







引言
试想有这样一个问题,有一个长度为N的字符串A(N值很大),还有一个模式串B,B的长度为M(N/M很大,说明B只是一个小片段),此时需要判断B是否是A的字串。如果我们使用KMP算法的话,那么复杂度为O(N),对A串进行K次模式匹配的话就是KO(N),此时为了降低复杂度,我们可以考虑预处理长字符串A,是的,如果我们预先处理好A的后缀树,那么搜索子串的复杂度就降为O(M),进行K次匹配为KO(M),和原来相比,效率大大提高。那么预处理字符串A的复杂度为多少呢?使用Ukkonen的算法,它的时间和空间复杂度都为O(N),这就像是做了一件一劳永逸的事情一样,一次预处理,多次使用。或许你已经猜到了,我描述的问题就是DNA序列的匹配。
后缀树(Suffix Tree)
一个长度为n的字符串S,它的后缀树是一棵满足以下条件的树:
- 每条边都代表一个非空字符串;
- 所有的内部结点(根节点除外)都至少有2个子节点(数据压缩)
- 有n个叶子节点,且从根到叶子的路径表示了一个唯一的后缀(前提是字符串s的最后一位字符时字典中唯一存在的,显而易见S的不同后缀有n个)。
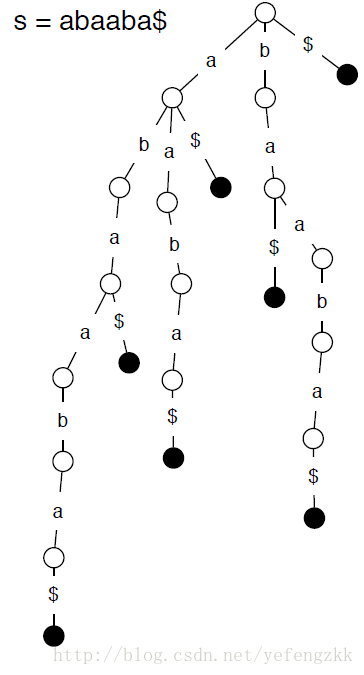
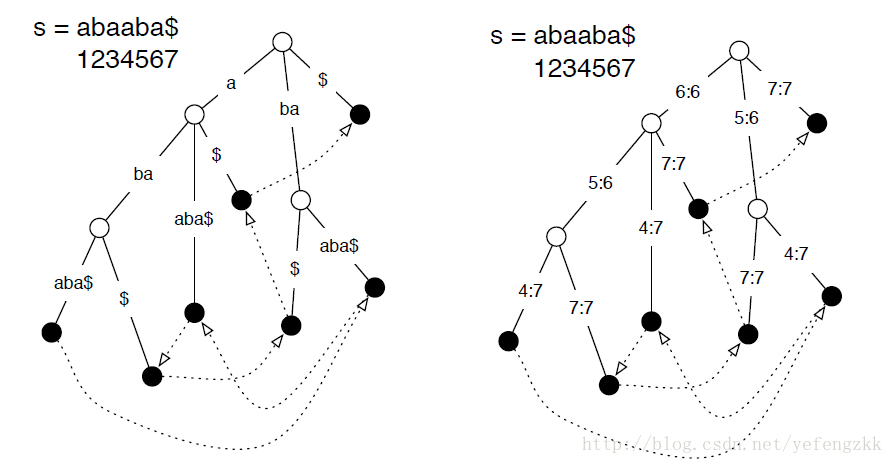
其实suffix trie和suffix tree仅仅差一步之遥。从图中我们可以看到每一条边仅表示一个字符,这样列出所有后缀需要的节点数为(1+2+...+n),空间复杂度为O(N2)。这样对于长字符串(比如基因序列),我们就不可忍了。仔细观察后缀字典树的结构,我们会发现很多路径都没有分支了,既然没有分支,那么我们就可以把它们集合在一起(数据压缩),这样每条路径表示的就不是一个字符了,而是一个字符序列,可以用字符串中的索引值表示。














 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









