










数据缺失、检测和过滤异常值、移除重复数据
数据缺失
数据缺失在大部分数据分析应用中都很常见,Pandas使用浮点值NaN表示浮点和非浮点数组中的缺失数据,他只是一个便于被检测出来的数据而已。
from pandas import Series,DataFrame
string_data=Series(['abcd','efgh','ijkl','mnop'])
print(string_data)
print("...........\n")
print(string_data.isnull())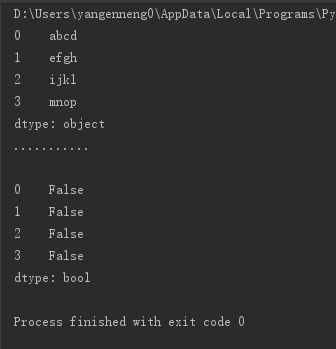
Python内置的None值也会被当作NA处理
from pandas import Series,DataFrame
string_data=Series(['abcd','efgh','ijkl','mnop'])
print(string_data)
print("...........\n")
string_data[0]=None
print(string_data.isnull())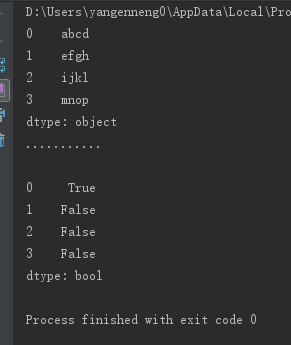
处理NA的方法有四种:dropna,fillna,isnull,notnull
is(not)null,这一对方法对对象做出元素级的应用,然后返回一个布尔型数组,一般可用于布尔型索引。
dropna,对于一个Series,dropna返回一个仅含非空数据和索引值的Series。
问题在于DataFrame的处理方式,因为一旦drop的话,至少要丢掉一行(列)。这里解决方法与前面类似,还是通过一个额外的参数:dropna(axis=0,how=’any’,thresh=None),how参数可选的值为any或者all.all仅在切片元素全为NA时才抛弃该行(列)。thresh为整数类型,eg:thresh=3,那么一行当中至少有三个NA值时才将其保留。
fillna,fillna(value=None,method=None,axis=0)中的value除了基本类型外,还可以使用字典,这样可以实现对不同列填充不同的值。
过滤数据:
对于一个Series,dropna返回一个仅含非空数据和索引值的Series:
from pandas import Series,DataFrame
from numpy import nan as NA
data=Series([1,NA,3.5,NA,7])
print(data.dropna())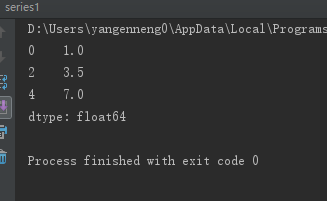
另一个过滤DataFrame行的问题涉及问题序列数据。假设只想留一部分观察数据,可以用thresh参数实现此目的:
from pandas import Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.dropna(thresh=2))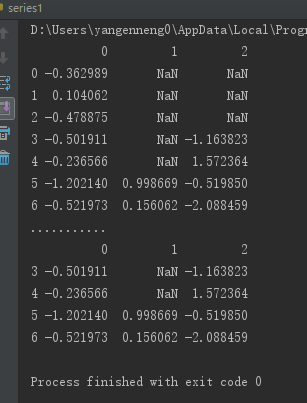
不想滤除缺失的数据,而是通过其他方式填补“空洞”,fillna是最主要的函数。
通过一个常数调用fillna就会将缺失值替换为那个常数值:
from pandas import Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.fillna(0))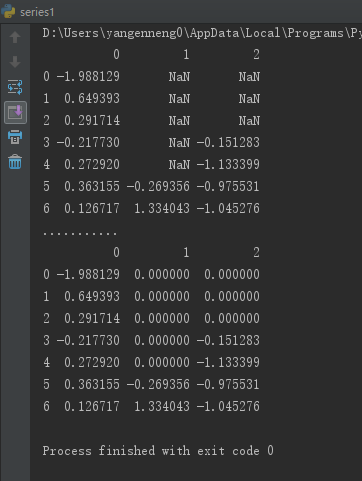
若是通过一个字典调用fillna,就可以实现对不同列填充不同的值。
from pandas import Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(7,3))
data.ix[:4,1]=NA
data.ix[:2,2]=NA
print(data)
print("...........")
print(data.fillna({1:111,2:222}))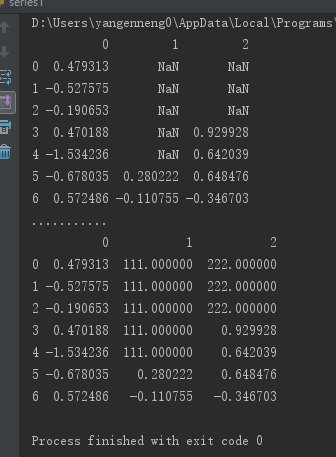
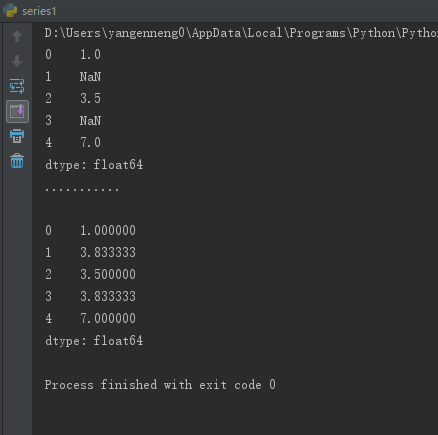
可以利用fillna实现许多别的功能,比如可以传入Series的平均值或中位数:
from pandas import Series,DataFrame, np
from numpy import nan as NA
data=Series([1.0,NA,3.5,NA,7])
print(data)
print("...........\n")
print(data.fillna(data.mean()))
检测和过滤异常值
异常值(outlier)的过滤或变换运算在很大程度上就是数组运算。如下一个(1000,4)的标准正态分布数组:
from pandas import Series,DataFrame, np
from numpy import nan as NA
data=DataFrame(np.random.randn(1000,4))
print(data.describe())
print("\n....找出某一列中绝对值大小超过3的项...\n")
col=data[3]
print(col[np.abs(col) > 3] )
print("\n....找出全部绝对值超过3的值的行...\n")
print(col[(np.abs(data) > 3).any(1)] )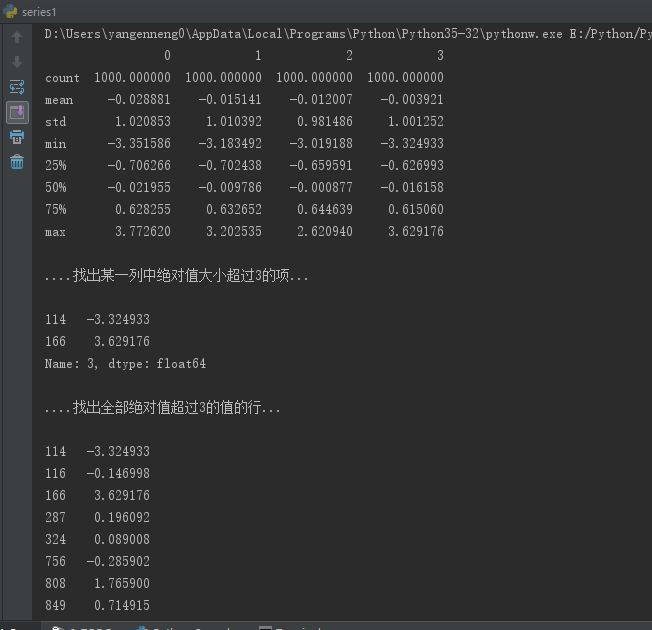
移除重复数据
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行。
from pandas import Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
print(data)
print("........\n")
print(data.duplicated())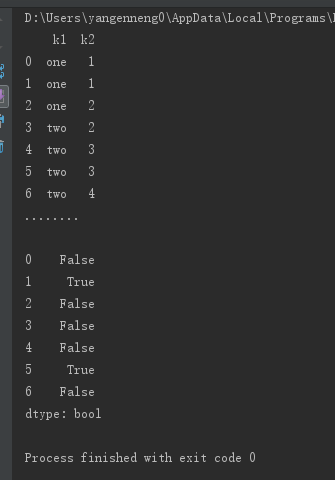
与此相关的还有一个drop_duplicated方法,它用于返回一个移除了重复行的DataFrame:
from pandas import Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
print(data)
print("........\n")
print(data.drop_duplicates())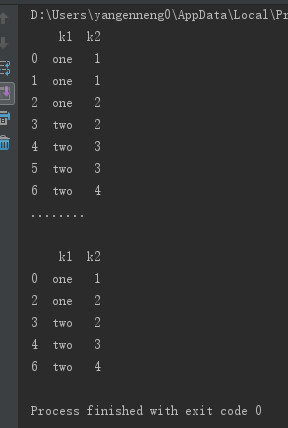
上面的两个方法会默认判断全部列,也可以指定部分列进行重复项判断,假设还有一列值,而只希望根据k1列过滤重复项。
from pandas import Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
data['v1']=range(7)
print(data)
print("........\n")
print(data.drop_duplicates(['k1']))
duplicates和drop_duplicates默认保留第一个出现的值组合。传入take_last=True则保留最后一个:
from pandas import Series,DataFrame, np
from numpy import nan as NA
import pandas as pd
import numpy as np
data=pd.DataFrame({'k1':['one']*3+['two']*4, 'k2':[1,1,2,2,3,3,4]})
data['v1']=range(7)
print(data)
print("........\n")
print(data.drop_duplicates(['k1','k2'],take_last=True))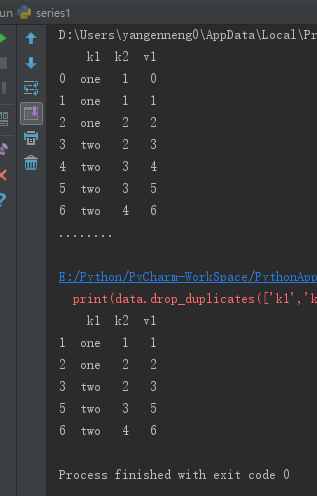
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









