







ElasticSearch(简称ES)是一个基于Lucene构建的开源(open-source),分布式(distributed),RESTful,实时(real-time)的搜索与分析(analytics)引擎。
一一拆分定义:基于Lucene,那就需要我们要提前了解好Lucene的相关知识(Lucene原理分析);分布式的,分片原理是分布式的基础;RESTFul,说明我们对ElasticSearch的调用是通过http RESTFul格式的;实时,说明搜索效率高;搜索与分析,说明不仅只提供单独的反向索引功能,同时还具备简单的分析能力。
ElasticSearch也引入了集群和节点的概念,默认集群名是“elasticsearch”,默认随机给个节点名称,每个节点必须属于某一个集群,而默认每个节点的集群名又是“elasticsearch”。
在ElasticSearch中同一集群下的所有node要有一个管事的,叫做master,master掌管着创建删除索引,对于document级别的操作所有node都是平级的。
索引(index):
ElasticSearch是基于Lucene实现的,所以这里的索引跟Lucene中的索引定义一样,但是一个索引在物理上可以落到多个节点中。
类型(type):
ElasticSearch区别于Lucene的定义,一个索引可以定义一种或多种类型,我们往往将索引中具有共同特性的内容从逻辑上分类定义成一个类型。例如网购中会员信息是一个分类、订单信息是一个分类、商品信息又是一个分类。
文档(document):
同Lucene中的定义,被索引的内容。
ElasticSearch的分布式特性:分片和复制
分片:一个索引会被划分为多份分片,当创建一个索引的时候可以指定想要分片的数量,每个分片本身也是一个独立的“子索引”,这个“子索引”可以被放置到集群中的任何节点上。
分片的意义在于:
第一, 从存储能力的角度上来讲方便水平扩容。
第二, 每个分片的独立性决定了运算能力上可以进行分布式的、并行的操作,进而提高吞吐量。
第三, 方便索引按片进行复制和搬运。
复制:在创建索引时ElasticSearch允许创建分片的一份或者多份拷贝作为复制,从定义中可以看得出复制本身也是一个分片,具有独立的索引能力。
复制的意义在于:
第一:在“正牌”分片失败的情况下提高了高可用性,前提是我们在设计阶段“正牌”和“复制”分片需要划分在不同节点。
第二:复制分片可以提供“只读”服务,复制分片也就提高了搜索的并发能力。
(其实分片设计也不是什么新东西,从我们的知识库中可以拿出不少这种类似的设计,Kafka、HBase、Redis等,存储上利用分片复制,管理上利用元数据,可以说分片+元数据基本玩转所有分布式组件了,只是细节上存在差异。)
在ElasticSearch中分片分为两类:primary shard和replica shard。Primary shard就是将一个索引分为多少片就有多少primary shard,每个primary shard都具备独立提供服务的能力。Replica shard就是前面说的复制,每一个primary shard可以有一到多个Replica shard。
为了保证对同一个Document的操作都要落到同一个primary shard上,所以elastic search在索引前都会对documentID做Hash的,也正是这个原理决定了primary shard一旦划分好就不允许更改数量。Replica shard可以随意添加。
唠叨这么多干巴巴的理论,下面开始上图上例子:
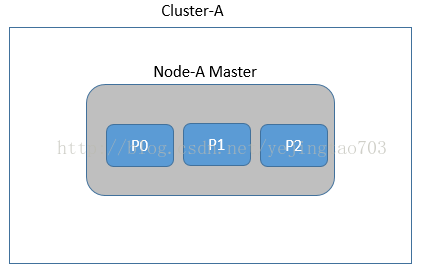
1, 启动一个节点Node-A,结点属于cluster-A,由于custer-A只有这一个节点所以Node-A成为了管理索引的master。创建了一个索引,划分成3个分片P0、P1、P2,由于只有一个Node,所以没有replica shard,没有意义。
2, 节点扩展到3个,每个分片做一份备份,效果如下

每个Node上各有2个分片,而且其中任何一个Node宕机都不会影响012三个分区提供服务,可以充分利用每个Node的CPU、内存和IO,同时保证了高可用性.
3, 每个分片做两份备份,效果如下:
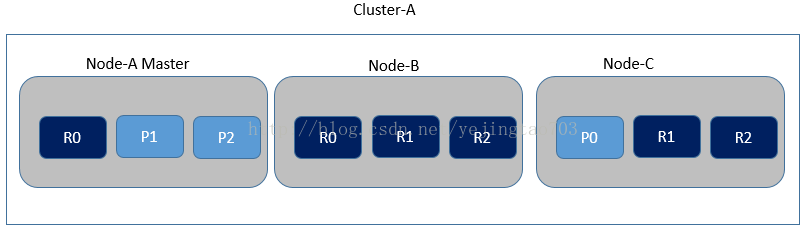
每个Node上有3个分片,比起2个分片理论上性能又提高了50%,当两台Node宕机时仍能提供服务.
4, 如果我们给Node-A下电,因为必须要有个Node来做Master做索引的增删,所以Node-B或Node-C会有一个成为Master。此外1分区的Primarily shard没有了,必须在剩下的2个R1中选择一个变成P1,2分区同理。效果图如下:
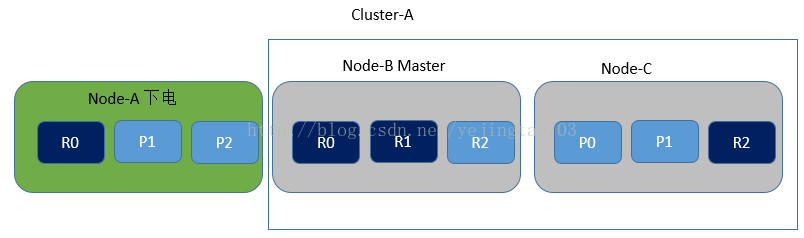
ElasticSearch的shard写入磁盘的反向索引是不变的。
这样设计的好处是:
1, 不需要行锁,提高速率
一次查询将索引从磁盘load到cache,如果cache足够大所有索引都会保存进来,进一步提高查询效率。
缺点是:想让新修改过的文档可以被搜索到,你必须重新构建整个索引。
那么如何更新索引?要引用per-segment的设计,涉及到Lucene中段(segement)的概念。(再次强调是段,不是分片,分片一旦分好是不能变的)
新的文档建立时首先在内存建立索引buffer,每隔一段时间写入到一个新的segment,同时清空内存,准备下一次循环。

2,删除文档也不会去动segment,而是一种.del文件中标记下哪个将要被废弃,当下次Segment整合时真正删除掉。
3,修改,本质上就是一次删除加一次新增。
4,最后看下Segments的整合,按照现在的设计每隔一段时间就会增加一个小块的segment,但是segment会消耗系统的文件句柄,内存,CPU时钟。最重要的是,每一次请求都会依次检查所有的segment。segment越多,检索就会越慢。ElasticSearch不允许这种缺陷的存在,所以后台会默默的把小segment合并成大segment,合并过程中同时把.del里那些逻辑删除的部分在物理上真正抛弃了。















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









