哈希地址,我们称这种情况为哈希冲突。任意的散列函数都不能避免产生冲突。
处理哈希碰撞的方法
若key1,key2,key3产生哈希冲突(key1,key2,key3值不相同,映射的哈希地址同为key),用以下方法确定它们的地址
1.闭散列法
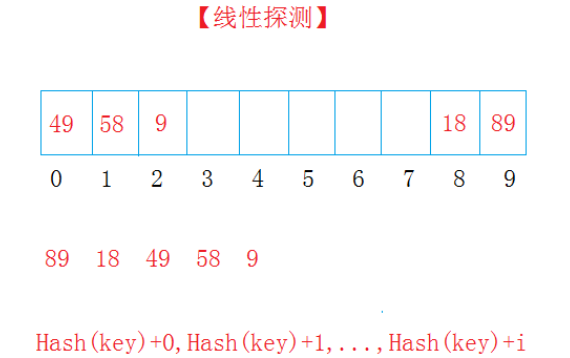
1)线性探测
若当前key与原来key产生相同的哈希地址,则当前key存在该地址之后没有存任何元素的地址中
key1:hash(key)+0
key2:hash(key)+1
key3:hash(key)+2
例如:
2)二次探测
若当前key与原来key产生相同的哈希地址,则当前key存在该地址后偏移量为(1,2,3...)的二次方地址处
key1:hash(key)+0
key2:hash(key)+1^2
key3:hash(key)+2^2
例如:

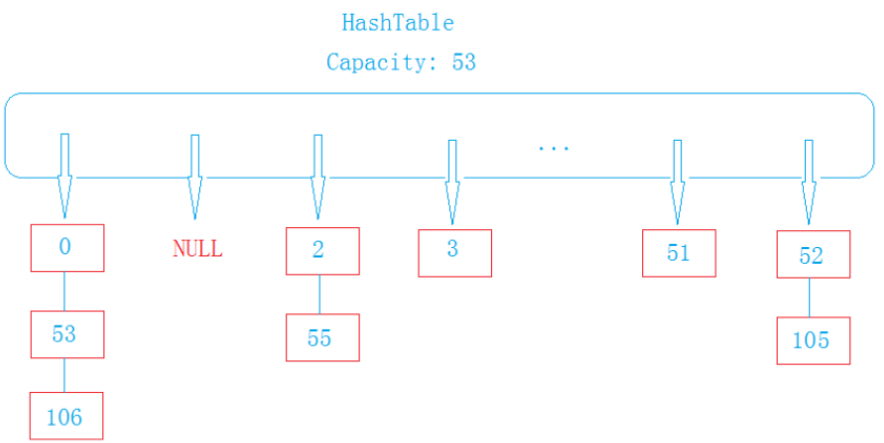
2.开链法(哈希桶)
哈希表中保存包含每个key值的节点,每个节点有一个_next的指针,指向产生哈希冲突的key的节点
例如:
具体实现方式请看下一篇博客,博客链接:
http://blog.csdn.net/xyzbaihaiping/article/details/51610944
构建哈希表(二次探测法)
支持key值为字符串
<pre name="code" class="cpp">//HashTable.h
#pragma once
#include<iostream>
#include <string>
using namespace std;
enum State
{
EMPTY,//空
EXITS,//存在
DELETE//已删除
};
template<class K, class V>
struct HashTableNode
{
K _key;
V _value;
};
template<class K>
struct _HashFunc
{
size_t operator()(const K& key,const size_t& capacity)//哈希函数,仿函数
{
return key / capacity;
}
};
template<>
struct _HashFunc<string>//模板特化
{
private:
unsigned int _BKDRHash(const char *str)//key为字符串时哈希函数
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
public:
size_t operator()(const string& key,const size_t& capacity)//仿函数
{
return _BKDRHash(key.c_str()) % capacity;
}
};
template<class K, class V,class HashFunc=_HashFunc<K>>
class HashTable
{
typedef HashTableNode<K, V> Node;
public:
HashTable(size_t capacity = 10)
:_tables(new Node[capacity])
, _states(new State[capacity])
, _size(0)
, _capacity(capacity)
{}
~HashTable()
{
if (_tables != NULL)
{
delete[] _tables;
delete[] _states;
}
}
HashTable(const HashTable<K, V>& ht)
{
HashTable<K, V> tmp(ht._capacity);
for (size_t i = 0; i < ht._capacity; i++)
{
tmp.Insert(ht._tables[i]._key, ht._tables[i]._value);
}
this->Swap(tmp);
}
HashTable& operator=(HashTable<K, V> ht)
{
this->Swap();
return *this;
}
bool Insert(const K& key, const V& value)
{
_CheckCapacity();
size_t index = HashFunc()(key, _capacity);
size_t i = 1;
while (_states[index] == EXITS)//二次探测
{
if (_tables[index]._key == key)
{
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
++i;
}
_tables[index]._key = key;
_tables[index]._value = value;
_states[index] = EXITS;
++_size;
return true;
}
bool Find(const K& key)
{
size_t index = HashFunc()(key, _capacity);
size_t start = index;
size_t i = 1;
while (_states[index] != EMPTY)//根据二次探测法查找
{
if (_tables[index]._key == key)
{
if (_states[index] != DELETE)
return true;
else
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
if (start == index)
return false;
}
return false;
}
bool Remove(const K& key)
{
size_t index = HashFunc()(key, _capacity);
size_t start = index;
size_t i = 1;
while (_states[index] != EMPTY)//根据二次探测法删除
{
if (_tables[index]._key == key)
{
if (_states[index] != DELETE)
{
_states[index] = DELETE;
_size--;
return true;
}
else
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
if (start == index)
return false;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _capacity; i++)
{
//printf("%d-[%s:%s] \n", _states[i], _tables[i]._key, _tables[i]._value);
cout << _states[i] << " " << _tables[i]._key << " " << _tables[i]._value<<endl;
}
}
private:
void Swap(HashTable<K, V>& tmp)
{
swap(_tables, tmp._tables);
swap(_states, tmp._states);
swap(_size, tmp._size);
swap(_capacity, tmp._capacity);
}
void _CheckCapacity()//增容
{
if (_size * 10 / _capacity == 6)
{
HashTable<K, V> tmp(_capacity * 2);
for (size_t i = 0; i < _capacity; i++)
{
if (_states[i] == EXITS)
tmp.Insert(_tables[i]._key, _tables[i]._value);
}
this->Swap(tmp);
}
}
private:
Node* _tables;//哈希表
State* _states;//状态表
size_t _size;
size_t _capacity;
};
</pre><pre code_snippet_id="1711228" snippet_file_name="blog_20160608_3_3809584" name="code" class="cpp">//test.cpp
#include<iostream>
#include "HashTable.h"
void testInt()
{
HashTable<int, int> table(10);
table.Insert(89, 89);
table.Insert(18, 18);
table.Insert(49, 49);
table.Insert(58, 58);
table.Insert(9, 9);
//table.Insert(45, 45);
//table.Insert(2, 2);
table.Print();
HashTable<int, int> table1(table);
table1.Print();
bool ret = table.Find(9);
cout << endl << ret << endl;
table.Remove(9);
table.Print();
}
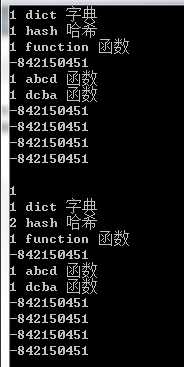
void TestString()
{
HashTable<string, string> table(10);
table.Insert("dict", "字典");
table.Insert("hash", "哈希");
table.Insert("function", "函数");
table.Insert("abcd", "函数");
table.Insert("dcba", "函数");
table.Print();
bool ret = table.Find("function");
cout << endl << ret << endl;
table.Remove("hash");
table.Print();
}
int main()
{
//testInt();
TestString();
getchar();
return 0;
}测试结果:

















 4963
4963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









