







网站建设中,使用手机短信验证码可以有效防止无效用户的注册,验证用户身份真实性,提高网站会员质量和信息安全性。与此同时,如果网站中没有做好短信炸弹的防范,容易被短信炸弹恶意访问,不停发送验证码短信, 造成企业短信大量的无效发送,短信账户金额损失,更容易引起用户对网站的投诉,造成不必要的麻烦。
使用短信炸弹的不法分子,会事先把收集到的大量手机号,导入到短信轰炸平台,然后会输入一些直接可以填入手机号获取短信的网站链接,之后短信炸弹就会自动的不停访问,发送短信到导入的用户手机上。流程如下所示:

未做防范前短信发送示意图
如何防止短信炸弹的恶意发送呢?之所以能发送短信,是因为轰炸平台可以填写手机号,实现短信自动提交发送。如果在填写手机号获取短信之前,只需增加人工识别的识别码,比如:数字,字母或者汉字等图片识别码,就可以有效的阻止短信炸弹的自动填写,提高网站的规范性和安全性。这种情况下,只有用户才能进去到填写手机号获取短信的步骤,而将短信炸弹屏蔽。如下图所示:
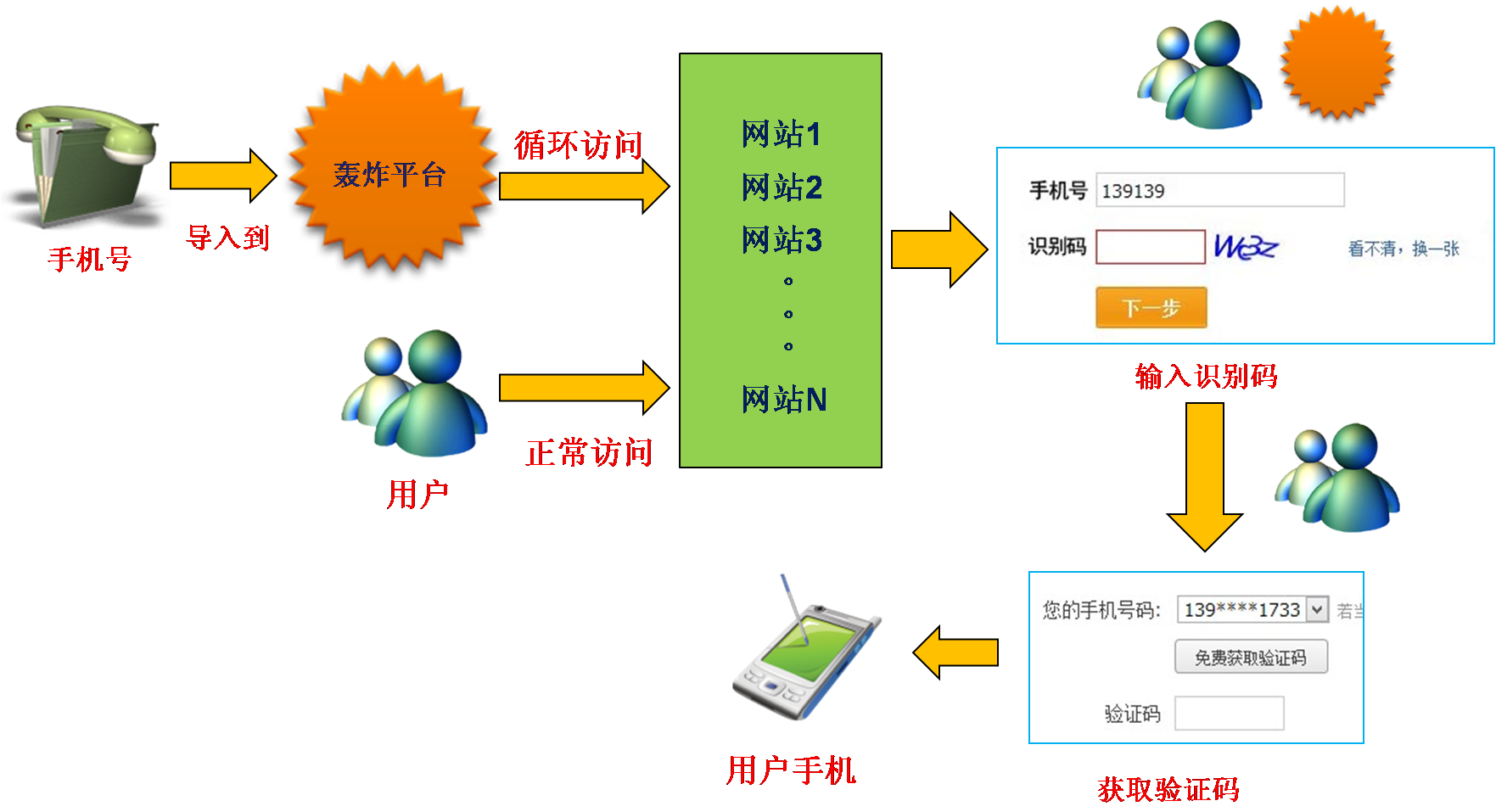
网站做防范后的短信发送示意图
使用短信炸弹发送骚扰短信是不法行为,严重的将会处以罚款和拘留处分。通过在输入手机号获取短信之前,增加人工识别的图片识别码等方式,可以有效屏蔽短信炸弹的侵扰,保障网站短信不会被白白浪费,提高网站用户体验和安全性。














 2247
2247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









