










 本文介绍了Apache Kafka的集群安装过程及其设计原理。包括多节点集群的安装配置、常用管理命令,以及Kafka Broker和集群的工作结构。深入探讨了如何通过Zookeeper进行协调管理和消息的负载均衡。
本文介绍了Apache Kafka的集群安装过程及其设计原理。包括多节点集群的安装配置、常用管理命令,以及Kafka Broker和集群的工作结构。深入探讨了如何通过Zookeeper进行协调管理和消息的负载均衡。
(接上文《架构设计:系统间通信(27)——其他消息中间件及场景应用(上)》)
在本月初的写作计划中,我本来只打算粗略介绍一下Kafka(同样是因为进度原因)。但是,最近有很多朋友要求我详细讲讲Kafka的设计和使用,另外两年前我在研究Kafka准备将其应用到生产环境时,由于没有仔细理解Kafka的设计结构所导致的问题最后也还没有进行交代。所以我决定即使耽误一些时间,也要将Kafka的原理和使用场景给读者详细讨论讨论。这样,也算是对两年来自己学习和使用Kafka的一个总结。
4、Kafka及特性
Apache Kafka最初由LinkedIn贡献,目前它是Apache下的一个顶级开源项目。Apache Kafka设计的首要目标是解决LinkedIn网站中海量的用户操作行为记录、页面浏览记录,后继的Apache Kafka版本也都是将“满足高数据吞吐量”作为版本优化的首要目标。为了达到这个目标,Apache Kafka甚至在其他功能方面上做了一定的牺牲,例如:消息的事务性。如果您的系统需要进行单位时间内大量的数据采集工作,那么可以考虑在您的系统设计方案中加入Apache Kafka。
4-1、Kafka集群安装
4-1-1、安装环境介绍
Apache Kafka的安装过程非常简单。为了节约篇幅我不准备像介绍Apache ActiveMQ那样,专门花费笔墨来介绍它的单机(单服务节点)安装过程和最简单的生产者、消费者的编码过程。而是换一种思路:
直接介绍Apache Kafka多节点集群的安装过程,并且在这个Apache Kafka集群中为新的Topic划分多个分区,演示Apache Kafka的消息负载均衡原理。可能在这个过程中,我会使用一些您还不太了解的词语(或者某些操作您暂时不会理解其中的原因),但是没有关系,您只需要按照我给出的步骤一步一步的做——这些词语和操作会在后文被逐一解释。
首先我们列出将要安装的Kafka集群中需要的服务节点,以及每个服务节点在其中的作用:
| 节点位置 | 节点作用 |
|---|---|
| 192.168.61.139 | Apache Kafka Brocker 1 |
| 192.168.61.138 | Apache Kafka Brocker 2 |
| 192.168.61.140 | zookeeper server |
在这个Apache Kafka集群安装的演示实例中,我们准备了两个Apache Kafka的Brocker服务节点,并且使用其中一个节点充当zookeeper的运行节点。
Apache Kafka集群需要使用Zookeeper服务进行协调工作,所以安装Apache Kafka前需要首先安装和运行Zookeeper服务。由于这边文章主要介绍的是Apache Kafka的工作原理,所以怎样安装和使用Zookeeper的内容就不再进行赘述了,不清楚的读者可以参考我另一篇文章:《hadoop系列:zookeeper(1)——zookeeper单点和集群安装》。这里我们运行zookeeper只是使用了zookeeper服务的单节点工作模式,如果您需要在实际生产环境运行Apache Kafka集群,那么zookeeper clusters的服务节点数量至少应该是3个(且使用不同的物理机)。
4-1-2、Kafka集群安装过程
- 首先我们在192.168.61.140的服务器上安装Zookeeper以后,直接启动zookeeper即可:
zkServer.sh start- 您可以在Apache Kafka的官网下载V0.8.X版本的安装包(http://kafka.apache.org/downloads.html),请不要下载V0.9.X版本的安装包,因为V0.9.X版本中消费者端的配置属性发生了相当的变化。我们本章节的讲解将基于V0.8.1.1版本,并且全部针对V0.8.X版本兼容的配置属性(https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz)。
您可以直接使用wget命令,也可以通过浏览器(或者第三方软件)下载:
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.1.1/kafka_2.10-0.8.1.1.tgz- 下载后,运行命令进行压缩文件的解压操作:
tar -xvf ./kafka_2.10-0.8.1.1.tgz笔者习惯将可运行软件放置在/usr目录下,您可以按照您自己的操作习惯或者您所在团队的规范要求放置解压后的目录(正式环境下不建议使用root账号运行Kafka):
mv /root/kafka_2.10-0.8.1.1 /usr/kafka_2.10-0.8.1.1/- Apache Kafka所有的管理命令都存放在安装路径下的./bin目录中。所以,如果您希望后续管理方便就可以设置一下环境变量:
export PATH=/usr/kafka_2.10-0.8.1.1/bin:$PATH
#记得在/etc/profile文件的末尾加入相同的设置- Apache Kafka的配置文件存放在安装路径下的./config目录下。如下所示:
-rw-rw-r--. 1 root root 1202 4月 22 2014 consumer.properties
-rw-rw-r--. 1 root root 3828 4月 22 2014 log4j.properties
-rw-rw-r--. 1 root root 2217 4月 22 2014 producer.properties
-rw-rw-r--. 1 root root 5322 4月 28 23:32 server.properties
-rw-rw-r--. 1 root root 3326 4月 22 2014 test-log4j.properties
-rw-rw-r--. 1 root root 995 4月 22 2014 tools-log4j.properties
-rw-rw-r--. 1 root root 1023 4月 22 2014 zookeeper.properties如果您进行的是Apache Kafka集群安装,那么您只需要关心“server.properties”这个配置文件(其他配置文件的作用,我们后续会讨论到)。
其中目录下有一个zookeeper.properties不建议使用。之所以有这个配置文件,是因为Kafka中带有一个zookeeper运行环境,如果您使用Kafka中的“zookeeper-server-start.sh”命令启动这个自带zookeeper环境,才会用到这个配置文件。
- 开始编辑server.properties配置文件。这个配置文件中默认的配置项就有很多,但是您不必全部进行更改。下面我们列举了更改后的配置文件情况,其中您需要主要关心的属性使用中文进行了说明(当然原有的注释也会进行保留):
# The id of the broker. This must be set to a unique integer for each broker.
# 非常重要的一个属性,在Kafka集群中每一个brocker的id一定要不一样,否则启动时会报错
broker.id=2
# The port the socket server listens on
port=9092
# Hostname the broker will bind to. If not set, the server will bind to all interfaces
#host.name=localhost
# The number of threads handling network requests
num.network.threads=2
# The number of threads doing disk I/O
# 故名思议,就是有多少个线程同时进行磁盘IO操作。
# 这个值实际上并不是设置得越大性能越好。
# 在我后续的“存储”专题会讲到,如果您提供给Kafka使用的文件系统物理层只有一个磁头在工作
# 那么这个值就变得没有任何意义了
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=1048576
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=1048576
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
# A comma seperated list of directories under which to store log files
# 很多开发人员在使用Kafka时,不重视这个属性。
# 实际上Kafka的工作性能绝大部分就取决于您提供什么样的文件系统
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across the brokers.
num.partitions=2
# The number of messages to accept before forcing a flush of data to disk
# 从Page Cache中将消息正式写入磁盘上的阀值:以待转储消息数量为依据
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
# 从Page Cache中将消息正式写入磁盘上的阀值:以转储间隔时间为依据
#log.flush.interval.ms=1000
# The minimum age of a log file to be eligible for deletion
# log消息信息保存时长,默认为168个小时
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
# 默认为1GB,在此之前log文件不会执行删除策略
# 实际环境中,由于磁盘空间根本不是问题,并且内存空间足够大。所以笔者会将这个值设置的较大,例如100GB。
#log.retention.bytes=1073741824
# The maximum size of a log segment file.
# When this size is reached a new log segment will be created.
# 默认为512MB,当达到这个大小,Kafka将为这个Partition创建一个新的分段文件
log.segment.bytes=536870912
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
# 文件删除的保留策略,多久被检查一次(单位毫秒)
# 实际生产环境中,6-12小时检查一次就够了
log.retention.check.interval.ms=60000
# By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires.
# If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction.
log.cleaner.enable=false
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# root directory for all kafka znodes.
# 到zookeeper的连接信息,如果有多个zookeeper服务节点,则使用“,”进行分割
# 例如:127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002
zookeeper.connect=192.168.61.140:2181
# Timeout in ms for connecting to zookeeper
# zookeeper连接超时时间
zookeeper.connection.timeout.ms=1000000当然以上系统自带的Brocker服务节点的配置项还不是最完整的,在官网(http://kafka.apache.org/documentation.html#brokerconfigs)上完整的“server.properties”文件的配置属性和说明信息。
再次强调一下,以上配置属性中必须按照您自己的环境更改的属性有:“broker.id”、“log.dirs”以及“zookeeper.connect”。其中每一个Kafka服务节点的“broker.id”属性都必须不一样。
这样我们就完成了其中一个Broker节点的安装和配置。接下来您需要按照以上描述的步骤进行Kafka集群中另一个Broker节点的安装和配置。一定注意每一个Kafka服务节点的“broker.id”属性都必须不一样,在本演示实例中,我设置的broker.id分别为1和2。
接下来我们启动Apache Kafka集群中已经完成安装和配置的两个Broker节点。如果以上所有步骤您都正确完成了,那么您将会看到类似如下的启动日志输出:
#分别在两个节点上执行这条命令,以便完成节点启动:
kafka-server-start.sh /usr/kafka_2.10-0.8.1.1/config/server.properties
#如果启动成功,您将看到类似如下的日志提示:
......
[2016-04-30 02:53:17,787] INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
[2016-04-30 02:53:17,799] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
......- 启动成功后,我们可以在某一个Kafka Broker 节点上运行以下命令来创建一个topic。为了后续进行讲解,我们创建的topic有4个分区和两个复制因子:
kafka-topics.sh --create --zookeeper 192.168.61.139:2181 --replication-factor 2 --partitions 4 --topic my_topic24-1-3、Kafka中的常用命令
在安装Kafka集群的时候,我们使用到了Kafka提供的脚本命令进行集群启动、topic创建等相关操作。实际上Kafka提供了相当丰富的脚本命令,以便于开发者进行集群管理、集群状态监控、消费者/生产者测试等工作,这里为大家列举一些常用的命令:
4-1-3-1 集群启动:
kafka-server-start.sh config/server.properties这个命令带有一个参数——指定启动服务所需要的配置文件。默认的配置文件上文已经提到过,存在于Kafka安装路径的./config文件夹下,文件名为server.properties。
4-1-3-2 创建Topic:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test带有 –create参数的kafka-topics命令脚本用于在Kafka集群上创建一个新的topic。后续的四个参数为:
zookeeper 该参数用来指定Kafka集群所使用的zookeeper的地址,这是因为当topic被创建时,zookeeper下的/config/topics目录中会记录新的topic的配置信息。
replication-factor 复制因子数量。副本是Kafka V0.8.X版本中加入的保证消息可靠性的功能,复制因为是指某一条消息进行复制的副本数量,该功能以集群中Broker服务节点的数量为单位。也就是说当Broker服务节点的数量为X时,复制因子的数量最多为X。否则在执行topic创建时会报告类似如下的错误:
Error while executing topic command replication factor: 3 larger than available brokers: 2Kafka的复制过程将在本文的后续章节进行介绍。当然,这个参数可以不进行设置,如果不进行设置该参数的默认值则为1。
partitions 分区数量(默认分区为1)。一个topic可以有若干分区,这些分区分布在Kafka集群的一个或者多个Broker上。后文我们将讨论到,partition分区是Kafka集群实现消息负载均衡功能的重要基础,且topic中partition分区一旦创建就不允许进行动态更改。所以一旦您准备在正式生产环境创建topic,就一定要慎重考虑它的分区数量。
topic 新创建的topic的名称。该参数在创建topic时指定,且在Kafka集群中topic的名称必须是唯一的。
4-1-3-3 以生产者身份登录测试
kafka-console-producer.sh --broker-list localhost:9093 --topic test
# 或者
kafka-console-producer.sh --producer.config client-ssl.properties使用命令脚本(而不是Kafka提供的各种语言的API),模拟一个消息生产者登录集群,主要是为了测试指定的topic的工作情况是否正常。可以有两种方式作为消息生产者登录Kafka集群:
第一种方式指定broker-list参数和topic参数,broker-list携带需要连接的一个或者多个broker服务节点;topic为指定的该消息生产者所使用的topic的名称。
第二种方式是指定producer生产者配置文件和客户端ssl加密信息配置文件(后一个文件也可不进行指定,如果您没有在Kafka集群中配置ssl加密规则的话)。默认的producer生产者配置文件存放在kafka安装路径的./config目录下,文件名为producer.properties。
4-1-3-4 以消费者身份登录测试
kafka-console-consumer.sh --zookeeper localhost:2181 --topic test同样您可以使用命令脚本的方式,以消息消费者的身份登录Kafka集群,目的相同:为了测试Kafka集群下您创建的topic是否能够正常工作。该命令有两个参数:
zookeeper 指定的Kafka集群所使用的zookeeper地址,如果有多个zookeeper节点就是用“,”进行分割。该参数必须进行指定。
topic 该参数用于指定使用的topic名称信息。如果您的topic在kafka集群下工作正常的话,那么在成功使用消费者身份登录后,就可以收到topic中有生产者发送的消息信息了。
4-1-3-5 查看Topic状态
kafka-topics.sh --describe --zookeeper 192.168.61.139:2181 --topic my_topic2以上命令可以用来查询指定的topic(my_topic2)的关键属性,包括topic的名称、分区情况、每个分期的主控节点、复制因子、复制序列已经赋值序列的同步状态等信息。命令可能的结果如下所示:
Topic:my_topic2 PartitionCount:4 ReplicationFactor:2 Configs:
Topic: my_topic2 Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: my_topic2 Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: my_topic2 Partition: 2 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: my_topic2 Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2请注意这个查询命令,因为这个查询命令所反映的结果透露出了Apache Kafka V0.8.X版本的主要设计原理,我们本节下半部分的内容将从这里展开。
4-2、Kafka原理:设计结构
一个完整的Apache Kafka解决方案的组成包括四个要素:Producer(消息生产者)、Server Broker(服务代理器)、Zookeeper(协调者)、Consumer(消息消费者)。 Apache Kafka在设计之初就被认为是集群化工作的,所以要说清楚Apache Kafa的设计结构除了要讲述每一个Kafka Broker是如何工作的以外,还要讲述清楚整个Apache Kafka集群是如何工作的。
4-2-1、Kafka Broker工作结构
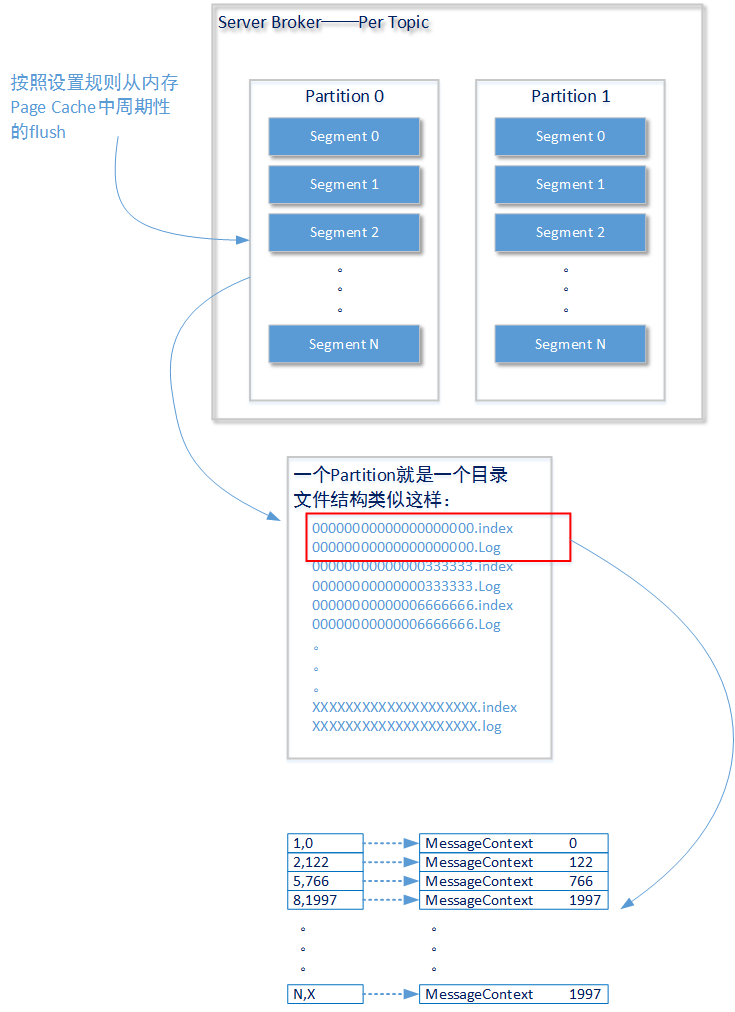
在Apache Kafka的Server Broker设计中,一个独立进行消息获取、消息记录和消息分送操作的队列称之为Topic(和ActiveMQ中Queue或者Topic的概念同属一个级别)。以下我们讨论的内容都是针对一个Topic而言,后续内容就不再进行说明了。
- 上图描述了一个独立的Topic构造结构:Apache Kafka将Topic拆分成多个分区(Partition),这些分区(Partition)可能存在于同一个Broker上也可能存在于不同的Broker上。如果您观察Kafka的文件存储结构就会发现Kafka会为Topic中每一个分区创建一个独立的文件加,类似如下所示(以下的Topic——my_topic2一共创建了4个分区):
[root@kafka1 my_topic2-0]# ls
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-0
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-1
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-2
drwxr-xr-x. 2 root root 4096 4月 29 18:32 my_topic2-3由Producer发送的消息会被分配到各个分区(Partition)中进行存储,至于它们是按照什么样的规则被分配的在后文会进行讲述。一条消息记录只会被分配到一个分区进行存储,并且这些消息以分区为单位保持顺序排列。这些分区是Apache Kafka性能的第一种保证方式:单位数量相同的消息将分发到存在于多个Broker服务节点上的多个Partition中,并利用每个Broker服务节点的计算资源进行独立处理。
每一个分区都中会有一个或者多个段(segment)结构。如上图所示,一个段(segment)结构包含两种类型的文件:.index后缀的索引文件和.log后缀的数据文件。前一个index文件记录了消息在整个topic中的序号以及消息在log文件中的偏移位置(offset),通过这两个信息,Kafka可以在后一个log文件中找到这条消息的真实内容。
我们在之前的文章中已经介绍过(在我后续的专题中还会继续讨论这个问题),在磁盘上进行的文件操作只有采用顺序读和顺序写才能做到高效的磁盘I/O性能。这是Kafka保证性能的又一种方式——对索引index文件始终保证顺序读写:当在磁盘上记录一条消息时,始终在文件的末尾进行操作;当在磁盘上读取一条消息时,通过index顺序查找到消息的offset位置,再进行消息读取。后一种消息读取操作下,如果index文件过大,Kafka的磁盘操作就会耗费掉相当的时间。所以Kafak需要对index文件和log文件进行分段。
实际上Kafka之所以“快”,并不只是因为它的I/O操作是顺序读写和多个分区的概念;毕竟类似于AcitveMQ也有多节点集群的概念,并且后者通过使用LevelDB或者KahaDB这样的存储方案也可以实现磁盘的顺序I/O操作。要知道如果消息消费者真正需要到磁盘上寻找数据了,那么整个Kafka集群的性能也不会好到哪儿去:目前SATA3串口通讯的理论速度也只有6Gpbs,使用SATA3串口通讯的固态硬盘,真实的顺序读取最快速度也不过550M/S。
Kafka对Linux操作系统下Page Cache技术的应用,才是其高性能的最大保证。文件内容的组织结构只是其保证消息可靠性的一种方式,真实的业务环境下Kafka一般不需要在磁盘上为消费者寻找消息记录(只要您的内存空间够大)。关于Linux操作系统下的Page Cache技术又是另外一个技术话题,我会在随后推出的“存储”专题中为各位读者进行详细介绍(LevelDB也应用到了Linux Page Cache技术)。
4-2-2、Kafka Cluster结构
说清楚了单个Kafka Broker结构,我们再来看看整个Kafka集群是怎样工作的。以下视图描述了某个Topic下的一条消息是如何在Kafka 集群结构中流动的(实线有向箭头):
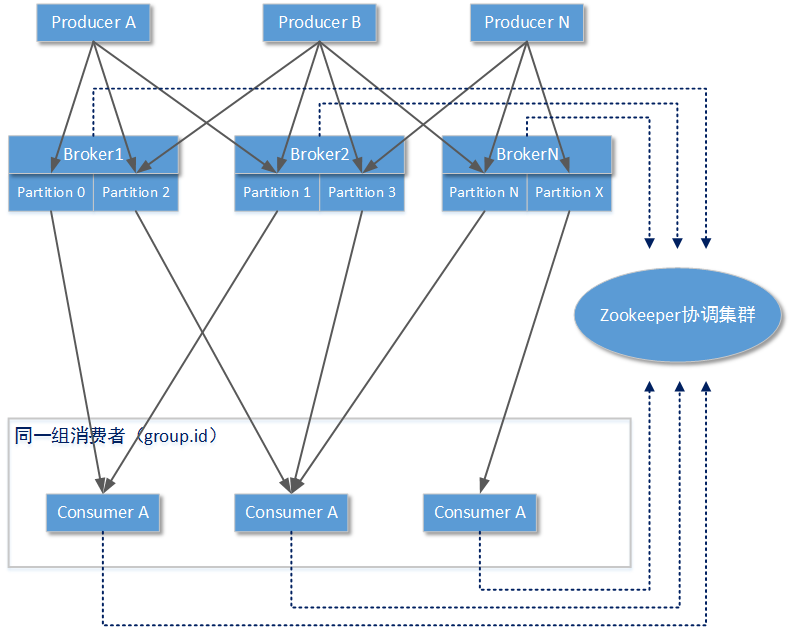
整个Kafka集群中,可以有多个消息生产者。这些消息生产者可能在同一个物理节点上,也可能在不同的物理节点。它们都必须知道哪些Kafka Broker List是将要发送的目标:消息生产者会决定发送的消息将会送入Topic的哪一个分区(Partition)。
消费者都是按照“组”的单位进行消息隔离:在同一个Topic下,Apache Kafka会为不同的消费者组创建独立的index索引定位。也就是说当消息生产者发送一条消息后,同一个Topic下不同组的消费者都会收到这条信息。
同一组下的消息消费者可以消费Topic下一个分区或者多个分区中的消息,但是一个分区中的消息只能被同一组下的某一个消息消费者所处理。也就是说,如果某个Topic下只有一个分区,就不能实现消息的负载均衡。另外Topic下的分区数量也只能是固定的,不可以在使用Topic时动态改变,这些分区在Topic被创建时使用命令行指定或者参考Broker Server中配置的默认值。
由于存在以上的操作规则,所以Kafka集群中Consumer(消费者)需要和Kafka集群中的Server Broker进行协调工作:这个协调工作者交给了Zookeeper集群。zookeeper集群需要记录/协调的工作包括:当前整个Kafka集群中有哪些Broker节点以及每一个节点处于什么状态(活动/离线/状态)、当前集群中所有已创建的Topic以及分区情况、当前集群中所有活动的消费者组/消费者、每一个消费者组针对每个topic的索引位置等。
当一个消费者上线,并且在消费消息之前。首先会通过zookeeper协调集群获取当前消费组中其他消费者的连接状态,并得到当前Topic下可用于消费的分区和该消费者组中其他消费者的对应关系。如果当前消费者发现Topic下所有的分区都已经有一一对应的消费者了,就将自己置于挂起状态(和broker、zookeeper的连接还是会建立,但是不会到分区Pull消息),以便在其他消费者失效后进行接替。
如果当前消费者连接时,发现整个Kafka集群中存在一个消费者(记为消费者A)关联Topic下多个分区的情况,且消费者A处于繁忙无法处理这些分区下新的消息(即消费者A的上一批Pull的消息还没有处理完成)。这时新的消费者将接替原消费者A所关联的一个(或者多个)分区,并且一直保持和这个分区的关联。
由于Kafka集群中只保证同一个分区(Partition)下消息队列中消息的顺序。所以当一个或者多个消费者分别Pull一个Topic下的多个消息分区时,您在消费者端观察的现象可能就是消息顺序是混乱的。这里我们一直在说消费者端的Pull行为,是指的Topic下分区中的消息并不是由Broker主动推送到(Push)到消费者端,而是由消费者端主动拉取(Pull)。
===========================
(接下文)


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











