







 本文对比分析了Hadoop生态中的两种列式存储格式Parquet和ORC,从数据模型、文件结构和数据访问等方面进行深入探讨。测试结果显示,ORC在存储空间和数据导入速度上优于Parquet,而在查询性能上两者相当,但ORC支持ACID操作。在选择存储格式时,需结合实际数据特性和查询引擎性能考虑。
本文对比分析了Hadoop生态中的两种列式存储格式Parquet和ORC,从数据模型、文件结构和数据访问等方面进行深入探讨。测试结果显示,ORC在存储空间和数据导入速度上优于Parquet,而在查询性能上两者相当,但ORC支持ACID操作。在选择存储格式时,需结合实际数据特性和查询引擎性能考虑。
背景
随着大数据时代的到来,越来越多的数据流向了Hadoop生态圈,同时对于能够快速的从TB甚至PB级别的数据中获取有价值的数据对于一个产品和公司来说更加重要,在Hadoop生态圈的快速发展过程中,涌现了一批开源的数据分析引擎,例如Hive、Spark SQL、Impala、Presto等,同时也产生了多个高性能的列式存储格式,例如RCFile、ORC、Parquet等,本文主要从实现的角度上对比分析ORC和Parquet两种典型的列存格式,并对它们做了相应的对比测试。
列式存储
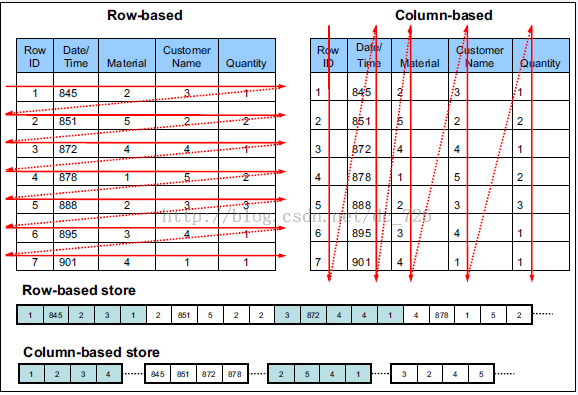
由于OLAP查询的特点,列式存储可以提升其查询性能,但是它是如何做到的呢?这就要从列式存储的原理说起,从图1中可以看到,相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
嵌套数据格式
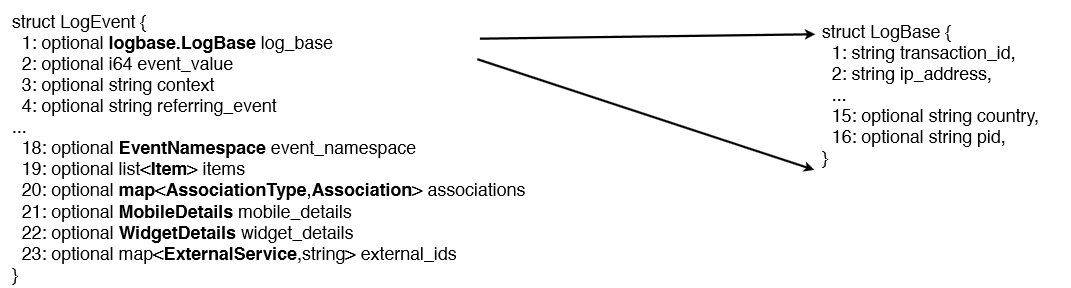
通常我们使用关系数据库存储结构化数据,而关系数据库支持的数据模型都是扁平式的,而遇到诸如List、Map和自定义Struct的时候就需要用户自己解析,但是在大数据环境下,数据的来源多种多样,例如埋点数据,很可能需要把程序中的某些对象内容作为输出的一部分,而每一个对象都可能是嵌套的,所以如果能够原生的支持这种数据,查询的时候就不需要额外的解析便能获得想要的结果。例如在Twitter,他们一个典型的日志对象(一条记录)有87个字段,其中嵌套了7层,如下图。
随着嵌套格式的数据的需求日益增加,目前Hadoop生态圈中主流的查询引擎都支持更丰富的数据类型,例如Hive、SparkSQL、Impala等都原生的支持诸如struct、map、array这样的复杂数据类型,这样促使各种存储格式都需要支持嵌套数据格式。
Parquet存储格式
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。Parquet最初是由Twitter和Cloudera合作开发完成并开源,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet最初的灵感来自Google于2010年发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能,在Dremel论文中还介绍了Google如何使用这种存储格式实现并行查询的,如果对此感兴趣可以参考论文和开源实现Drill。
数据模型
Parquet支持嵌套的数据模型,类似于Protocol Buffers,每一个数据模型的schema包含多个字段,每一个字段有三个属性:重复次数、数据类型和字段名,重复次数可以是以下三种:required(只出现1次),repeated(出现0次或多次),optional(出现0次或1次)。每一个字段的数据类型可以分成两种:group(复杂类型)和primitive(基本类型)。例如Dremel中提供的Document的schema示例,它的定义如下:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}
可以把这个Schema转换成树状结构,根节点可以理解为repeated类型,如图3。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









