







从事NLP算法工作也快一年了,主要时间花在了LDA上面,但是却一直没有好好整理一下,决心把到目前为止做的一些东西分享出来,如有疑问敬请指正。
在Github上建了一个自己的项目:CkoocNLP(去这个名字是想做一个NLP相关的技术的代码实现,不过目前上面还没有什么东西)。里面已经有基于spark的训练和预测代码实现,有兴趣的同学可以去看看,代码比较简单,可以直接checkout出来跑。
直接先上代码:
1. 入口代码
import algorithm.utils.LDAUtils
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object LDATrainDemo {
def main(args: Array[String]) {
Logger.getRootLogger.setLevel(Level.WARN)
val conf = new SparkConf().setAppName("LDATrain").setMaster("local[2]")
val sc = new SparkContext(conf)
//加载配置文件
val ldaUtils = LDAUtils("config/lda.properties")
val args = Array("../ckooc-nlp/data/preprocess_result.txt", "models/ldaModel")
val inFile = args(0)
val outFile = args(1)
//切分数据
val textRDD = ldaUtils.getText(sc, inFile, 36).filter(_.nonEmpty).map(_.split("\\|")).map(line => (line(0).toLong, line(1)))
//训练模型
val (ldaModel, vocabulary, documents, tokens) = ldaUtils.train(sc, textRDD)
//计算“文档-主题分布”
val docTopics: RDD[(Long, Vector)] = ldaUtils.getDocTopics(ldaModel, documents)
println("文档-主题分布:")
docTopics.collect().foreach(doc => {
println(doc._1 + ": " + doc._2)
})
//计算“主题-词”
val topicWords: Array[Array[(String, Double)]] = ldaUtils.getTopicWords(ldaModel, vocabulary.collect())
println("主题-词:")
topicWords.zipWithIndex.foreach(topic => {
println("Topic: " + topic._2)
topic._1.foreach(word => {
println(word._1 + "\t" + word._2)
})
println()
})
//保存模型和训练结果tokens
ldaUtils.saveModel(sc, outFile, ldaModel, tokens)
sc.stop()
}
}
主要对已经分词后的数据进行LDA训练,并保存模型。主要的处理步骤如下:
- 切分数据,获得包含主要数据内容的RDD
- 进行训练,获得LDA模型、词汇表、文本向量表示、所有切分tokens
- 获取“文档-主题分布”和“主题-词”结果,并打印输出
- 保存模型和切分tokens
说明:这里保存tokens是为了后面进行新文档预测时的文本向量表示使用的词汇表等数据与训练时保持一致。
下面分别对各个步骤进行说明
2. 模型训练
/**
* LDA模型训练函数
*
* @param sc SparkContext
* @param rdd 输入数据
* @return (LDAModel, 词汇表)
*/
def train(sc: SparkContext, rdd: RDD[(Long, String)]): (LDAModel, RDD[String], RDD[(Long, Vector)], DataFrame) = {
val k = config.k
val maxIterations = config.maxIterations
val vocabSize = config.vocabSize
val algorithm = config.algorithm
val alpha = config.alpha
val beta = config.beta
val checkpointDir = config.checkpointDir
val checkpointInterval = config.checkpointInterval
//将数据切分,转换为特征向量,生成词汇表,并计算数据总token数量
val featureStart = System.nanoTime()
val tokens = splitLine(sc, rdd, vocabSize)
val (documents, vocabulary, actualNumTokens) = featureToVector(tokens, tokens, vocabSize)
val vocabRDD = sc.parallelize(vocabulary)
val actualCorpusSize = documents.count()
val actualVocabSize = vocabulary.length
val featureElapsed = (System.nanoTime() - featureStart) / 1e9
featureInfo(actualCorpusSize, actualVocabSize, actualNumTokens, featureElapsed)
val lda = new LDA()
val optimizer = selectOptimizer(algorithm, actualCorpusSize)
lda.setOptimizer(optimizer)
.setK(k)
.setMaxIterations(maxIterations)
.setDocConcentration(alpha)
.setTopicConcentration(beta)
.setCheckpointInterval(checkpointInterval)
if (checkpointDir.nonEmpty) {
sc.setCheckpointDir(checkpointDir)
}
//训练LDA模型
val trainStart = System.nanoTime()
val ldaModel = lda.run(documents)
val trainElapsed = (System.nanoTime() - trainStart) / 1e9
trainInfo(documents, ldaModel, actualCorpusSize, trainElapsed)
(ldaModel, vocabRDD, documents, tokens)
}- 切分tokens(splitLine)
- 文本向量表示(featureToVector)
- 设置LDA训练参数
- LDA模型训练(run)
3.1 文档-主题分布

3.2 主题-词
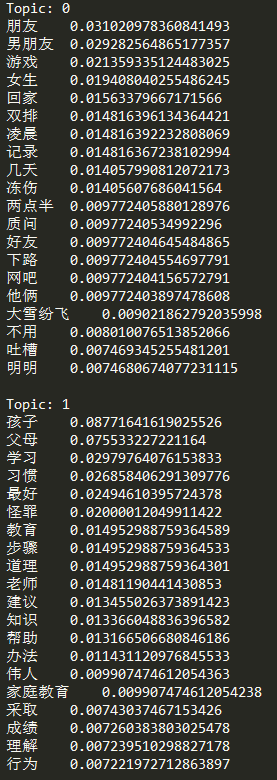
以上两个结果仅展示部分数据















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









