







【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
1 背景
这两天比较忙,各种锅锅接,忙里偷闲完结这一篇吧。在我们在上一篇《Python3.X 爬虫实战(先爬起来嗨)》中已经介绍了 Python 3 爬虫的基础知识,最后也通过了一个不是十分严谨的小爬虫程序展示了其强大的魅力。有人说上一篇《Python3.X 爬虫实战(先爬起来嗨)》中有强行安利 Python 的嫌疑,是的,名正言顺的安利,就是这么任性,总之这玩意对我来说在很多小工具上得到了效率的提升,确实好用,也有人问我最初因为什么机缘接触的 python,这里只能说以前做 Android 4.1 Framework 时差分包构建处理那块 Google 官方使用的是 Pyhton 脚本配合处理的,也算是工作需要被迫学习的吧,只是那时候没有 get 到 Python 的很多横向拓展,随着眼界的拓展,渐渐的就这么被俘获了。
言归正传,我们回到爬虫话题,上一篇我们最后总结了一个爬虫程序的流程,其中有两个核心的流程就是静态下载器(个人叫法,对立为动态网页下载处理,后面系列文章会介绍)和解析器,自然而然这一篇我们的核心就是探讨这两大步骤的选型。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
2 Python3 爬虫静态下载器
当我们通过调度器在 URL管理器中拿到一个 URL 以后要做的第一件事就是交给下载器进行 URL 所在链接的访问下载,而对于常规的 HTTP WEB 网页下载一般在短时间都能完成(想象下一个网页在浏览器等半天都打不开是一种啥体验),但是不排除网络异常、访问链接非法、WEB 站点服务器异常等情况,所以要实现一个相对比较健壮的下载器我们需要考虑的问题还有很多,关于细节逻辑优化和健壮性就得靠自己慢慢优化了。下面我们主要针对下载器进行一个简短的技术说明(关于这些 Python3 的模块详细用法自己可以额外学习)。
'''
如下是使用 Python3 内置模块实现的一个比上一篇稍微健壮一点点的下载器。
通过内置 urllib 进行 header 设置或者代理设置或者启用会话,支持简单的 HTTP CODE 5XX 重试机制,支持 GET\POST。
(实际项目考虑和封装的要比这更加健壮)
'''
from http import cookiejar
from urllib import request, error
from urllib.parse import urlparse
class HtmlDownLoader(object):
def download(self, url, retry_count=3, headers=None, proxy=None, data=None):
if url is None:
return None
try:
req = request.Request(url, headers=headers, data=data)
cookie = cookiejar.CookieJar()
cookie_process = request.HTTPCookieProcessor(cookie)
opener = request.build_opener()
if proxy:
proxies = {urlparse(url).scheme: proxy}
opener.add_handler(request.ProxyHandler(proxies))
content = opener.open(req).read()
except error.URLError as e:
print('HtmlDownLoader download error:', e.reason)
content = None
if retry_count > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
#说明是 HTTPError 错误且 HTTP CODE 为 5XX 范围说明是服务器错误,可以尝试再次下载
return self.download(url, retry_count-1, headers, proxy, data)
return content'''
如下是使用 Python3 外部模块 requests 实现的一个下载器
通过 header 设置或者代理设置、支持会话,支持简单的重试机制。
(实际项目考虑和封装的要比这更加健壮,安装模块使用命令:pip install requests)
'''
import requests
from requests import Timeout
'''
http://docs.python-requests.org/en/master/
'''
class Downloader(object):
def __init__(self):
self.request_session = requests.session()
self.request_session.proxies
def download(self, url, retry_count=3, headers=None, proxies=None, data=None):
'''
:param url: 准备下载的 URL 链接
:param retry_count: 如果 url 下载失败重试次数
:param headers: http header={'X':'x', 'X':'x'}
:param proxies: 代理设置 proxies={"https": "http://12.112.122.12:3212"}
:param data: 需要 urlencode(post_data) 的 POST 数据
:return: 网页内容或者 None
'''
if headers:
self.request_session.headers.update(headers)
try:
if data:
content = self.request_session.post(url, data, proxies=proxies).content
else:
content = self.request_session.get(url, proxies=proxies).content
except (ConnectionError, Timeout) as e:
print('Downloader download ConnectionError or Timeout:' + str(e))
content = None
if retry_count > 0:
self.download(url, retry_count - 1, headers, proxies, data)
except Exception as e:
print('Downloader download Exception:' + str(e))
content = None
return content怎么样,通过上面两段下载器代码我们可以发现一般 Python3 的网络请求(下载器)要么使用内部模块 urllib,要么使用外部模块 requests,但是达到的效果都是一样的,只是一个封装和便捷的关系。当然,你要是不喜欢这两个,自己也可以寻找使用其他开源的网络请求模块,达到目的就行,反正就是一个请求咯。
可以看到,通过静态下载器其实拿到的就是 URL 链接对应网站的静态内容(有些网页是静态的,有些是动态的),对于静态网页的爬虫其实我们这样通过下载器拿到的数据就够用了,对于动态网页我们后续文章再分析。鉴于此,我们接下来就该把静态下载器下载的页面内容交给解析器处理了。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
3 Python3 爬虫静态解析器
有了上一部分静态下载器下载下来的页面内容,我们紧接着要干的事情就是解析内容,也就是在这些页面中依据自己的规则抓取有价值的数据—–解析器。对于 Python 爬虫解析常用的套路主要有直接正则匹配、BeautifulSoup、LXml这几种(当然也有别的,只不过常用的主流就这几种),下面我们分别进行说明。
3-1 正则匹配解析器
顾名思义就是正则表达式匹配查找过滤了,如果你对正则表达式还不熟悉,建议你先看下以前我写的《正则表达式基础》一文,然后再来学习 Python3 正则匹配解析器,额,实质就是 Python 字符串正则匹配咯,再通俗点就是 Python 的 re 模块啦,在爬虫里使用 re 我们要注意如下几个套路:
在使用 Python re 正则模块时建议大家给正则字符串保持常加 r 前缀的习惯,避免因为转义带来坑爹的锅,因为正则本来就十分灵活,复杂一点就十分晦涩。
当我们使用 re.compile(exp_str) 方法时由于 re 内部会编译 exp_str 正则表达式是否合法,然后用编译过的表达式去匹配,而爬虫一般都是依据一个指定的正则表达式对成百上千的页面进行循环匹配,所以为了效率尽量将 re.compile(exp_str) 方法缓存起来,总之避免多次调用同样的,避免效率问题。
如《正则表达式基础》一文所示,尽量编写非贪婪模式的正则,默认是贪婪匹配的。
分组匹配输出时 re 的 group(x) 方法套路要谨防,group(0) 是原始字符串,group(1)、group(2) ……才是第 1、2、……个分组子串,切记套路。
编写正则时注意 re 的 compile(pattern, flags=0) 第二个参数含义,谨防套路,譬如我们想让 ‘.’ 在 DOTALL 模式下也能匹配 ‘\n’ ,就得注意将 flags 设置为 re.S 等。
如果你看了《正则表达式基础》一文明白了正则表达式但不会用 Python 的 re 模块的话建议再看看网上的 Python正则表达式指南。
不 BB 了,我们来看一个通过下载器下载下来静态页面内容后交给正则解析器处理的例子吧,下面是抓取解析 CSDN 我的博客评论管理列表中每个 item 的文章名字article、文章链接url、评论人名字commentator、评论时间time、评论内容content,然后生成一个字典列表保存解析的数据,要解析的网页内容如下:
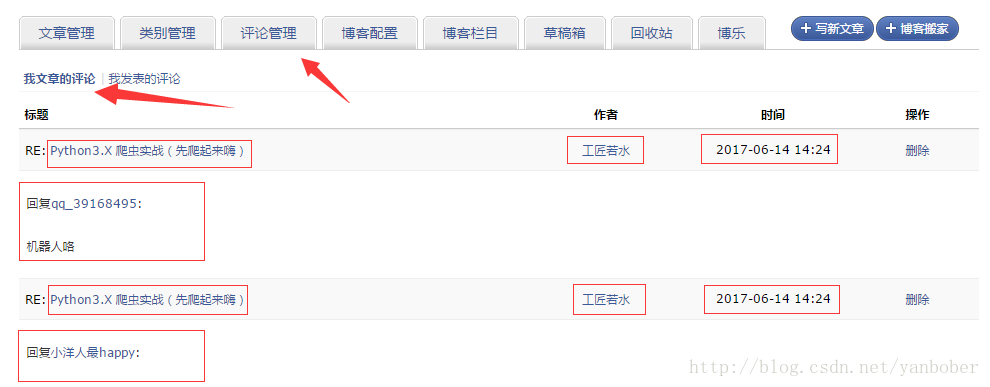
解析器代码如下 [该例子完整源码点我查看]:
def get_page_feedback_dict(self, page_index=1):
'''
获取CSDN我的博客页面的评论管理页面我文章的评论列表(按照评论页数获取)
:return: {'maxPage'100:, 'dict':[{'article':'xxx', 'url':'xxx', 'commentator':'xxx', 'time':'xxx', 'content':'xxx'}]}
'''
content = self.opener.open(self.url_feedback+str(page_index)).read().decode("utf-8")
print(content)
max_page = re.search(re.compile(r'<div class="page_nav"><span>.*?共(\d+)页</span>'), content).group(1)
reg_main = re.compile(r"<tr class='altitem'>.*?<a href='(.*?)'.*?>(.*?)</a></td><td><a.*?class='user_name' target=_blank>(.*?)</a></td><td>(.*?)</td>.*?<div class='recon'>(.*?)</div></td></tr>", re.S)
main_items = re.findall(reg_main, content)
dict_list = list()
for item in main_items:
dict_list.append({
'url': item[0],
'article': item[1],
'commentator': item[2],
'time': item[3],
'content': item[4]
})
print(str(dict_list))
return {'maxPage': max_page, 'dict': dict_list}获取到的 dict_list 解析后字典列表如下:
[
{
'url': 'http://blog.csdn.net/yanbober/article/details/73162298#comments',
'article': 'Python3.X 爬虫实战(先爬起来嗨)',
'commentator': 'yanbober',
'time': '2017-06-14 14:24',
'content': '[reply]qq_39168495[/reply]<br>机器人咯'
},
{
'url': 'http://blog.csdn.net/yanbober/article/details/73162298#comments',
'article': 'Python3.X 爬虫实战(先爬起来嗨)',
'commentator': 'yanbober',
'time': '2017-06-14 14:24',
'content': 'XXXXXXXXXXXX'
},
......
]如上就是一个通过 Python re 正则表达式编写的爬虫解析器,当然,这个不够健壮,实质需要将解析出来的数据再进行清洗使用,这里不再过多说明,不过可以看到直接使用正则匹配解析的代码是比较晦涩的,除过小型的爬虫以外不建议采用。
3-2 BeautifulSoup4 解析器
BB 完正则匹配解析器我们就可以长舒一口气了,毕竟大清都灭亡了,我们也要抛弃石器时代的解析器,拥抱 21 世纪的 BeautifulSoup4 解析器,关于这个外部神器模块我们可以参考官方网站或者官方中文文档学习。
安装该外部模块直接命令行执行:pip install beautifulsoup4
BeautifulSoup4 是一个工具箱,通过它解析文档可以为我们十分简单的提供需要抓取的数据;它自动会将我们输入的文档转换为 Unicode 编码,输出时转换为 UTF-8 编码,我们不用考虑操蛋的文本解析编码方式(除非文档没有指定编码方式,这种情况下 BeautifulSoup4 就没法自动识别编码方式了,我们需要主动说明下 WEB 页面原始编码方式就行了)。
BeautifulSoup4 除过支持 Python 标准库中的 HTML 解析器外还支持一些第三方解析器,譬如 LXml、html5lib 等(注意:设置不同解析器对于错误格式 WEB 页面解析可能会得到不一样的结果),想要使用这些第三方解析器就得自己先安装好,安装命令如下:
pip install lxml
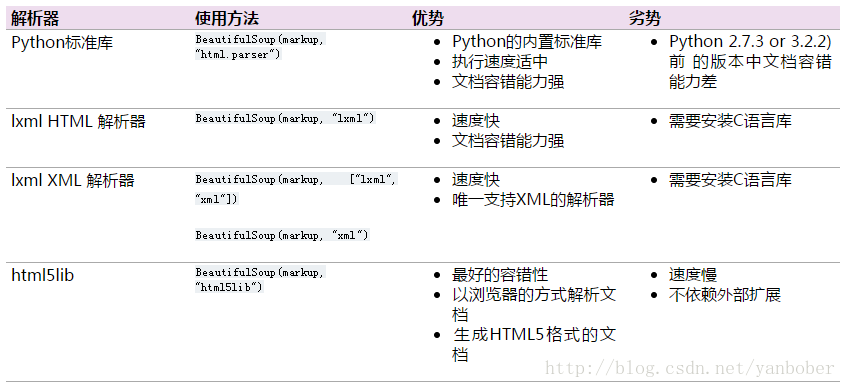
pip install html5lib不过依然推荐给 BeautifulSoup4 使用 LXml 作为解析器(解析效率高),下表列出了官方文档中主要的解析器优缺点(图片来自官方文档):
光说不练假把式,下面给出一个解析知乎登录页面 FORM 表单中的 _xsrf 和 captcha 链接供登录使用,下载器下载下来的待解析知乎登录界面如下:
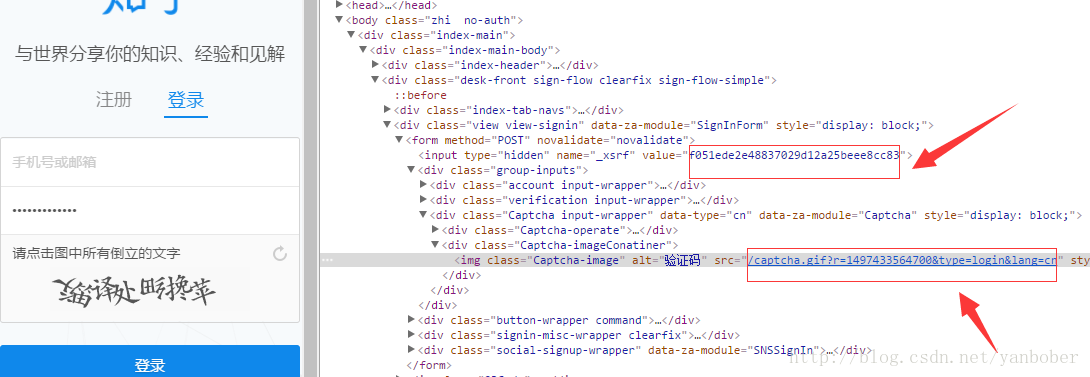
解析代码如下[该例子完整源码点我查看]:
def get_login_xsrf_and_captcha(self):
try:
url_login = "https://www.zhihu.com/#signin"
url_captcha = 'http://www.zhihu.com/captcha.gif?r=%d&type=login&lang=cn' % (time.time() * 1000)
login_content = self.request_session.get(url_login).content
soup = BeautifulSoup(login_content, 'lxml')
#find 方法第二个参数还可以是 python 编译的正则表达式
#譬如soup.find_all("a", href=re.compile(r"/item/\w+"))
xsrf = soup.find('input', attrs={'name': '_xsrf'})['value']
captcha_content = self.request_session.get(url_captcha).content
return {'xsrf': xsrf, 'captcha_content': captcha_content}
except Exception as e:
print('get login xsrf and captcha failed!'+str(e))
return dict()怎么样,比起正则匹配是不是可读性好了很多,至少不那么晦涩难懂和容易坑自己了,而且效率还比正则高,有没有瞬间感觉从石器时代到了智能时代;对于 BeautifulSoup4 工具包提供的函数不熟悉没关系,自己记得常常查阅他们官方中文文档就行了,你要感觉到庆幸,他们文档是十分精炼简洁的。
3-3 LXml 解析器
进入智能时代以后还有个更牛逼的解析器 ——– LXml,名副其实的屌炸天,关于它可以参见官方文档,这货使用 C 语言编写,解析速度比 BeautifulSoup 更快;上面已经介绍了把 LXml 作为 BeautifulSoup 内置解析器的 BeautifulSoup 用法,这里我们直接给出一个用 LXml 使用 XPath 选择器和内置方法的用法实战说明这个灵活牛叉的解析器,关于细节基础知识不在本系列讨论范围之内,可查看参阅官方文档等。
我们以爬取 https://www.meitulu.com/ 美图录网站为例说明,首先要解析的就是主页的推荐模特列表点击跳转的二级链接(下面的 parse_main_subjects 函数,也即下图中 class=”img” 的 ul 中 li 下的 a 标签的 href 链接)如下:
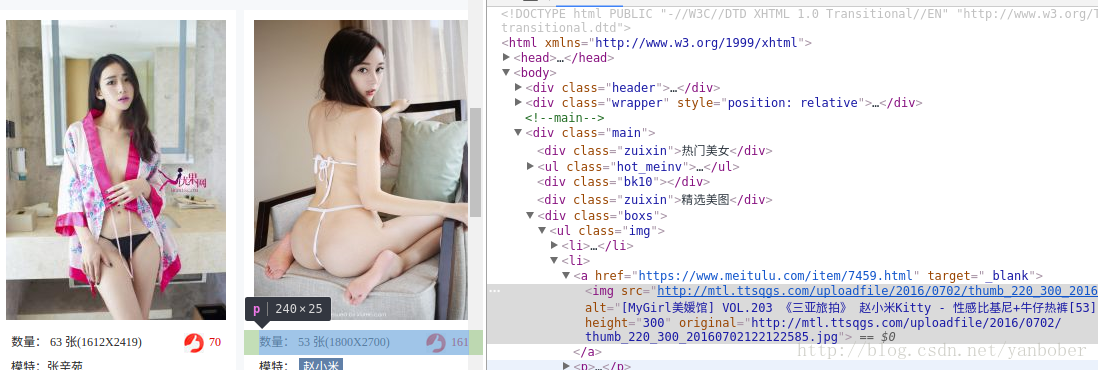
接着解析进入二级页面(模特大图列表页,其页面第一页为DDD.html、其他页规则为 DDD_index.html),我们解析了这个模特的名字和总共具备多少张照片,然后一页一页解析他们的高清大图下载链接。
解析代码如下[该例子完整源码点我查看]:
class HtmlParser(object):
def parse_main_subjects(self, content):
'''
解析美图录网站主页模特分类页面链接
:param content: 美图录主页内容
:return: ['一个模特的大图页面', '一个模特的大图页面']
'''
html = etree.HTML(content.lower())
subject = html.xpath('//ul[@class="img"]/li')
subject_urls = list()
for sub in subject:
a_href = sub[0].get('href')
subject_urls.append(a_href)
return subject_urls
def parse_subject_mj_info(self, content):
'''
获取具体模特大图页面开头的模特信息
:param content: 一个类别的模特页面内容
:return: {'count': 该模特具备图总数, 'mj_name': 模特名字}
'''
html = etree.HTML(content.lower())
div_cl = html.xpath('//div[@class="c_l"]')
pic_count = re.search(re.compile(r'.*?(\d+).*?'), div_cl[0][2].text).group(1)
return {'count': pic_count, 'mj_name': div_cl[0][4].text}
def parse_page_pics(self, content):
'''
获取一个模特页面的模特大图下载链接
:param content: 一个类别的模特页面内容
:return: ['大图链接', '大图链接']
'''
html = etree.HTML(content.lower())
return html.xpath('//div[@class="content"]/center/img/@src')[该例子完整源码点我查看],其解析器完全使用了 LXml 和 XPath 语法,它就会帮我们从美图录网站主页进去挨个推荐模特二级页面依次自动爬取大图(只爬高清大图)下载,log 如下:

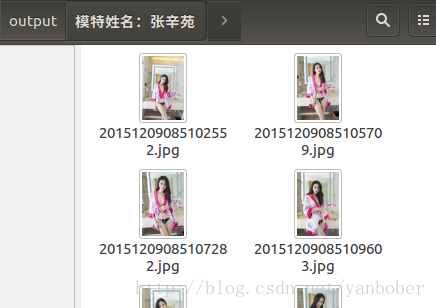
生成的爬取资源如下(依据模特名字命名目录存起来,已经爬取下载过的就不下载了):
如果看了上面例子还是搞不懂 LXml 的话可以建议你先看下网络上的Python lxml教程一文,然后再去看看官方文档就明白了,不过还是一句话,多练即可,实战几把你就秒懂了。
【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】
4 总结
这一篇内容主要延续上一篇《Python3.X 爬虫实战(先爬起来嗨)》,重点偏向于爬虫爬取静态页面的下载器与解析器常用套路引导,主要适用于理解爬虫流程和自己编写小爬虫程序,对于大型爬虫这些介绍是十分不健壮的,我们一般会采用第三方爬虫框架,对于框架和动态页面爬取我们后面系列会进行介绍的。
关于本篇完整实例源码参见AndroidSpider 、ZhiHuSpider、CsdnDiscussSpider、MeiTuLuSpider。
wocao!震惊!竟然忘了这么晚了。。。。。明天还有事。。。。
^-^当然咯,看到这如果发现对您有帮助的话不妨扫描二维码赏点买羽毛球的小钱(现在球也挺贵的),既是一种鼓励也是一种分享,谢谢!

【工匠若水 http://blog.csdn.net/yanbober 未经允许严禁转载,请尊重作者劳动成果。私信联系我】


















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











