







一、异常数据挖掘简介:
异常数据挖掘,又称为离群点分析或者孤立点挖掘。在人们对数据进行分析处理的过程中,经常会遇到少量这样的数据,它们与数据一般模式不一致,或者说与大多数样相比有些不一样。我们称这样的数据为异常数据,对异常数据的处理在某些领域很有价值,例如在网络安全领域,可以利用异常数据挖掘来分析网络中的异常行为;在金融领域异常数据挖掘可以识别信用卡的欺诈交易、股市的操控行为、会计信息的虚假报价、欺诈贷款等。
异常数据挖掘其中又包含时间序列和非时间序列。非时间序列主要为发现异常的点集,其中各事件的发生无先后顺序,一般的探测手法为使用距离度量进行聚类、分类等操作,发现事件中的离群点。而时间序列各点、各时间的发生需要考虑先后顺序,各点、各事件之间存在一定的递推关系,对单个点进行挖掘分析并无太大的价值,因此挖掘需要考虑各事件之间的先后逻辑关系、递推关系,相对于非时间序列挖掘的难度更大,同时时间的跨度可以达到几年、几十年甚至更久。
举2个比较典型的时间序列分析的例子:1、对气象信息,受到季度、年份、太阳活动的影响,通常的挖掘分析需要考虑若干年的数据,2、又比如人体身体状况的预测告警,需要考虑的信息包括作息、饮食、各项身体指标、年龄等诸多维度的信息,而这些维度在时间上又是累计的,挖掘过程需要考虑这诸多维度信息之间的关系以及随着时间递推 各维度信息发生的微妙变化,进而发现可能即将发生的身体疾病进行提前预警。
二、时间序列异常数据挖掘几个常见算法:
(1)小波分析用于时间序列异常数据挖掘:小波的特点在于能够提供受分析序列在时间域、频率域上两个维度的特征,小波变换最初应用于信号滤波,因此使用者相对比较熟悉算法的原理及实现方式,后来引入时间序列分析,在机械故障诊断、供电系统分析等方面取得了很有的成效。但由于时间序列分析通常是实时性的,小波分析的计算量相对较大,因此限制了其在计算、硬件资源有限的移动设备上的应用。
(2)排列熵应用于时间序列异常数据挖掘:排列熵算法自2002年问世以来、便受到了学界、工业界的关注,该算法为度量时间序列复杂性的一种方法,由于很多正常时间序列受动力因素的影响,其序列往往简单、并具备一定的规律性,若系统失去动力驱动或者收到外界动力的扰动,信号也会变得扰动“不安”,这时其排列熵值出现上升。比如脑电受到个人意念思想的控制,其在时间维度上其电压值保持较为稳定、有规律的状态,而癫痫病人发作时,其脑电波变得混乱不堪,这时的熵值也维持在较高值。排列熵的简要计算过程如下:
设一维时间序列:
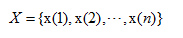
采用相空间重构延迟坐标法对X中任一元素x(i)进行相空间重构,对每个采样点取其连续的m个样点,得到点x(i)的m维空间的重构向量:
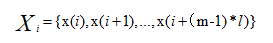
则序列X的相空间矩阵为:
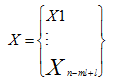
其中m和l分别为重构维数和延迟时间;
对x(i)的重构向量Xi各元素进行升序排列,得到:
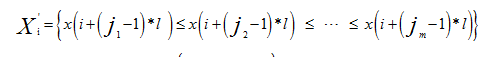
这样得到的排列方式为
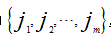

相对来说,排列熵的计算过程较为简洁,计算量主要为k次序列长度为m的全排序,在满足功能的前提下,窗口可以尽量的小,同时,窗口大小和延迟l值的大小选取非常重要。排列熵H的大小表征时间序列的随机程度,值越小说明该时间序列越规则,反之,该时间序列越具有随机性。在排列熵算法的基础上也可以发展出诸多使用熵值的对时间序列进行异常检测的算法,由于涉及工作内容,在此不多做阐述。
有关排列熵算法可以参考一下两篇论文:
1、Christoph Bandt、Bernd Pompe两位先生的:Permutation Entroy:A Natural Complexity Measure For Time Series
2、关于排列熵应用领域的介绍:Permutation Entropyand Its Main Biomedical and Econophtsics Application:A Review谷歌均有免费下载。
关于时间序列的数据挖掘分析,还有很多算法及方法,后面有空将陆续整理出来,共同学习。

















 9155
9155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









