







Kylin基于MOLAP实现,查询的时候利用Calcite框架,从存储在Hbase的segment表(每一个segment对应着一个htable)获取数据,其实理论上就相当于使用Calcite支持SQL解析,数据从Hbase中读取,中间Kylin主要完成如何确定从Hbase中的哪些表读数据,如何读取数据,以及解析数据的格式。
场景设置
首先设想一种cube的场景:
维度:A(cardinality=10)、B(cardinality=20)、C(cardinality=30)、D(cardinality=40),其中A为mandatory维度,rowkey顺序为A、B、C、D,只有一个分组。
度量:COUNT(1), SUM(X)
在这种情况下,这个cube包含如下的cuboid:ABCD、ABC、ABD、ACD、AB、AC、AD、A。目前Kylin在执行查询的时候只能通过查找cube进行匹配,如果能够找到一个匹配的cube则读取通过扫描该cube的所有segment处理该请求,首先先看一下kylin是如何处理一个SQL查询的。
执行查询
Kylin提供了两种执行SQL查询的方式:jdbc访问和http api的访问,前者的实现实际上是在客户端封装了http api请求,然后获取结果再转换成ResultSet对象,在执行查询之前Kylin服务端会对查询的SQL做缓存,尤其是执行时间比较久的查询,缓存是基于SQL的内容作为key,结果作为value的,所以重复执行一个查询会很快返回的(这是因为Kylin假设数据是只读的,不会被修改)。如果缓存不命中则使用服务器内嵌的Calcite创建一个向Calcite的jdbc connection,然后使用jdbc的方式获取执行结果,在使用Calcite的时候用户只需要给Calcite提供数据,Calcite能够完成其他物理算子的优化和执行,但是对于Kylin来说,它深度定制了Calcite,增加了一些优化的策略,所以总的来说查询可以分成两部分:1、kylin是如何使用calcite完成SQL的解析,获取SQL的上下文;2、kylin如何从预计算的数据中获取数据并进行计算的。
使用Calcite完成SQL解析,获取查询上下文
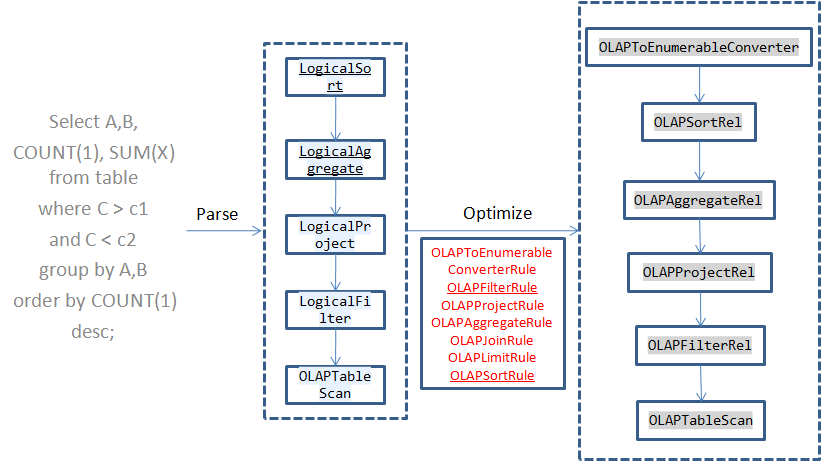
当在Calcite中执行一个SQL时,Calcite会解析得到AST树,然后再对逻辑执行计划进行优化,Calcite的优化规则是基于规则的,在Calcite中注册了一些新的Rule,在优化的过程中会根据这些规则对算子进行转换为对应的物理执行算子,接下来Calcite从上到下一次执行这些算子。这些算子都实现了EnumerableRel接口,在执行的时候调用implement函数:
public interface EnumerableRel
extends RelNode {
/**
* Creates a plan for this expression according to a calling convention.
*
* @param implementor Implementor
* @param pref Preferred representation for rows in result expression
* @return Plan for this expression according to a calling convention
*/
Result implement (EnumerableRelImplementor implementor , Prefer pref);
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









