







- 编辑器
嗯,首先关于编辑python文件的工具,我因为怕麻烦,目前还在用Notepad++, 缺点就是提示功能比较弱,尤其如果是visual studio用得多了,那种随时有人给你纠错的感觉真不是一般的好呀。python对于空格之类的很敏感。
if result1:
print(result1.group())
else:
print('1匹配失败!')(这是一个不完整的程序,举个例子)
比如这样一个语句,如果print之前没有tab,程序运行后就会报错:
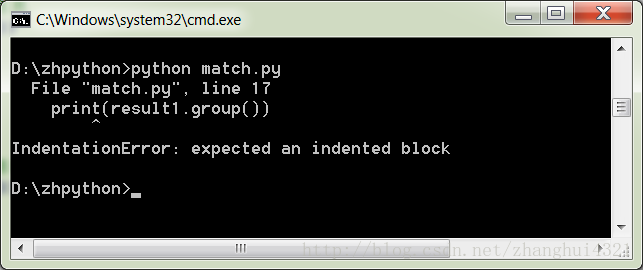
所以如果看到这种错误,就该检查一下自己的程序是不是不规范。
用Notepad++这种提示功能比较弱的编辑器也许就是能锻炼出更规范的程序书写。
如果实在没有办法忍受,推荐在Windows下面用PyCharm。当然,还有很多其他的http://www.oschina.net/news/57468/best-python-ide-for-developers,希望大家都能找到中意的那一款~~~
- Hello world
from urllib import request
print("hello world")
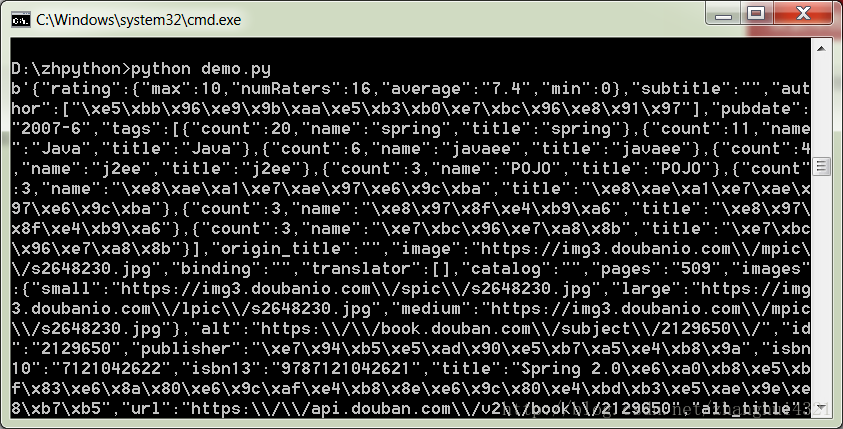
response=request.urlopen('https://api.douban.com/v2/book/2129650')
print(response.read())在这个hello world 里面我们可以感受一下第一次爬出一个网页的喜悦
- 抓取网页内容
抓取网页内容很大程度上是匹配的思想,就是你打开一个网页,F12 一下,总能看到一堆英文里面包裹着你想要的东西
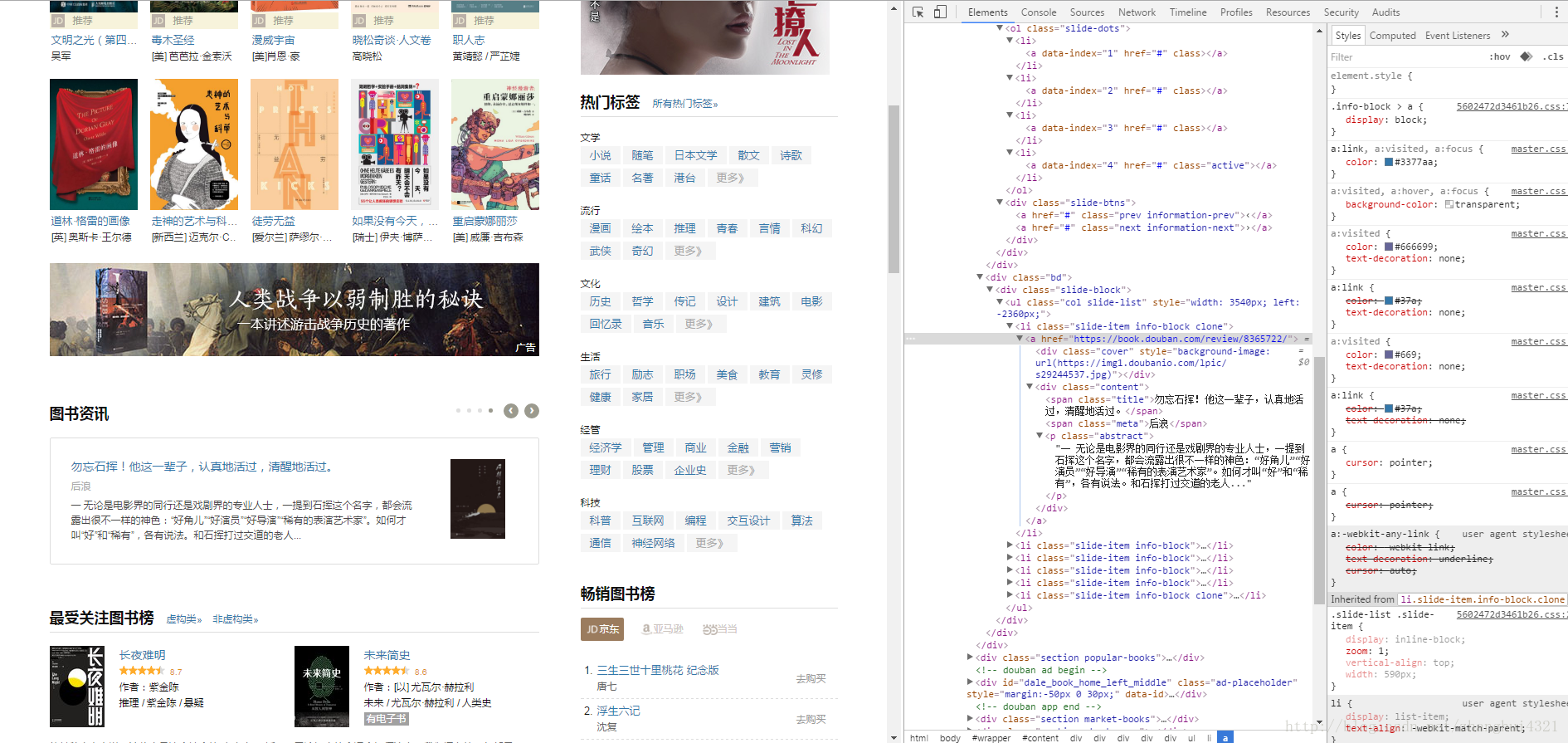
所以,我们要做的就是给出 “我们想得到的内容” 所处的上下文环境,来匹配出它们。
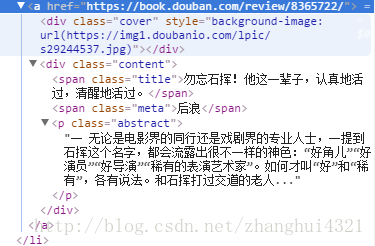
就比如在这一段里面,我们如果要找出汉字的部分,是不是只要定位出英文的部分,就能从其中挖出汉字。
<span class="title">************</span>***所带表的就是我们希望得到的 勿忘石挥!他这一辈子,认真地活过,清醒地活过。
(这个就是传说中的正则表达式的通俗理解,在我看来,正则表达是一个爬虫的灵魂,后面会有很多例子,慢慢就能感受到)
所以,学习一下match的用法吧~
# -*- coding: utf-8 -*-
#导入re模块
import re
# 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
pattern = re.compile(r'hello')
# 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern,'hello')
result2 = re.match(pattern,'helloo ZH!')
result3 = re.match(pattern,'helo ZH!')
result4 = re.match(pattern,'hello ZH!')
#如果1匹配成功
if result1:
# 使用Match获得分组信息
print(result1.group())
else:
print('1匹配失败!')
#如果2匹配成功
if result2:
# 使用Match获得分组信息
print(result2.group())
else:
print('2匹配失败!')
#如果3匹配成功
if result3:
# 使用Match获得分组信息
print(result3.group())
else:
print('3匹配失败!')
#如果4匹配成功
if result4:
# 使用Match获得分组信息
print(result4.group())
else:
print('4匹配失败!')下一章,我们就正式进入完整的初级爬虫程序














 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









