









今天重新看数据结构与算法,对其有了新的认识。首先什么是数据结构呢?什么是数据结构研究的对象呢?下面引用几个概念,希望有助于对数据结构的理解。A data structureis an arrangement of data in a computer’s memory (or sometimes on a disk). Datastructures include arrays, linked lists, stacks, binary trees, and hash tables,amongothers. Algorithms manipulate the data in these structures in various ways, suchas searching for a particular data item and sorting the data.(《DATA STURCTURES & ALGORITHMS IN JAVA SECOND EDITION》,翻译为《数据结构与算法(JAVA语言描述)》)。在耿国华主编《数据结构-C语言描述》给出的定义为:按某种逻辑关系组织起来的一批数据,按照一定的映像方式把他们存放在计算机的存储器中,并在这些数据上定义一个运算的集合,就叫做数据结构。从上面的定义,不难看出数据结构是指相互之间存在一种或多种特定关系的数据元素集合。数据元素之间的相互关系具体包括:数据的逻辑结构,数据的物理结构,数据的运算集合。换句话说,数据结构主要研究怎样合理地组织数据、建立合适的结构、提高执行程序的时空效率。下面分别对3中简单排序进行介绍,部分内容引用了《DATA STURCTURES & ALGORITHMS IN JAVA SECOND EITION》中的例子和图。
1 冒泡排序Bubble Sort
冒泡排序是重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(引用自“维基百科”)。
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
下图可以形象的说明这个过程:

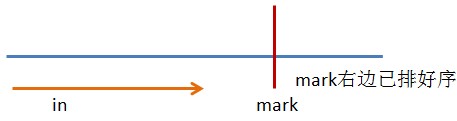
// bubbleSort
class Bubble{
private int[] sortedsortedArrayay=null;
//constructor
public Bubble(){
}
//bubble sort
public int[] bubbleSort(int[] arr) throws Exception {
this.sortedArray=arr;
// 输入控制
if (sortedArray == null)
throw new Exception("input sortedArrayay cannot be null");
if (sortedArray.length == 1)
return sortedArray; // if have only one element
// bubble从左向右(in)到mark比较;mark的右边是已经排好序的
int in, mark;
for (mark = sortedArray.length - 1; mark >= 1; mark--) { // 当只有一个元素时,不需要比较了,所以mark>=1
for (in = 0; in <=mark-1; in++) { //因为bubble+1=mark,所以循环截止是mark-1
if (sortedArray[in] > sortedArray[in + 1])
swap(in,in+1);
}//end for
}//end for
return sortedArray;
} //end bubbleSort()
//swap two numbers
private void swap(int one, int two){ //注意基本类型是值传递
long temp = sortedArray[one];
sortedArray[one] = sortedArray[two];
sortedArray[two] = temp;
} //end swap()
} //end class算法复杂度:
冒泡排序比较(comparison)次数为O(n^2),交换(swap)数据次数为O(n^2),算法复杂度0(n^2)。
N个元素,第一次需要比较N-1次,第二次需要比较N-2次....,共需比较次数为
(N-1)+(N-2)+...+1=N*(N-1)/2
交换次数最坏情况下每次比较都需要交换,所以交换次数与比较次数相同。
2 选择排序 Selection Sort
选择排序也称查询排序。每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。 下图是选出最小元素进行排序的过程。图中红色mark、select、min分别对应代码中的变量名。

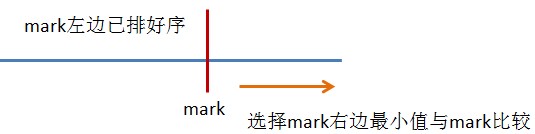
class SelectSort{
//选择排序
// 1 mark 左边的元素时排好序的,mark范围为[0,(arr.length-1)-1],因为至少保证其右边有一个元素用于与mark比较
// 2 找最小元素:找到mark及其右边元素的最小值
// 3 与mark交换
private int[] sortedArray=null;
//constructor
public Bubble(){
}
// select sort
public int[] select(int[] arr) throws Exception {
sortedArray=arr;
// 输入控制
if (sortedArray == null)
throw new Exception("input array cannot be null");
if (sortedArray.length == 1)
return sortedArray; // if have only one element
int mark, min;
for (mark = 0; mark <= sortedArray.length - 2; mark++) {
min = mark;
for (int select = mark + 1; select <= sortedArray.length - 1; select++) {
if (sortedArray[min] > sortedArray[select])
min = select;
}// end for
swap(mark, min);
}// end for
return sortedArray;
} //end select()
//swap two numbers
private void swap(int one, int two){ //注意基本类型是值传递
long temp = sortedArray[one];
sortedArray[one] = sortedArray[two];
sortedArray[two] = temp;
} //end swap()
} //end class SelectSort 算法复杂度
比较次数O(n^2),交换数据次数O(n)。
最好情况是,已经有序,交换0次;最坏情况是,逆序,交换n-1次。 交换次数比冒泡排序少多了,由于交换所需CPU时间比所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
3 插入排序Insertion Sort
插入排序是将一个数据元素插入到已排好序的有序表中。以下图中的球员代表数据,主要操作有:
1、标记球员(对应代码中的mark)。如图a中的“marked paler”,标记球员左边的球员都已排好序。
2、将标记球员保存到临时变量(对应代码中的temp)中,目的是将标记球员中的位置空出来,如图中b。
3、比较并插入标记球员(对应代码中的insert)。将标记球员与其左边的球员比较,向右移动比标记球员大的球员,直到移动了最好一个比标记球员大的球员,然后插入标记球员。如图c

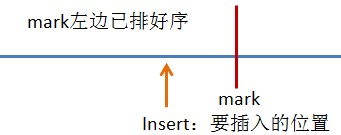
伪代码:
for i=[1,n)
temp=x[i]
for(j=i;j>0;j--){
if(x[j-1]>temp;j--)
x[j]=x[j-1]
}//end for
x[j]=t
}//end for下面是java代码实现Inserting Sort:
Class InsertSort{
//插入排序
public int[] sort(int[] arr)throws Exception {
// 输入控制
if (arr == null)
throw new Exception("input array cannot be null");
if (arr.length == 1)
return arr; // if have only one element
int insert,mark; //mark标记,insert要插入的位置
for(mark=1;mark<arr.length;mark++){
int temp=arr[mark]; //腾出标记元素位置
for(insert=mark-1;insert>=0;insert--){
if(arr[insert]>temp)
arr[insert+1]=arr[insert];
else
break; //循环结束条件:找到mark前面第一个比它小的数则跳出循环,并在该处插入标记元素
}//end for
//插入
arr[insert]=temp;
}//end for
return arr;
}//end insertSort()
}//end class InsertSort时间复杂度:
插入排序主要操作是比较和移动。
最坏情况,数组是倒序排序,比较次数1+2+...+(n-1)=O(n^2),移动次数也一样。平均来说插入排序算法复杂度为O(n2)。
由于移动操作所需CPU时间比交换(swap time)所需CPU时间少,所以一般情况下,插入排序速度比查询排序快。
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。因而,插入排序不适合对于数据量比较大的排序应用。
但是,如果需要排序的数据量很小,例如,量级小于千,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
4 排序算法比较
When to Use What Data Structures
五、简单排序的人生哲理
从插入排序中影藏了一个社会常见的现象。下图中mark(图中画方框处)为新入职的员工,mark前面排好序的是根据个人能力员工所处的职位,老板会根据新入职的员工的表现及能力选择合适的职位安排给该员工。能力越强的人就会安排到更高的职位,不然就会成为像电视剧《浮沉》中所说的“炮灰”。
















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









