






前言
时序数据异常检测是指在时间序列数据中识别出不符合预期模式的点或序列的过程。时序异常基于异常的特性和表现形式,可以分为"点异常","上下文异常","模式异常"三种类型;
本文介绍时序数据三种异常类型,及对应检测时序异常的技术路线;
1)本文重点:重点研究时序数据异常类型,及相应异常检测技术路线;
2)本文缺陷:不探讨具体异常检测方法,由于笔者才疏学浅,如有疏漏敬请指正。
一 点异常
显著有别于其他点的单点异常;属于空间异常,能够通过数值信息本身识别异常;
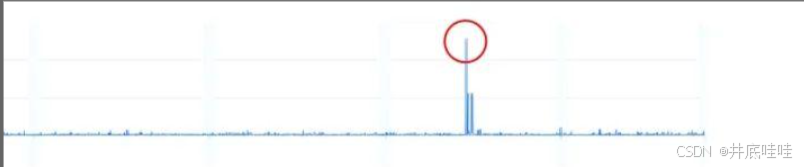
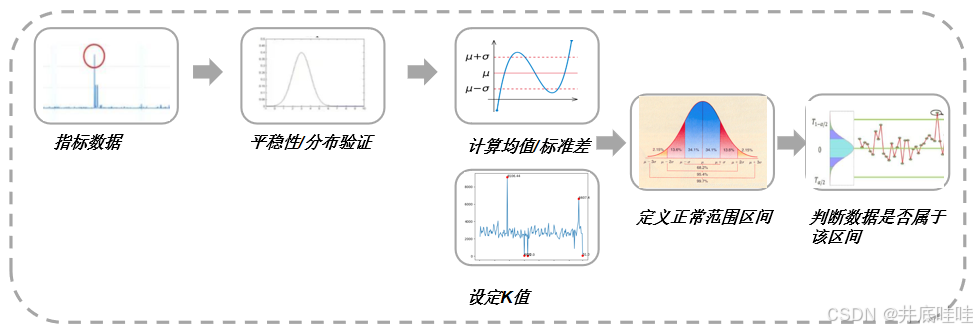
- 适用算法:统计类算法,如K-sigma, Boxplot, KDE, EVT等;此类算法不考虑数据点的时间信息;
- 算法基本假设:要求指标数据满足一阶平稳、数据噪声服从高斯分布、数据规律满足线性规律等;
- 优势:计算逻辑简洁,具有较高的计算性能;
- 劣势:对数据要求较高,因此适用的数据类型有限;
- 以K-sigma为例的点异常技术路线:
二 上下文异常
在指标数值上的正常变化范围内,但频率异常;

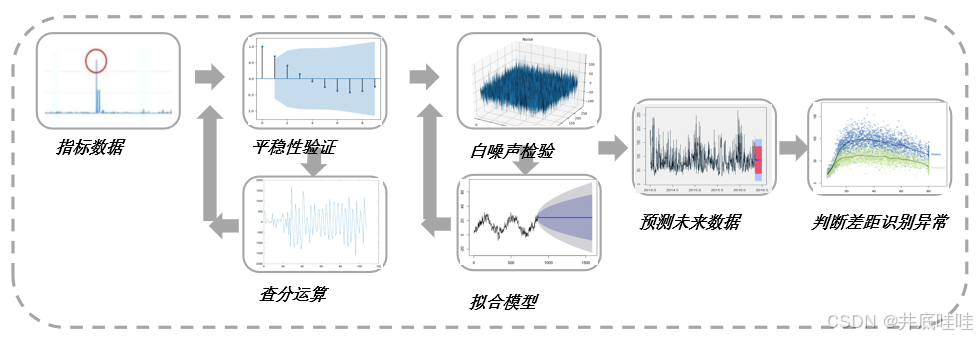
1.适用算法:时间序列算法,ARIMA, Holt-Winters, Prophet,STL等;旨在提取数据的趋势和周期性,适用于趋势或周期显著的数据类型;
2.算法基本假设:要求指标数据具有周期性、趋势性或季节性;趋势平稳符合线性变化;
3.优势:适用场景相对广泛、具有良好的可解释性;
4.劣势:预测误差受非时间因素影响,对数据要求较高,调参难度较高需要一定经验和专业知识;
5.以ARIMA为例的上下文异常识别技术路线
三 模式异常
在指标数值上的正常变化范围内,但模式变化;
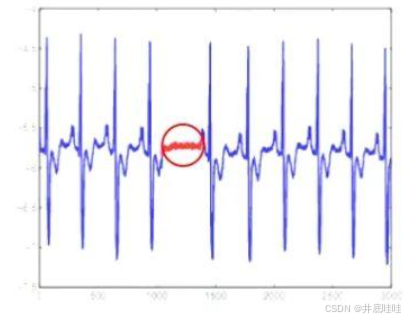
- 适用算法:机器学习算法如LOF, IForest, One-Class SVM, k-means;深度学习类算法如AE,VAE,LSTM,GAN等;用于提前指标特征,区分指标正常与异常情况下的不同特征表现;
- 算法基本假设:输入数据与输出数据间存在一定模式和关系;
3. 优势:基于大量数据和多个特征生成结果相对稳定,
4. 劣势:机器学习依赖特征工程、部分机器学习和深度学习可解释性差、有些模型计算资源要求高、需要标注数据且存在过拟合风险;
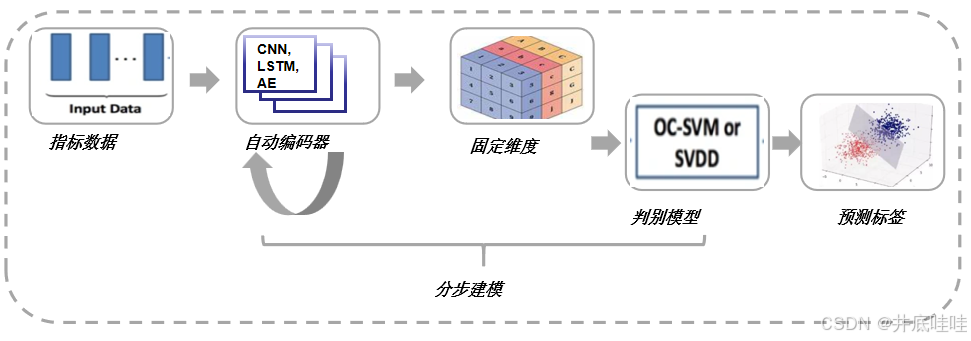
5.以深度学习和机器学习组合为例实现连续异常识别;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









