







通常情况下,通过对运行时log的分析基本上可以定位一些bug,但是在一些特殊的环境下,分析log并不是一个有效的方法。
拿我最近遇见的情况来说,一些跑稳定性的设备在运行多日后三台设备出现了一些异常,粗略估计是因为某个管理资源的状态机出了异常。
但是因为这个状态机触发频率高,所以并未留下足够分析的log,同时这个bug再现率非常低,对一台设备进行了配置修改操作,一台加了对应的log重新升级之后数日都无法复现。
所以唯一的办法就是获取设备异常时相关线程的栈信息,也即通过人工给进程发送11或者6号信号,使进程挂掉,然后dump出所有信息找到相关线程分析栈。
下面是具体的操作步骤,在以下操作中确保已经配置好core文件的生成环境。
1,ps找到相关进程的进程号,直接使用出问题的线程对应的内核线程的线程号也可。
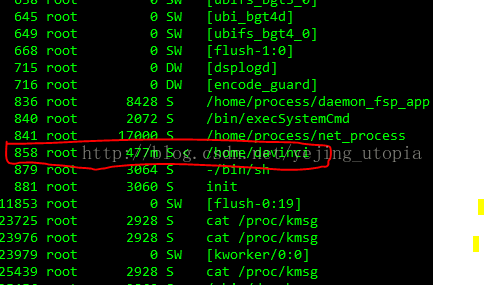
上面的操作中找到了相关的pid
然后执行kill操作:

查看进程状态可以发现kill的进程已经死掉,在core文件生成过程中维持D状态,生成之后进程退出,无法查找。
同时查看core文件生成情况。
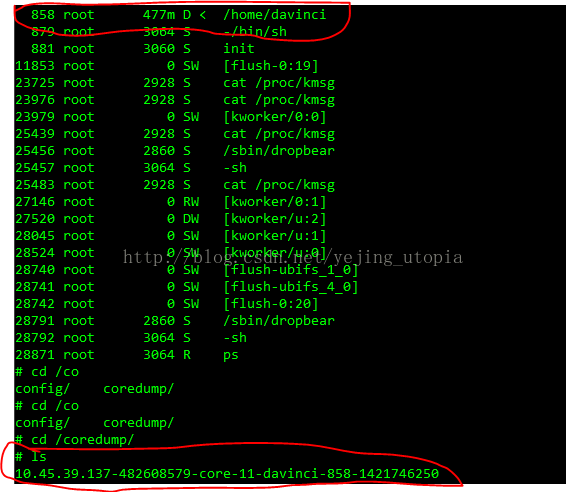
上图中可以看到进程已经D了,然后也生成了core文件,将core文件取出,使用对应的-gelf就可以直接用gdb调试了。
对于debug死锁之类的问题有奇效。















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









