









1 Overview
We can divide data structures into the following types:

2 General-purpose data structures
We call these general-purpose data structures because they are used to store and retrieve data using key values. This works for general-purpose database programs (as opposed to specialized structures such as stacks, which allow access to only certain data items).
Which of these general-purpose data structures is appropriate for a given problem? Figure 15.1 shows a first approximation to this question. However, there are many factors besides those shown in the figure.

The general-purpose data structures can be roughly arranged in terms of speed: Arrays and linked lists are slow, trees are fairly fast, and hash tables are very fast.

We usually start by considering the simple data structures. Unless it’s obvious they’ll be too slow, code a simple version of an array or linked list and see what happens. If it
runs in acceptable time, look no further. Why slave away on a balanced tree when no one would ever notice if you used an array instead? Even if you must deal with thousands or tens of thousands of items, it’s still worthwhile to see how well an array or linked list will handle them. Only when experimentation shows their performance to be too slow should you revert to more sophisticated data structures.
2.1 Arrays
Arrays are useful when
• The amount of data is reasonably small.
• The amount of data is predictable in advance.
If insertion speed is important, use an unordered array. If search speed is important, use an ordered array with a binary search. Deletion is always slow in arrays because
an average of half the items must be moved to fill in the newly vacated cell. Traversal is fast in an ordered array but not supported in an unordered array.
2.2 Linked List
Consider a linked list whenever the amount of data to be stored cannot be predicted in advance or when data will frequently be inserted and deleted.
2.3 Trees
2.3.1 Binary Search Trees
A binary tree is the first structure to consider when arrays and linked lists prove too slow. A tree provides fast O(logN) insertion, searching, and deletion. Traversal is O(N), which is the maximum for any data structure (by definition, you must visit every item). You can also find the minimum and maximum quickly and traverse a range of items.
An unbalanced binary tree is much easier to program than a balanced tree, but unfortunately ordered data can reduce its performance to O(N) time, no better than a linked list. However, if you’re sure the data will arrive in random order, there’s no point using a balanced tree.
The algorithm of binary tree can be found in my following blogs.
binary tree, traverse binary tree, the depth of binary tree,balanced tree.
2.3.2 Balanced Trees
Of the various kinds of balanced trees, we discussed red-black trees and 2-3-4 trees. They are both balanced trees, and thus guarantee O(logN) performance whether the
input data is ordered or not.
my blog: balanced binary search tree.
2.4 Hash Tables
Hash tables are the fastest data storage structure.the data. Hash tables are typically used in spelling checkers and as symbol tables in computer language compilers, where a program must check thousands of words or symbols in a fraction of a second.
1) Hash tables are not sensitive to the order in which data is inserted, and so can take the place of a balanced tree.
Hash tables don’t support any kind of ordered traversal, or access to the minimum or maximum items. If these capabilities are important, the binary search tree is a better choice.
2) Hash tables require additional memory, especially for open addressing. Also, the amount of data to be stored must be known fairly accurately in advance, because an array is used as the underlying structure.
my blog: Hash Tables
2.5 Comparing the General-Purpose Storage Structures

the — means this operation is not supported.
3 Special-Purpose Data Structures
The special-purpose data structures discussed in here are the stack, the queue, and the priority queue. These structures, rather than supporting a database of user-accessible
data, are usually used by a computer program to aid in carrying out some algorithm. For example stacks, queues, and priority queues are all used in graph algorithms.
Stacks, queues, and priority queues are Abstract Data Types (ADTs) that are implemented by a more fundamental structure such as an array, linked list, or (in the case of the priority queue) a heap. These ADTs present a simple interface to the user, typically allowing only insertion and the ability to access or delete only one data item.
These items are
• For stacks: the last item inserted,it’s a Last-In-First-Out (LIFO) structure.
• For queues: the first item inserted, it’s a First-In-First-Out (FIFO) structure.
• For priority queues: the item with the highest priority
These ADTs can’t be conveniently searched for an item by key value or traversed.
3.1 Stack
A stack is often implemented as an array or a linked list.
The array implementation is efficient because the most recently inserted item is placed at the end of the array, where it’s also easy to delete. Stack overflow can occur, but is not likely if the array is reasonably sized, because stacks seldom contain huge amounts of data.
If the stack will contain a lot of data and the amount can’t be predicted accurately in advance (as when recursion is implemented as a stack), a linked list is a better choice than an array. A linked list is efficient because items can be inserted and deleted quickly from the head of the list. Stack overflow can’t occur (unless the entire memory is full). A linked list is slightly slower than an array because memory allocation is necessary to create a new link for insertion, and deallocation of the link is necessary at some point following removal of an item from the list.
3.2 Queue
Like stacks, queues can be implemented as arrays or linked lists. Both are efficient. The array requires additional programming to handle the situation in which the queue wraps around at the end of the array. A linked list must be double-ended, to allow insertions at one end and deletions at the other.
As with stacks, the choice between an array implementation and a linked list implementation is determined by how well the amount of data can be predicted. Use the array if you know about how much data there will be; otherwise, use a linked list.
3.3 Priority Queue
A priority queue is used when the only access desired is to the data item with the highest priority. This is the item with the largest (or sometimes the smallest) key.
Priority queues can be implemented as an ordered array or as a heap, and priority queues usually implemented as a heap. Insertion into an ordered array is slow, but deletion is fast. With the heap implementation, both insertion and deletion take O(logN) time.
3.4 Comparison of Special-Purpose Structures

4 Sorting
Insertion sort is also good for almost-sorted files, operating in about O(N) time if not too many items are out of place. This is typically the case where a few new items are
added to an already-sorted file.
If the insertion sort proves too slow, then the Shellsort is the next candidate. It’s fairly easy to implement, and not very temperamental. Sedgewick estimates it to be useful up to 5,000 items.
Only when the Shellsort proves too slow should you use one of the more complex but faster sorts: mergesort, heapsort, or quicksort. Mergesort requires extra memory,
heapsort requires a heap data structure, and both are somewhat slower than quicksort, so quicksort is the usual choice when the fastest sorting time is necessary.
However, quicksort is suspect if there’s a danger that the data may not be random, in which case it may deteriorate to O(N2) performance. For potentially non-random data, heapsort is better. For example, if there is items group which has 1000 items,and there are new items to add to this items group in the future, and we must sort all the items in this items group. If we use quicksort to sort, at first, the first 1000 items can sort in O(N*logN) time, but when there arenew items add to the items group, all the items are almost sorted(non-random), the later sort, heapsort is better.
Comparison of Sorting Algorithms
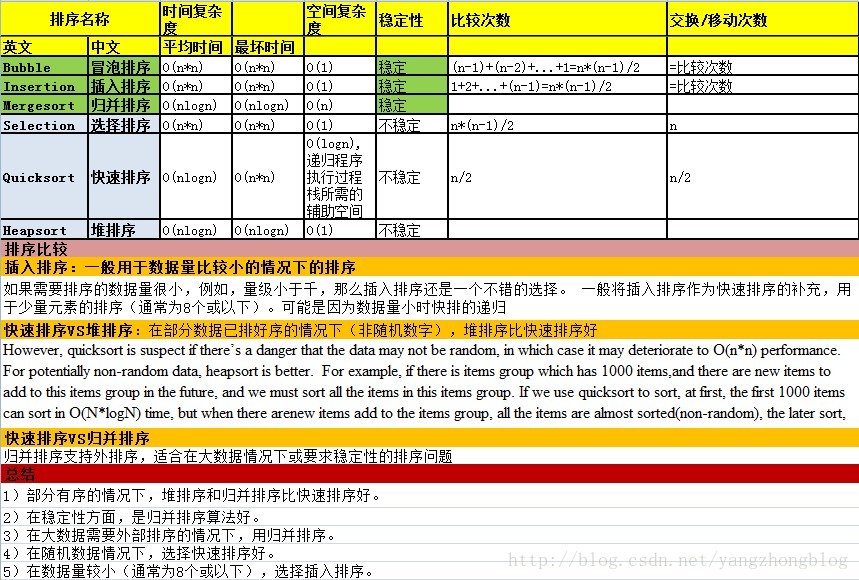
The detail content of sort algorithms can be found in my following blogs.
基本排序算法 ,快速排序,合并排序:数组和单链表,外排序,外排序,大数据排序问题,堆排序
5 Graphs
Graphs are unique in the pantheon of data storage structures. They don’t store general-purpose data, and they don’t act as programmer’s tools for use in other algorithms.
Instead, they directly model real-world situations. The structure of the graph reflects the structure of the problem.
When you need a graph, nothing else will do, so there’s no decision to be made about when to use one.The primary choice is how to represent the graph: using an adjacency matrix or adjacency lists. Your choice depends on whether the graph is full, when the adjacency matrix is preferred, or sparse, when the adjacency list should be used.
The depth-first search(uses a stack) and breadth-first search run in time, where V is the number of vertices, for adjacency matrix representation.They run in O(V+E) time, where E is the number of edges, for adjacency list representation. Minimum spanning trees and shortest paths run in time using an adjacency matrix and O((E+V)logV) time using adjacency lists. You’ll need to estimate V and E for your graph and do the arithmetic to see which representation is appropriate.
time, where V is the number of vertices, for adjacency matrix representation.They run in O(V+E) time, where E is the number of edges, for adjacency list representation. Minimum spanning trees and shortest paths run in time using an adjacency matrix and O((E+V)logV) time using adjacency lists. You’ll need to estimate V and E for your graph and do the arithmetic to see which representation is appropriate.
The detail content of garphs algorithms can be found in my following blogs.
图的表示方法,图遍历:深度优先搜索和广度优先搜索,图经典算法:最小生成树,有向图的拓展排序,最短路径。
6 External Storage
In the previous discussion we assumed that data was stored in main memory. However, amounts of data too large to store in memory must be stored in external storage, which generally means disk files.
We assumed that data is stored in a disk file in fixed-size units called blocks, each of which holds a number of records. (A record in a disk file holds the same sort of data
as an object in main memory.) Like an object, a record has a key value used to access it.
We also assumed that reading and writing operations always involve a single block, and these read and write operations are far more time-consuming than any processing
of data in main memory. Thus, for fast operation the number of disk accesses must be minimized.
6.1 Sequential Storage
The simplest approach is to store records randomly and read them sequentially when searching for one with a particular key. New records can simply be inserted at the
end of the file. Deleted records can be marked as deleted, or records can be shifted down (as in an array) to fill in the gap.
6.2 Indexed Files
Speed is increased dramatically when indexed files are used. In this scheme an index of keys and corresponding block numbers is kept in main memory. To access a record with a specified key, the index is consulted. It supplies the block number for the key, and only one block needs to be read, taking O(1) time.
Several indices with different kinds of keys can be used (one for last names, one for Social Security numbers, and so on). This scheme works well until the index becomes
too large to fit in memory.
Typically, the index files are themselves stored on disk and read into memory as needed.
The disadvantage of indexed files is that at some point the index must be created. This probably involves reading through the file sequentially, so creating the index is
slow. Also, the index will need to be updated when items are added to the file.
6.3 B-trees
B-trees are multiway trees, commonly used in external storage, in which nodes correspond to blocks on the disk. As in other trees, the algorithms find their way down
the tree, reading one block at each level. B-trees provide searching, insertion, and deletion of records in O(logN) time. This is quite fast and works even for very large
files. However, the programming is not trivial.
6.4 Hashing
If it’s acceptable to use about twice as much external storage as a file would normally take, then external hashing might be a good choice. It has the same access time as
indexed files, O(1), but can handle larger files.
6.5 Relationship of external storage choices

6.6 Virtual Memory
Sometimes you can let your operating system’s virtual memory capabilities (if it has them) solve disk access problems with little programming effort on your part.
If you read a file that’s too big to fit in main memory, the virtual memory system will read in that part of the file that fits and store the rest on the disk. As you access different parts of the file, they will be read from the disk automatically and placed in memory.
You can apply internal algorithms to the entire file just as if it was all in memory at the same time, and let the operating system worry about reading the appropriate part of the file if it isn’t in memory already.
Of course, operation will be much slower than when the entire file is in memory, but this would also be true if you dealt with the file block by block using one of the external-storage algorithms. It may be worth simply ignoring the fact that a file doesn’t fit in memory and seeing how well your algorithms work with the help of virtual memory. Especially for files that aren’t much larger than the available memory, this may be an easy solution.
Reference
Data.Structures.and.Algorithms.in.Java,(Robert Lafore).2nd.Ed















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









