






第一篇:C++基本类型与结构体内存布局
Reference: http://cnblogs.com/itech
Key words: class, struct, memory alignment
1. 基本类型(basic type)
 //
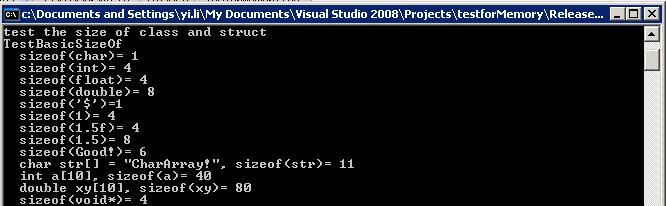
test the size of class and struct
//
test the size of class and struct
2
void
TestBasicSizeOf() 3
 {
{ 

4
 cout << __FUNCTION__ << endl;
cout << __FUNCTION__ << endl; 5
cout << " sizeof(char)= " << sizeof ( char ) << endl; 6
cout << " sizeof(int)= " << sizeof ( int ) << endl; 7
cout << " sizeof(float)= " << sizeof ( float ) << endl; 8
cout << " sizeof(double)= " << sizeof ( double ) << endl; 9
10
cout << " sizeof('$')=" << sizeof ( '$' ) << endl; 11
cout << " sizeof(1)= " << sizeof ( 1 ) << endl; 12
cout << " sizeof(1.5f)= " << sizeof ( 1.5f ) << endl; 13
cout << " sizeof(1.5)= " << sizeof ( 1.5 ) << endl; 14
15
cout << " sizeof(Good!)= " << sizeof ( "Good!" ) << endl ; 16
17
char str[] = "CharArray!"; 18
int a[10]; 19
double xy[10]; 20
cout << " char str[] = /"CharArray!/"," << " sizeof(str)= " << sizeof (str) << endl; 21
cout << " int a[10]," << " sizeof(a)= " << sizeof (a) << endl; 22
cout << " double xy[10]," << " sizeof(xy)= " << sizeof (xy) << endl; 23
24
cout << " sizeof(void*)= " << sizeof(void*) << endl; 25
 }
}
2. 结构体与类
这里的代码是结构体,但是结构体和类在C++中是通用的,唯一的区别就是默认的访问方式,struct-public, class-private
struct
st12
{3
short number;4
float math_grade;5
float Chinese_grade;6
float sum_grade;7
char level;8
}
;
//
20
9
10
struct
st211
{12
char level;13
short number;14
float math_grade;15
float Chinese_grade;16
float sum_grade;17
}
;
//
16
18
19
#pragma pack(
1
)20
struct
st321
{22
char level;23
short number;24
float math_grade;25
float Chinese_grade;26
float sum_grade;27
}
;
//
15
28
#pragma pack() 29
30
void
TestStructSizeOf()31
{32
cout << __FUNCTION__ << endl;33
34
cout << " sizeof(st1)= " << sizeof (st1) << endl;35
cout << " offsetof(st1,number) " << offsetof(st1,number) << endl;36
cout << " offsetof(st1,math_grade) " << offsetof(st1,math_grade) << endl;37
cout << " offsetof(st1,Chinese_grade) " << offsetof(st1,Chinese_grade) << endl;38
cout << " offsetof(st1,sum_grade) " << offsetof(st1,sum_grade) << endl;39
cout << " offsetof(st1,level) " << offsetof(st1,level) << endl;40
41
cout << " sizeof(st2)= " << sizeof (st2) << endl;42
cout << " offsetof(st2,level) " << offsetof(st2,level) << endl;43
cout << " offsetof(st2,number) " << offsetof(st2,number) << endl;44
cout << " offsetof(st2,math_grade) " << offsetof(st2,math_grade) << endl;45
cout << " offsetof(st2,Chinese_grade) " << offsetof(st2,Chinese_grade) << endl;46
cout << " offsetof(st2,sum_grade) " << offsetof(st2,sum_grade) << endl;47
48
49
cout << " sizeof(st3)= " << sizeof (st3) << endl;50
cout << " offsetof(st3,level) " << offsetof(st3,level) << endl;51
cout << " offsetof(st3,number) " << offsetof(st3,number) << endl;52
cout << " offsetof(st3,math_grade) " << offsetof(st3,math_grade) << endl;53
cout << " offsetof(st3,Chinese_grade) " << offsetof(st3,Chinese_grade) << endl;54
cout << " offsetof(st3,sum_grade) " << offsetof(st3,sum_grade) << endl;55
}
输出结果:
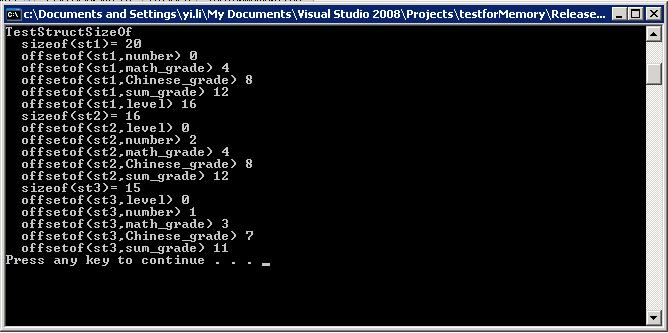
3.内存对齐
仔细查看上面的输出结果,会发现同样的结构体定义仅仅是成员顺序不同, 就会造成结构体大小的变化,这就是内存对齐的结果,在计算机的底层进行内存的读写的时候,如果内存对齐的话可以提高读写效率,下面是VC的默认的内存对齐规则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍, 如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
当然VC提供了工程选项/Zp [1|2|4|8|16]可以修改对齐方式,当然我们也可以在代码中对部分类型实行特殊的内存对齐方式,修改方式为#pragma pack( n ),n为字节对齐
数,其取值为1、2、4、8、16,默认是8,取消修改用#pragma pack(),如果结构体某成员的sizeof大于你设置的,则按你的设置来对齐。
第二章 虚表, 多态与动态绑定
Key words: Virtual Table, polymiorphism
开篇说明一下,由于只能工作间歇写博客,时间仓促,上一篇文章代码引用 梦在天涯 的代码没有注明,特此表示歉意,引用已经加在标题下方,梦在天涯 的文章在如下地址,http://cnblogs.com/itech,写得全面,我的就当是补充吧
1.虚表-Virtual Table 多态-polymiorphism
虚函数表由虚函数的地址组成,表中函数地址的顺序和它们第一次出现的顺序(即在类定义的顺序)一致。若有重载的函数,则替换掉基类函数的地址,事实上你可以简单的将虚表定义理解如下:
Int* virtualTable[size]//普通的指针数组而已
多数情形下,MSVC的类按如下格局分布:
指向虚函数表的指针(_vtable_或_vftable_),不过它只在类包括虚函数,以及不能从基类复用合适的函数表时才会被添加。
基类。
函数成员。
请看如下例子:
#include
"
stdafx.h
"
#include
"
assert.h
"
#include
"
iostream
"
using
namespace
std;
class
A
{public: int b1; static int b3; int b2;public: virtual void A_virt1() {
{ std::cout<<" call of first A's vf"<<std::endl;
std::cout<<" call of first A's vf"<<std::endl; } virtual void A_virt2() { std::cout<<" call of second A's vf"<<std::endl; }}
;
int
A::b3
=
100
;
//
#pragma pack(1)
class
B:
public
A
{ int a1; char b1; float c1; virtual void A_virt2() { std::cout<<" call of second B's vf"<<std::endl; } virtual void B_virt1() { std::cout<<" call of second B's vf1"<<std::endl; } virtual void B_virt2() { std::cout<<" call of second B's vf2"<<std::endl; } void getsome();}
;
void
B::getsome()
{ int a=1;}
class
D:
public
A
{}
;
class
C:
public
B,
public
D
{ virtual void B_virt1() { std::cout<<" call of first C's vf"<<std::endl; }}
;
int
_tmain(
int
argc, _TCHAR
*
argv[])
{ typedef void(*pfunc)(); cout<<"test the class memory layout-virtual table"<<endl; C cc; (pfunc(((int**)(&cc))[0][0]))(); (pfunc(((int**)(&cc))[0][1]))(); (pfunc(((int**)(&cc))[0][2]))(); (pfunc(((int**)(&cc))[0][3]))(); system("pause"); return 0;}
} virtual void A_virt2() { std::cout<<" call of second A's vf"<<std::endl; }}
;
int
A::b3
=
100
;
//
#pragma pack(1)
class
B:
public
A
{ int a1; char b1; float c1; virtual void A_virt2() { std::cout<<" call of second B's vf"<<std::endl; } virtual void B_virt1() { std::cout<<" call of second B's vf1"<<std::endl; } virtual void B_virt2() { std::cout<<" call of second B's vf2"<<std::endl; } void getsome();}
;
void
B::getsome()
{ int a=1;}
class
D:
public
A
{}
;
class
C:
public
B,
public
D
{ virtual void B_virt1() { std::cout<<" call of first C's vf"<<std::endl; }}
;
int
_tmain(
int
argc, _TCHAR
*
argv[])
{ typedef void(*pfunc)(); cout<<"test the class memory layout-virtual table"<<endl; C cc; (pfunc(((int**)(&cc))[0][0]))(); (pfunc(((int**)(&cc))[0][1]))(); (pfunc(((int**)(&cc))[0][2]))(); (pfunc(((int**)(&cc))[0][3]))(); system("pause"); return 0;}
程序输出结果:
以下是各个类在内存中的布局图
+---
0 | {vfptr}
4 | b1
8 | b2
+---
A::$vftable@:
| & A_meta
| 0
0 | & A::A_virt1
1 | & A::A_virt2
A::A_virt1 this adjustor: 0
A::A_virt2 this adjustor: 0
class B size( 24 ):
+---
| +--- ( base class A)
0 | | {vfptr}
4 | | b1
8 | | b2
| +---
12 | a1
16 | b1
| < alignment member > (size = 3 )
20 | c1
+---
B::$vftable@:
| & B_meta
| 0
0 | & A::A_virt1
1 | & B::A_virt2
2 | & B::B_virt1
3 | & B::B_virt2
B::A_virt2 this adjustor: 0
B::B_virt1 this adjustor: 0
B::B_virt2 this adjustor: 0
class D size( 12 ):
+---
| +--- ( base class A)
0 | | {vfptr}
4 | | b1
8 | | b2
| +---
+---
D::$vftable@:
| & D_meta
| 0
0 | & A::A_virt1
1 | & A::A_virt2
class C size( 36 ):
+---
| +--- ( base class B)
| | +--- ( base class A)
0 | | | {vfptr}
4 | | | b1
8 | | | b2
| | +---
12 | | a1
16 | | b1
| | < alignment member > (size = 3 )
20 | | c1
| +---
| +--- ( base class D)
| | +--- ( base class A)
24 | | | {vfptr}
28 | | | b1
32 | | | b2
| | +---
| +---
+---
C::$vftable@B@:
| & C_meta
| 0
0 | & A::A_virt1
1 | & B::A_virt2
2 | & C::B_virt1
3 | & B::B_virt2
C::$vftable@D@:
| - 24
0 | & A::A_virt1
1 | & A::A_virt2
C::B_virt1 this adjustor: 0
为了调用虚函数,编译器首先需要从_vftable_取得函数地址,然后就像调用简单方法一样(例如,传入_this_指针作为隐含参数)。例如:
cc.A_virt2()
;esi = ptr [cc]
mov eax, [esi] ;fetch virtual table pointer
mov ecx, esi
call [eax+4] ;call second virtual method
;cc->B_virt1()
;edi = pC
lea edi, [esi+8] ;adjust this pointer
mov eax, [edi] ;fetch virtual table pointer
mov ecx, edi
call [eax] ;call first virtual method
注意到上面class A的内存布局图,首先是VT指针,然后是成员变量b1,b2, 而对于静态成员b3并没有体现,事实上b是存储在程序的全局静态数据区,供该类的所有实例共享,这里请注意在classA中虚表中虚函数出现的顺序和位置,这一点很重要,接着再看classB中虚函数出现的顺序和位置,注意到A_virt1,A_virt2在classA和classB中出现的顺序和位置一致,而所不同的是在classB的虚表中A_virt2已经被替换,这就是多态的关键所在,每一个虚函数本身其实不过是一个固定的偏移量,而真正实现多态的其实是在编译器的虚函数表的替换动作.
而对于多继承情况要复杂一些,例如在ClassC中每一个继承路径中都存在一个虚表,如果在没函数里再加入如下调用:
(pfunc(((int**)(&cc))[6][0]))();
(pfunc(((int**)(&cc))[6][1]))();
会输出:
call of first A's vf
call of second A' vf
这样一个类中同时存在两个一抹一样的函数,那么当你用
C cc;
cc.A_virt2()时会怎么样呢?
你会得到以下错误:
error C2385: ambiguous access of 'A_virt2'
解决办法有两种:
1. 调用时加入域操作符,例如:
cc.A::A_virt2();
cc.B::A_virt2( );
这种办法最稳妥也最清晰
2. 使用虚基类
代码改动如下:
class
B:virtual
public
A。。。。。。。
class
D:virtual
public
A。。。。。。。
int _tmain(int argc, _TCHAR* argv[])
{
。。。。。。。
(pfunc(((int**)(&cc))[0][0]))();
(pfunc(((int**)(&cc))[0][1]))();
//(pfunc(((int**)(&cc))[0][2]))();
//(pfunc(((int**)(&cc))[0][3]))();
//(pfunc(((int**)(&cc))[6][0]))();
//(pfunc(((int**)(&cc))[6][1]))();
cc.A::A_virt2();
cc.A_virt2();
。。。。。。。。
}
内存布局变为:
+---
| +--- ( base class B)
0 | | {vfptr}
4 | | {vbptr}
8 | | a1
12 | | b1
| | < alignment member > (size = 3 )
16 | | c1
| +---
| +--- ( base class D)
20 | | {vbptr}
| +---
+---
+--- ( virtual base A)
24 | {vfptr}
28 | b1
32 | b2
+---
C::$vftable@B@:
| & C_meta
| 0
0 | & C::B_virt1
1 | & B::B_virt2
C::$vbtable@B@:
0 | - 4
1 | 20 (Cd(B + 4 )A)
C::$vbtable@D@:
0 | 0
1 | 4 (Cd(D + 0 )A)
C::$vftable@A@:
| - 24
0 | & A::A_virt1
1 | & thunk: this -= 4 ; goto B::A_virt2
多了一个vbtable存储偏移量,第一个元素存储vbtable与该类的偏移量,第二个元素存储vbtable与公共基类的偏移量,而且注意到,vftable@A 的第二个虚函数被定向到B:A_virt2
这样问题解决了,但是你会得到一个警告:
Warning 1 warning C4250: 'C' : inherits 'B::B::A_virt2' via dominance
显示继承了 'B::B::A_virt2‘ ,也就是说你在调用
cc.A_virt2时,默认直接去调用B::A_virt2,这可能并不是你所期望的,所以使用时需要慎重
2 . 动态邦定与静态邦定
邦定是指一个计算机程序自身彼此关联的过程。按照邦定所进行的阶段不同,可分为两种不同的邦定方法:静态邦定和动态邦定。
静态邦定
静态邦定是指邦定工作出现在编译连接阶段,这种邦定又称早期邦定,因为这种邦定过程是在程序开始运行之前完成的。
在编译时所进行的这种邦定又称静态束定。在编译时就解决了程序中的操作调用与执行该操作代码间的关系,确定这种关系又称为束定,在编译时束定又称静态束定。
class
AA2
{3
public:4
void test()5
{6
cout<<"I am class AA!"<<endl;7
}8
}
;9
class
BB10
{11
public:12
void test()13
{14
cout<<"I am class BB!"<<endl;15
}16
}
;17
int
_tmain(
int
argc, _TCHAR
*
argv[])18
{19
AA *A=(AA *)(new BB);20
A->test();21
}
读者可以想一下以上例子的结果,如果说是I am class BB!
C++没有你想得那么职能,C++调用函数不过是指针偏移,而一般成员函数代码是在数据存储区的共享代码段,声明了AA类的指针 A 就已经指定了偏移的起点是类型AA的代码段起点,这一步就是所谓的动态邦定,而调用->test();只能得到I am class AA!
也许你要说我并没有实例化AA怎么会有那一段代码呢,请注意代码生成和实例化是完全不同的两个阶段,编译在编译时发现你调用了AA::test(); 那么就会载入相应的symbol,程序启动时就会载入相应代码段。
也许你还要说没有用继承的关系,那么你可以自己试验一下使BB继承自AA, 结果还是一样的
想要实现想要的结果唯一的方法就是使用虚函数来实现动态邦定.
附:堆栈详解
一、预备知识—程序的内存分配
一个由c/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表,呵呵。
3、全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 - 程序结束后有系统释放
4、文字常量区 —常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区—存放函数体的二进制代码。
二、例子程序
这是一个前辈写的,非常详细
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = "abc"; 栈
char *p2; 栈
char *p3 = "123456"; 123456在常量区,p3在栈上。
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, "123456"); 123456放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
二、堆和栈的理论知识
2.1申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2
申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活
2.5堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
比如:
#include <stdio.h>
void main()
{
char a = 1;
char c[] = "1234567890";
char *p ="1234567890";
a = c[1];
a = p[1];
return;
}
对应的汇编代码
10: a = c[1];
00401067 8A 4D F1 mov cl,byte ptr [ebp-0Fh]
0040106A 88 4D FC mov byte ptr [ebp-4],cl
11: a = p[1];
0040106D 8B 55 EC mov edx,dword ptr [ebp-14h]
00401070 8A 42 01 mov al,byte ptr [edx+1]
00401073 88 45 FC mov byte ptr [ebp-4],al
第一种在读取时直接就把字符串中的元素读到寄存器cl中,而第二种则要先把指针值读到edx中,在根据edx读取字符,显然慢了。
?
2.7小结:
堆和栈的区别可以用如下的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
堆和栈的区别主要分:
操作系统方面的堆和栈,如上面说的那些,不多说了。
还有就是数据结构方面的堆和栈,这些都是不同的概念。这里的堆实际上指的就是(满足堆性质的)优先队列的一种数据结构,第1个元素有最高的优先权;栈实际上就是满足先进后出的性质的数学或数据结构。
虽然堆栈,堆栈的说法是连起来叫,但是他们还是有很大区别的,连着叫只是由于历史的原因。














 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









