







一,需求:
在map执行前,即setInputFormatClass过程,会进行数据的读入,默认的是每次读入一行数据,进行计算。现在需要改成每次读入两行数据并且合并结果输出。
二,思路及解决方法:
建议先看看他们的源码,理解思路。
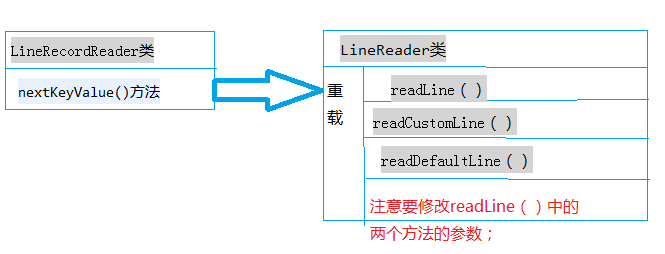
我这里是采用的TextInputFormat.class的输入格式。它的key是每一行的偏移位置,value就是它这一行的内容。其中有创建LineRecordReader类,它就是用来读取数据的封装类,我们需要重写它。
在LineRecordReader类中,观察出其nextKeyValue()方法中,有涉及到读取数据的方法,readLine(),在这个readLine()方法之前加个boolean值,用来控制后面不会将已经读到了的数据清空,然后再加个for循环用来做多次读取。再把这个传到readLine()中重写这个方法。
这事又需要重写它的父类LineReader,在LineRecordReader中是调用的SplitLineReader类,它是继承的LineReader类,还需要重写其他两个类,UncompressedSplitLineReader和CompressedSplitLineReader这两个类好像是用来做压缩的,不用管直接复制就行。
回到LineReader类,我们需要重载他的readLine()方法增加了一个boolean的参数。并将参数传到重载的readCustomLine()和readDefaultLine()在这个两个方法中只需利用boolean值,对数据清除进行判断,其他代码复制即可。
下面一个简图展示这个过程:
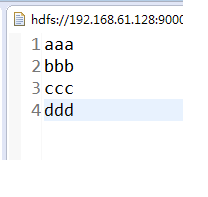
1,输入的数据:
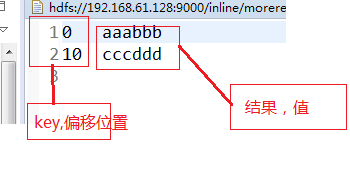
2,结果:
源码展示:
,1, 测试类
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestUserInputFormat {
public static class UserMapper extends Mapper<LongWritable,Text, LongWritable, Text>{
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
public static void main(String[] args) {
try {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf,"Test lineRecordReader");
job.setJarByClass(TestUserInputFormat.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(UserMapper.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path("hdfs://192.168.61.128:9000/inline/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.61.128:9000/outline/"+System.currentTimeMillis()+"/"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (IllegalStateException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2,输入格式类
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import com.google.common.base.Charsets;
/** An {@link InputFormat} for plain text files. Files are broken into lines.
* Either linefeed or carriage-return are used to signal end of line. Keys are
* the position in the file, and values are the line of text.. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
}
3,读取数据类:
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CodecPool;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.Decompressor;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.commons.logging.LogFactory;
import org.apache.commons.logging.Log;
/**
* Treats keys as offset in file and value as line.
*/
@InterfaceAudience.LimitedPrivate({"MapReduce", "Pig"})
@InterfaceStability.Evolving
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
public static final String MAX_LINE_LENGTH =
"mapreduce.input.linerecordreader.line.maxlength";
private long start;
private long pos;
private long end;
private SplitLineReader in;
private FSDataInputStream fileIn;
private Seekable filePosition;
private int maxLineLength;
private LongWritable key;
private Text value;
private boolean isCompressedInput;
private Decompressor decompressor;
private byte[] recordDelimiterBytes;
public LineRecordReader() {
}
public LineRecordReader(byte[] recordDelimiter) {
this.recordDelimiterBytes = recordDelimiter;
}
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
private int maxBytesToConsume(long pos) {
return isCompressedInput
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









