










插入0-N这N个整数,
首先,创建一个表和一个存储过程:
#创建一个存数据的表
CREATE TABLE tb_nums (a INT NOT NULL PRIMARY KEY) ENGINE = INNODB;
#创建存储过程
CREATE PROCEDURE pCreateNums (x INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT (1);
TRUNCATE TABLE tb_nums;
#通过循环迭代每次+1插入到数据库中
WHILE s <= x DO
BEGIN
INSERT INTO tb_nums SELECT
s;
SET s = s + 1;
END;
END
WHILE;
END;这个方法肯定是可以插入的,但效率不高,如图,当插入100000条数据时,大约花费了2分钟或者更多。
创建结果为:
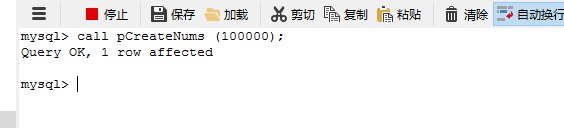
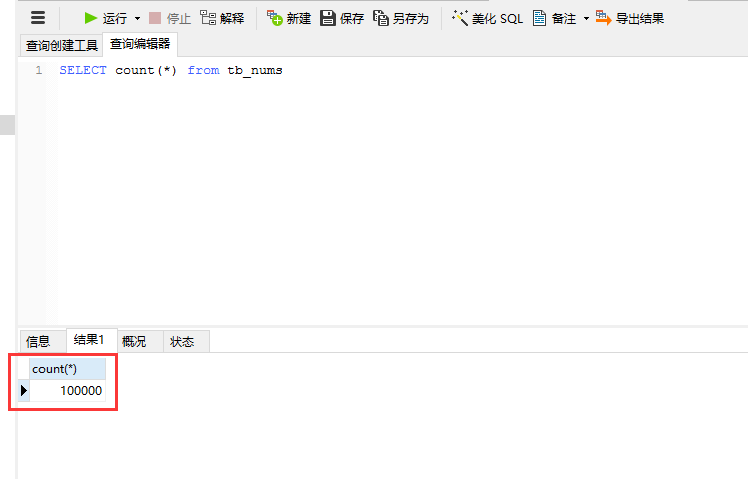
这个方法的开销主要在于Insert语句执行了100000次。
#创建存储过程
CREATE PROCEDURE pCreateNumsTwo (x INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
TRUNCATE TABLE tb_nums;
INSERT INTO tb_nums SELECT
s; //先把s=1插进去
WHILE s * 2 <= x DO
BEGIN
INSERT INTO tb_nums SELECT
a + s
FROM
tb_nums;
SET s = s * 2;
END;
END
WHILE;
END;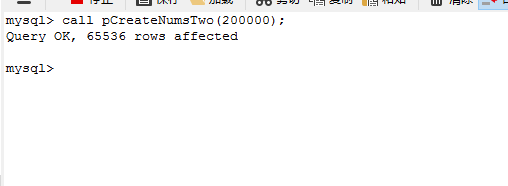
在这个存储过程中,变量s保存插入该表的行数。该过程先把1插入表中,然后当s*2 < x成立时循环,每次迭代中,该过程把表当前行的值加上s后在插入,即先插入{1},然后是{2},然后是{3,4},{5,6,7,8},{9,10,11,12,13,14,15,16},因此这个存储过程更快,200000行数据也只要1秒钟。真正的原因就是Insert次数少了。详细步骤如下:
- 首先s=1,2*s<200000,此时数据库中的数据为{1}
执行:INSERT INTO tb_nums SELECT a + 1 ,a是数据库中的字段,就插入了1+1
s=s*2=2; - s=2,2*s<200000,此时数据库中的数据为{1,2}
执行:INSERT INTO tb_nums SELECT a + 2,a是数据库中的字段,就插入了1+2,2+2
s=s*2=4; - s=4,2*s<200000,此时数据库中的数据为{1,2,3,4}
执行:INSERT INTO tb_nums SELECT a + 4,a是数据库中的字段,就插入了1+4,2+4,3+4,4+4
s=s*2=8; - s=8,2*s<200000,此时数据库中的数据为{1,2,3,4,5,6,7,8}
……
这里是按照2的指数次方进行插入的,实际上只执行了17次插入操作。不过缺点是这个只插入了131072条数据(因为2^17=131072 2^18>200000,因为循环判断的条件是s*2<200000,所以18的时候不满足,于是只插入了131072 条数据)。
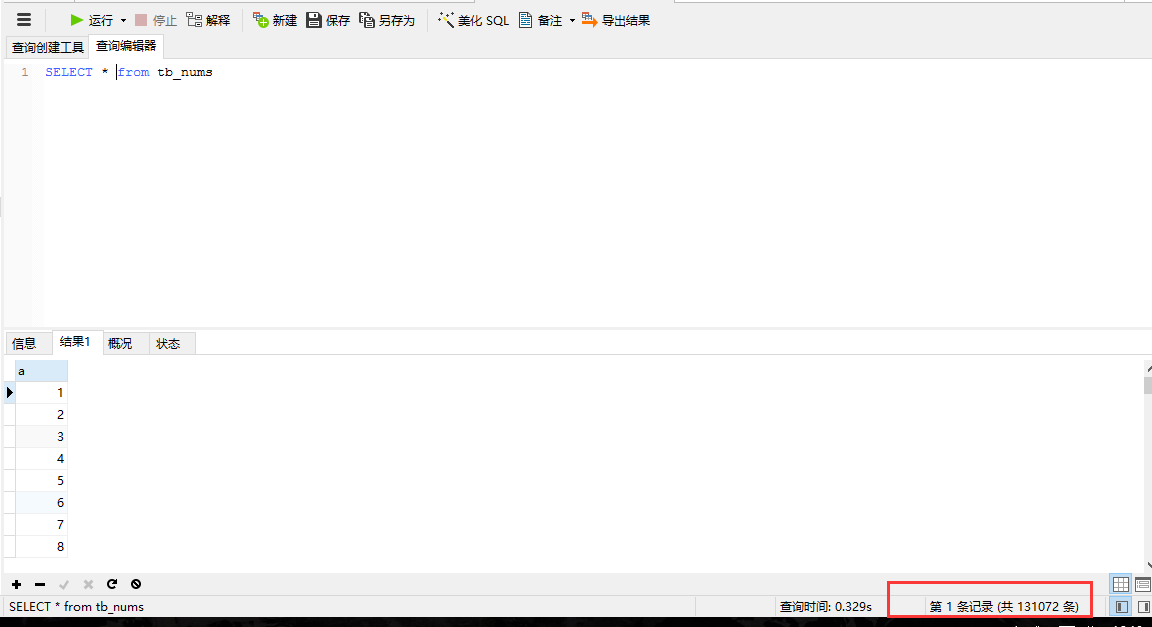
因此,如果我们需要100000内的数据在查询时加上select * from tb_nums where a<= 100000
或者直接把>100000的删掉也很快速 delete from tb_nums where a>100000















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









