







在前面的一个博客中我们了解了json数据的解析,现在我们来实现对xml格式的数据的解析,xml是一种可扩展标记语言,是由标签组成的。方便我们读取数据。
xml的解析有三种方式,DOM解析,SAX解析,PULL解析。
- DOM解析XML文件时,会将XML文件所有内容都读取到内存中,然后再遍历XML文件树,检索需要的数据。DOM解析XML有很大的缺陷,对内存的消耗比较大,影响系统的性能,所以我这里没有详细讲DOM解析。
- SAX解析是一种占用内存少,且解析速度快的解析器,它采用事件驱动,它不需要解析整个文档,而是按照顺序,检索XML文件是否符合XML的语法,当符合时会触发相应的回调函数。这些函数是在ContentHander中,我们可以重写这些方法来实现我们对数据的解析。
- Pull解析是一种可以解析部分XML文件的解析方式,当我们只需要XML文件中的一部分数据时,用这种方法是非常好的。Pull解析和SAX解析类似,SAX解析器工作方式是自动的将事件推入注册的事件处理器进行处理,因此你不能控制事件的处理主动结束,而Pull解析的工作方式为允许你的应用程序代码主动从解析器获取事件,因此我们可以在获取了我们需要的数据时,主动结束解析。
SAX解析
SAX解析的主要是重写ContentHander中回调方法,在其中主要的是:
- startDocument:当遇到文档时候触发事件。
- startElement:当遇到开始标签时触发。
- endElement:当遇到结束标签时触发。
- characters:当遇到xml内容时触发。

上面是我自己建的一个xml文件,命名为students.xml,并将它放在assets文件夹下。
1.我首先定义了一个student类对象,用来存放解析出来的xml数据
public class Student {
private Long Id;
private String Name;
private String Speciality;
private Long QQ;
public Student() {
}
//省略了get和set方法
}2.实例化一个SAX工厂,并获取SAX解析器,读取xml文件,创建回调函数
protected List<Student> parserXML() {
//实例化一个SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
List<Student> studnets = null;
//获取XML解析器
try {
XMLReader reader = factory.newSAXParser().getXMLReader();
studnets = new ArrayList<Student>();
//设置回调函数,这里是我自定义的回调函数
reader.setContentHandler(new StudentHander(studnets));
//读取Assets下的student.xml文件
reader.parse(new InputSource(SAXXMLActivity.this.
getResources().getAssets().open("students.xml")));
} catch (SAXException e) {
e.printStackTrace();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return studnets;3.自定义StudentHander回调函数,继承自DefaultHander;在回调方法里解析出自己需要的数据。其中preTAG用来存储当前节点名称,在endElement中要记得滞空。
public class StudentHander extends DefaultHandler {
private String preTAG;
private List<Student> ListStudent;
private Student stu;
public StudentHander() {
}
public StudentHander(List<Student> listStudent) {
super();
ListStudent = listStudent;
}
//开始解析文档
@Override
public void startDocument() throws SAXException {
Log.i("----->", "开始解析文档!");
super.startDocument();
}
//开始解析文档元素
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
Log.i("localName----->", localName);
preTAG = localName;
if ("student".equals(localName)) {
stu = new Student();
//将ID保存在stu中
stu.setId(Long.parseLong(attributes.getValue(0)));
for (int i = 0; i < attributes.getLength(); i++) {
Log.i("attribute----->", String.valueOf(stu.getId()));
}
}
//这句话记得要执行
super.startElement(uri, localName, qName, attributes);
}
@Override
public void endDocument() throws SAXException {
Log.i("----->", "文档结束");
super.endDocument();
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
preTAG = "";
if ("student".equals(localName)) {
ListStudent.add(stu);
Log.i("----->", "一个元素解析完成!");
}
super.endElement(uri, localName, qName);
}
//解析节点文本内容
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String str;
//找出元素中的name节点
if ("name".equals(preTAG)) {
str = new String(ch,start,length);
stu.setName(str);
Log.i("name=", str);
}else if("speciality".equals(preTAG)){
str = new String(ch,start,length);
stu.setSpeciality(str);
Log.i("speciality=", str);
}else if("qq".equals(preTAG)){
str = new String(ch,start,length);
stu.setQQ(Long.parseLong(str));
Log.i("qq=", str);
}
super.characters(ch, start, length);
}
public void setListStudent(List<Student> listStudent) {
ListStudent = listStudent;
}
public List<Student> getListStudent() {
return ListStudent;
}
}
这样我们就解析出xml的整个数据了,并在回调函数中将数据保存到了数组对象students中,我们查看一下打印出的log,分析一下SAX的解析过程。
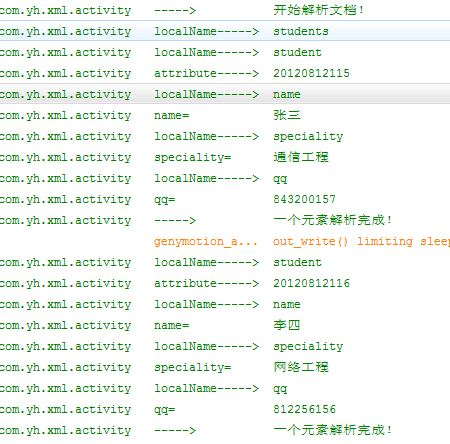
我们可以看出这种按顺序解析XML文件标签的方式,完全符合回调函数中的说明。清晰明了。
Pull解析
pull解析和我们上面的SAX解析方法有些类似,Pull解析也提供了类似SAX的事件:
- START_DOCUMENT:开始文档;
- START_TAG:开始元素;
- TEXT:遇到元素内容;
- END_TAG:结束元素
- END_DOCUMENT:结束文档
Android系统提供了Pull解析的包org.xmlpull.v1,里面有PUll解析工厂类XMLPullParserFactory,和PULL解析器XmlParser。我们实例化工厂类,并获取xml解析器,接着XmlParser实例就可以调用getEventType()和next()等方法主动提取事件,并根据提取的事件做数据的处理。
PULL解析器有两种获取方法:
- 通过工厂类XMLPullParserFactory
- 通过Android实用工具类
protected List<Student> parserXML() {
//初始化一个List<student>变量,用于存放student成员
List<Student> studnets = null;
//初始化student对象,用于存储每一个节点的信息
Student stu = null;
try {
//打开资源文件
InputStream inputStream = PullXMLActivity.this.getResources()
.getAssets().open("students.xml");
//创建XmlParser有两种方法
//方法一:使用工厂类XmlPullParserFactory
XmlPullParserFactory pullFactory = XmlPullParserFactory.newInstance();
XmlPullParser xmlPullParser = pullFactory.newPullParser();
/*
* //方法二:使用Android提供的实用工具类android.util.Xml
//XmlPullParser xmlPullParser = Xml.newPullParser();
//设置输入字节流为UTF-8编码
*
*/
xmlPullParser.setInput(inputStream, "utf-8");
//取得事件类型,用于开始时的判断
int eventType = xmlPullParser.getEventType();
//循环遍历整个文件直到结束
while(eventType != XmlPullParser.END_DOCUMENT){
/*
* 输出log显示事件类型
* START_DOCUMENT:0
*
*/
Log.i("--->event", eventType+" ");
//用于存储节点名称
String localName = "";
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
//碰到文档开头则实例化students变量,并输出log
studnets = new ArrayList<Student>();
Log.e("Pull---->", "start document");
break;
case XmlPullParser.START_TAG:
localName = xmlPullParser.getName();
if ("student".equals(xmlPullParser.getName())) {
stu = new Student();
//将ID保存到stu中
stu.setId(Long.parseLong(xmlPullParser.getAttributeValue(0)));
Log.e("Pull----->", stu.getId()+"");
}else if(stu != null){
//声明一个变量用于存储节点文本
String currentData = null;
if ("name".equals(xmlPullParser.getName())) {
/*
* 注意这里nextText()的使用:当前事件为START-TAG
* 如果接下来是文本,就会返回当前的文本内容;如果下一个事件是End_TAG
* 就会返回空字符串;否则抛出一个yichang
*/
currentData = xmlPullParser.nextText();
//存储name的信息
stu.setName(currentData);
}else if("speciality".equals(xmlPullParser.getName())){
currentData = xmlPullParser.nextText();
//存储专业信息
stu.setSpeciality(currentData);
}else if("qq".equals(xmlPullParser.getName())){
currentData = xmlPullParser.nextText();
//存储专业信息
stu.setQQ(Long.parseLong(currentData));
}
}
break;
case XmlPullParser.END_TAG:
localName = xmlPullParser.getName();
Log.e("Pull----->", localName);
if ("student".equals(localName) && stu != null) {
studnets.add(stu);
stu = null;
}
break;
default:
break;
}
//解析下一事件
eventType = xmlPullParser.next();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (XmlPullParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return studnets;
}这里也打印出log贴出来并做出了分析

总结:
SAX和PULL解析器虽然在代码上可能写的有些复杂,但是它们的解析效率,和思维逻辑的清晰都是非常好的,值得我们在软件开发中使用。















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









