






学完xpath之后,就开始写第一个爬虫程序啦。。
step 1:在terminal中创建一个爬虫项目
scrapy startproject baidu baidu为项目名字,就可以生成项目的默认结构啦。
step 2: 在PC charm里打开项目
项目结构如图

查阅资料 各个py的内容如下:
init.py - 保持默认,不需要做任何修改
items.py - 自定义项目类的地方,也就是爬虫获取到数据之后,传入管道文件(pipelines.py)的载体
pipelines.py -项目管道文件,对传入的项目类中的数据进行清理和入库
settings.py - scrapy项目的设置文件,例如下载延迟,项目管道文件中类的启用以及自定义中间件的启用和顺序
spiders目录 -里面只有一个init.py 文件,在该目录下创建爬虫文件并继承scrapy.Spider
middlewares.py - 中间件配置文件
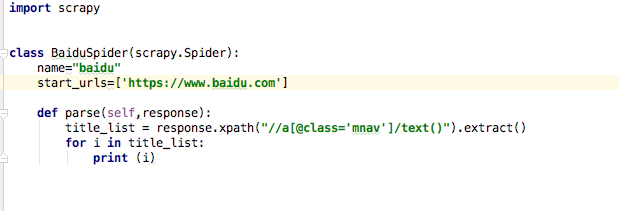
在新建的py文件里面首先要导入scrapy包,
创建自己的class类,class类要继承scrapy.Spider这个大类
类下面写name与start_urls name是爬虫的名字,如果项目中有多个爬虫,最好别重复了
start_urls 是爬虫启动后自动爬取的链接,列表内可以放很多链接
def parse(self,response):爬虫启动的时候,爬取链接成功后回调的函数,默认parse,参数self和response是必须的。
写完之后发现并没有爬取成功,报了 DEBUG: Forbidden by robots.txt: <GET http://weibo.com/p/10050583018062>
然后百度看了好久,原来是scrapy 默认检测 robots.txt ,看是否可以抓取,如果不行,就不能用了哦!
解决方案:解决办法是 在 setting.py 中:
''# Obey robots.txt rules
ROBOTSTXT_OBEY = True //设置为 False 即可















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









