







书籍:
《神经网络与深度学习》讲义,邱锡鹏
《Neural Networks and Deep Learning》:
http://neuralnetworksanddeeplearning.com/
中文版《神经网络与深度学习》,美Michael Nielsen著,Freeman Zhang,Xiaohu Zhu著。
知乎:
https://zhuanlan.zhihu.com/p/22232836?refer=intelligentunit,
https://zhuanlan.zhihu.com/intelligentunit
image classification: 训练样本不足时,可以将图像旋转,翻转等进行调整,作为训练集
输入d1输出d2的层,权重为矩阵,维度为d1*d2: (d1,d2) × d1=> d2
如[784,30,10]表示各层神经元的数量,第一层有784个神经元,第二层有30个神经元,最后一层有10个神经元。
这样的网络结构总共有参数的个数为:N1(w)+N1(b)+N2(w)+N2(b) = (784*30+30)+(30*10+10)=23860
包含多层结构(两层或者更多隐藏层)的网络,被称为
深度神经网络。深度神经网络能够建起一个复杂的概念的层次
在训练过程中如果有迭代次数和学习速率两个参数,那么学习速率的设置会出现下面的情况:
学习速率过低,在设定迭代次数情况下未到底最小值处
每个隐藏层
a = {w1*z1+b,w2*z2+b,w3*z3+b,...,wn*zn+b},隐藏层中每个节点输出的为1个值(多个节点构成一个向量,继续作为后面层的输入), 如果输出层有多维,可以使用sigmoid函数或者softmax函数将每个z映射为一个值,使用激活函数得到输出σ(a1)、σ(a2)、....、σ(an),即输出向量为[σ(a1)、σ(a2)、....、σ(an)]。可以
将
softmax
想象成一种重新调节z的方法,然后将结果整合起来构成了一个概率分布,概率之和为1;
输出层时目标函数C是一个关于(x,y)的式子,在此基础上会计算输出和真实y的误差delta,带入x,y可以计算该层权重和偏置的更新值,利用bp算法反向更新w.
对于l层第j个node
激活值a:
整个l层的
激活向量:
令z为l层的
带权输入,表示如下:
则l层激活向量可以表示为:
l层j个node的带权输入为:
z为
带权输入,a是z经过激活函数后的映射值,激活函数Sigmoid
要求的目标函数:
1/2是为了求导方便,导数中会被约掉。即:
神经元的
误差的度量, 第l层第j个神经元的误差为:
该过程可以使用泰勒展开式来证明: C(z+delta(z)) = C(z)+C'(z)
==> C(z+delta(z)) - C(z) = C'(z)
输出层误差方程(最后一层,根据损失函数求):
其中:
则(符号是如何消去的, a-y or y-a???):
s ⊙ t 可以表示按元素的乘积,实际就是两个向量的乘积.
可以表示为:
使用下一层的误差来表示当前层的误差:
l+1层的误差沿着网络反方向移动
误差和对偏置的导数 完全一致
BP1是求最后一层误差
BP2反向更新误差
BP3更新偏置b
Bp4更新权重w
以上式子的证明参考《神经网络与深度学习》讲义
反向传播算法:
反向传播算法 + 梯度下降
进一步改进: 加入规范化:
原始损失函数C0,新的损失函数C:
导数:
反向传播:
b没有发生变化
w通过(1-ηλ/n)重新调整了权重,即
权重衰减。
正向传播求损失,反向传播回传误差
Sigmoid Function Analysis:
Sigmoid Function: δ
(x)=1/(1+Expr(-x))
导数: δ
'(x)=δ
(x)(1-δ
(x))
图像:
可以看出,当输入的x接近0或者接近1的时候,δ'(x)值很小趋近于0。在梯度下降法中,x~0或x~1时,会下降的非常缓慢,
梯度弥散。
考虑如下情景,一层神经网络,采用sigmoid函数,梯度下降法更新w,b,目标输入1输出0。
平方损失函数:
导数:
已经带入了y=0,x=1。
初始 w0=0.6,b0=0.9,随着迭代次数增加cost变化如下:
初始 w0=2.0,b0=2.0,随着迭代次数增加cost变化如下:
在第1个图中,cost下降的比较快;而在第2个图中,cost开始是缓慢下降的,原因在于w和b初始比较大,wx+b>1,从导数公式中可以看出,∂C/∂w和∂C/∂b会非常小,w,b下降的是比较慢的。
交叉熵损失函数:
仍然使用sigmoid激活函数,但是使用交叉熵损失函数。
这里
fi=δ,用a来表示δ(z):
可以看出交叉熵是非负的,a在(0,1)区间内。y越接近0C越小。求导得到最终结果形式:
从公式中看出,权重学习的速度受到δ(z)-y,即输出误差的控制。更大的误差,更快的学习速度。
下面是交叉熵的情况下,w0=0.6,b0=0.9和w0=2.0,b0=2.0的情况下 cost和epoch的变化情况:
交叉熵损失函数适用场景: 激活函数是sigmoid时。
这里区分a和z:
激活函数是对z进行处理,δ(z),z=wx+b,带权输入;
损失函数是对a进行处理,C=log(a),a=δ(z),输出状态;
softmax激活函数
带权输入z:
激活函数:
对数似然(log-likelihood)损失函数:
求导:
可以看出,和
交叉熵损失函数+S型激活函数效果是类似的。
ReLU( The Rectified Linear Unit ,修正线性单元)
在一定程度上可以解决梯度弥散的问题。
researchers found out that
ReLU layers
work far better because the network is able to train a lot faster (because of the computational efficiency) without making a significant difference to the accuracy.It also helps to alleviate the vanishing gradient problem, which is the issue where the lower layers of the network train very slowly because the gradient decreases exponentially through the layers (Explaining this might be out of the scope of this post, but see
here
and
here
for good descriptions).
初始权重的设置
w,b的设置可以根据独立高斯随机变量来设置,其被归一化为均值为0,标准差为1。(如果都初始化为0,会出现很多对称的点)
还可以按照如下方式设置:
(1)b可以都设置为0。
(2)w全部设置为1。
(3)w采用均值为0,标准差为1/sqrt(n)的高斯分布来初始化权重。这种方法通过实践证明能够加速模型的训练。可以看下面的对比图:
上面的图是N(0,1)分布,下面的是N(0,1/sqrt(n))分布,标准差为1/sqrt(n)的分布使产生的值更集中在中间区域(也就是权值之间差异变小)。
学习速率的影响
可以看出η=2.5设置太大,已经超越了谷底;η=0.25开始下降很快,后面很慢的逼近谷底;η=0.025逐步逼近谷底。
迭代次数
当准确率在一段时间内不再上升时终止。
规则花因子
超参数,从1.0开始尝试
Hessian技术
使用hessian技术优化最小化代价函数的过程
上面的方法都是全连接的技术:
卷积神经网络 CNN
特别适合图像分类。卷积demo:
http://cs231n.github.io/assets/conv-demo/
https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks-Part-2/ (包括part1和part2两部分)
Patch /Kernel /局部感受野(local recptive fields): 像是输入像素中的一个小窗口,每个感受野连接一个隐藏层神经元,在整个输入图像上交叉移动局部感受野。例如,输入图像28*28像素,5*5的局部感受野,那么隐藏层中就会有24×*24个神经元,一个
特征映射。
每一个特征映射的矩阵W是一个Filter,如W0,映射后的值为a=ΣX*W0,(RGB三种通道,对应位置映射值求和(查看demo)),最终得到的是一个矩阵,然后每个交给激活函数处理。
卷积核,
滤波器(Filter),共享权重和偏置(shared weights)
,隐藏神经元的每个使用相同的权重和偏置。意味着第一个隐藏层一个特征映射所有神经元检测完全相同的特征(输入图像的不同位置),要完成图像识别需要多个特征映射。这样做的好处就是减少参数的个数(1亿-->3.5w)。
池化(
Pooling): 混合层通常紧接着在卷积层之后使用,为的是简化从卷积层输出的信息,是一个凝缩的特征映射。实际是一个down sampling(下采样)操作,进一步缩小样本以及可以减缓过拟合。
Pooling的作用,
This serves two main purposes:
The first is that the amount of parameters or weights is reduced by 75%, thus lessening the computation cost.
The second is that it will control
overfitting
. This term refers to when a model is so tuned to the training examples that it is not able to generalize well for the validation and test sets.
池化技术有:
max-pooling(最大值池化):简单的输出2*2区域中的最大激活值。卷积层有24*24个神经元,混合后得到12*12个神经元。
average pooling: 输出2*2区域中的激活值均值。
L2 pooling(L2池化):取2*2区域中激活值的平方和的平方根
深度(
Depth, Feature Map)/神经元个数: 卷积核/特征映射的个数。
步长(
Stride):局部感受野每次滑动的划过多少步。
填充值(
zero-padding):在步长和局部感受野确定情况下,无法滑动完整个输入,在周边补0。
Valid Padding: 边界不补0
Same Padding: 边界补0
Dropout Layers:
参考Hinton paper:
https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf (2014年发表) wiki:
https://en.wikipedia.org/wiki/Convolutional_neural_network#Dropout
Dropout方法是用来防止过拟合。
Since a fully connected layer occupies most of the parameters, it is prone to
overfitting
. The
dropout
method
is introduced to prevent overfitting. At each training stage, individual
nodes
are either "dropped out" of the net with probability 1-p or kept with probability p, so that a reduced network is left; incoming and outgoing edges to a dropped-out node are also removed. Only the reduced network is trained on the data in that stage. The removed nodes are then reinserted into the network with their original weights.
一般CNN结构(不固定):
input-->[CONV->ReLU]*N-->POOL-->FC
FC: 全连接。
第一层卷积w可视化,一个小方格代表一个w。
递归神经网络 RNN
知乎关于RNN学习的回答:
https://www.zhihu.com/question/29411132
循环神经网络介绍参考:
Understanding LSTM Networks
http://colah.github.io/posts/2015-08-Understanding-LSTMs/,中文翻译:
http://blog.csdn.net/ycheng_sjtu/article/details/48792467
(其他翻译版本:
http://www.csdn.net/article/2015-11-25/2826323?ref=myread or or
http://www.jianshu.com/p/9dc9f41f0b29)
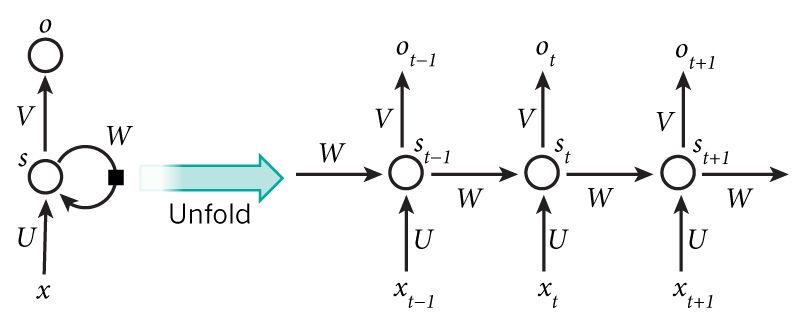
RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。
LSTM(长短记忆单元):
https://apaszke.github.io/lstm-explained.html
LSTM 就是把RNN的单元 换了更好的单元 就是加上了记忆。所以LSTM 长短期记忆网络。长期是通过遗忘门进行调节。 短期是通过记忆门进行调节。
The key to LSTMs is the cell state, the horizontal line running through the top of the diagram.
一个LSTM具有
3种门
,用以保护和控制细胞状态。
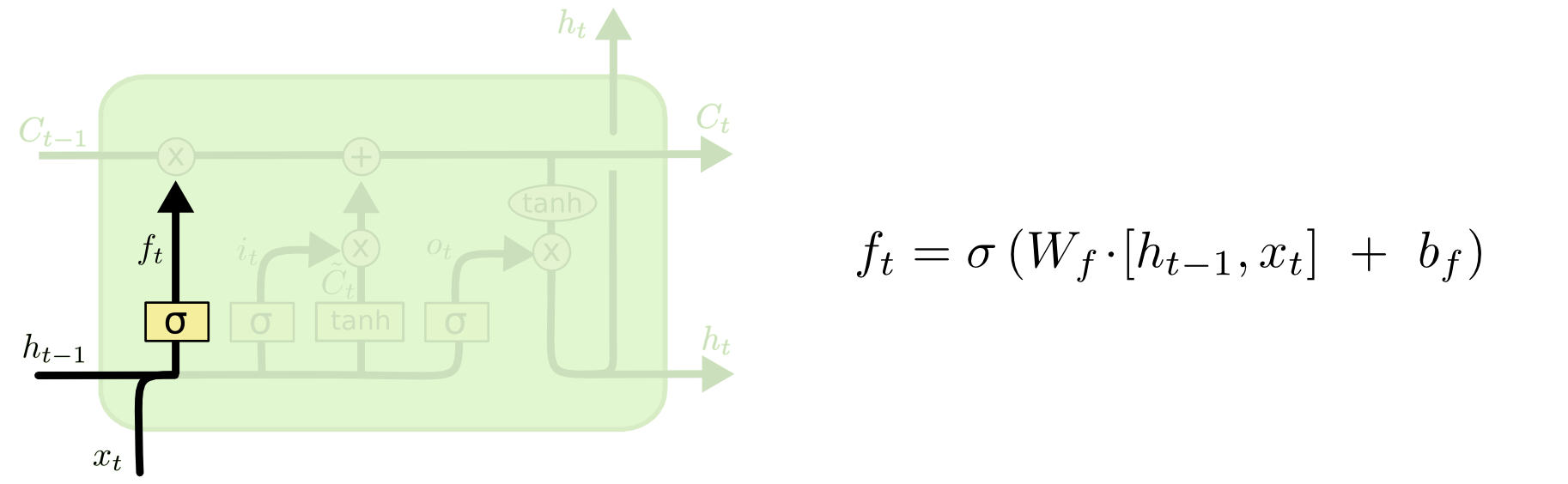
LSTM的第一步是决定我们要从细胞中
抛弃何种信息
。这个决定是由叫做『遗忘门』(
f
orget gate layer
)的sigmoid层决定的。它以
h
i
−1
和
x
i
为输入,在
C
t
−1
细胞输出一个介于0和1之间的数。其中1代表『完全保留』,0代表『完全遗忘』。
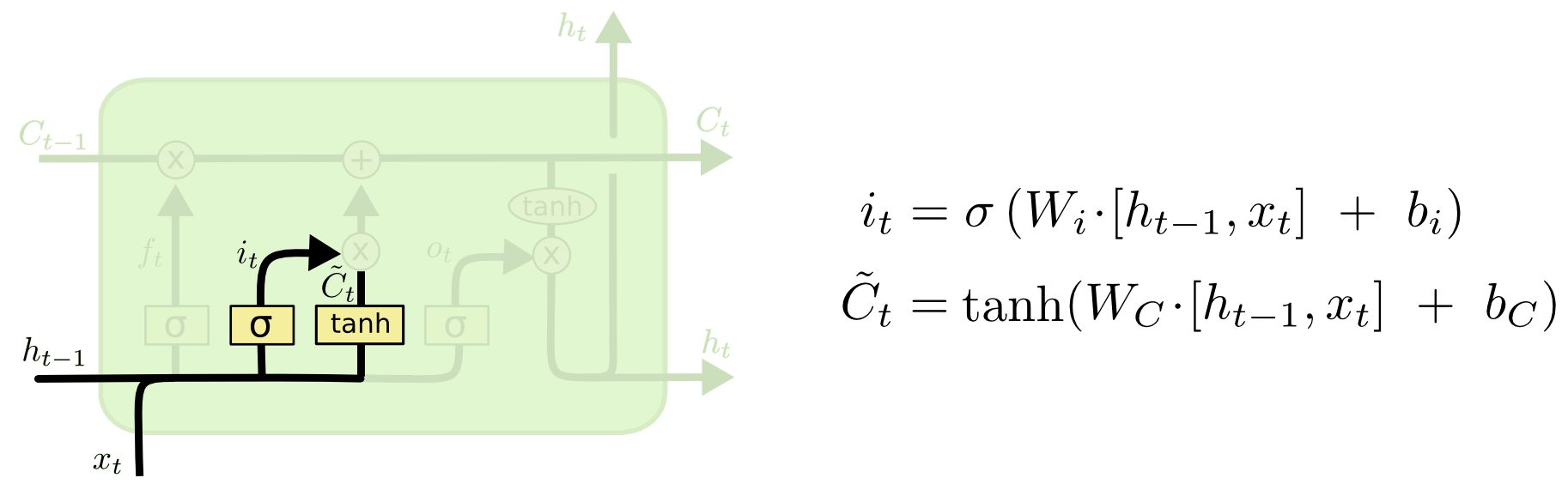
下一步是决定细胞中要
存储何种信息
。它有2个组成部分。首先,由一个叫做『输入门层』(
i
nput gate layer
)的sigmoid层决定我们将要更新哪些值。其次,一个tanh层创建一个新的候选向量
C
~
t
,它可以加在状态之中。在下一步我们将结合两者来生成状态的更新。
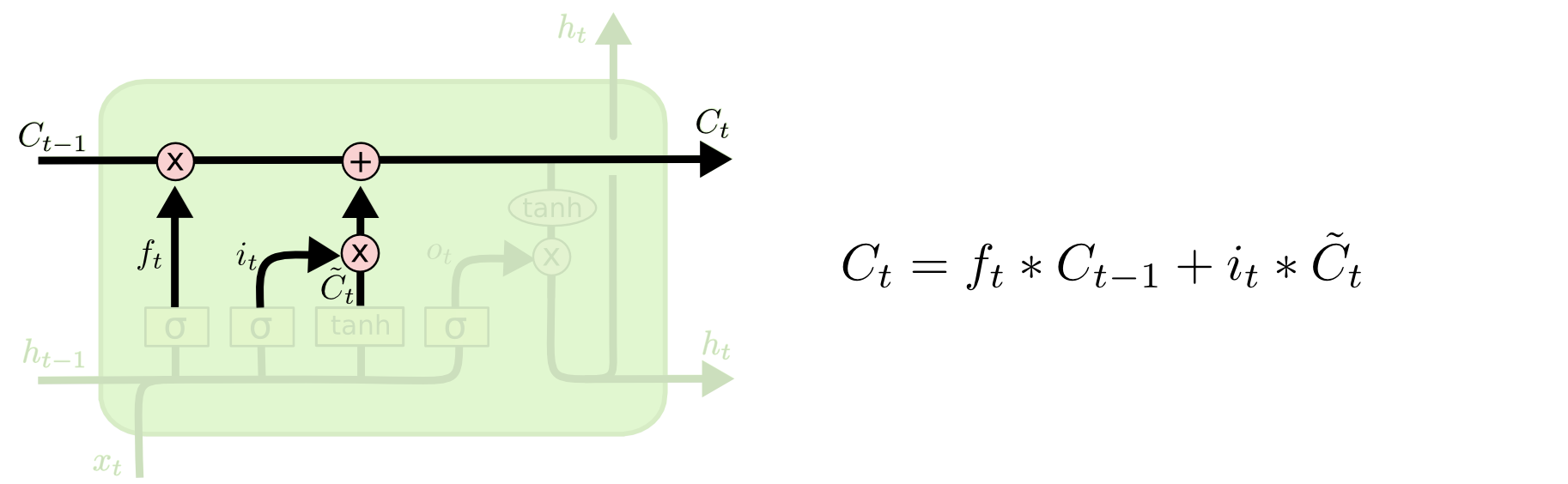
现在我们可以将旧细胞状态
C
t
−1
更新为
C
t
了。把
旧状态乘以
f
t
,用以遗忘之前我们决定忘记的信息。然后我们加上
i
t
∗
C
~
t
。这是新的候选值,根据我们决定更新状态的程度来作为放缩系数。
在语言模型中,这里就是我们真正丢弃关于旧主语性别信息以及增添新信息的地方,
如图所示
:
最终,我们可以决定输出哪些内容。输出取决于我们的细胞状态,但是以一个过滤后的版本。首先,我们使用sigmoid层来决定我们要输出细胞状态的哪些部分。然后,把用tanh处理细胞状态(将状态值映射到-1至1之间)。最后将其与sigmoid门的输出值相乘,从而我们能够输出我们决定输出的值。
如图所示
:
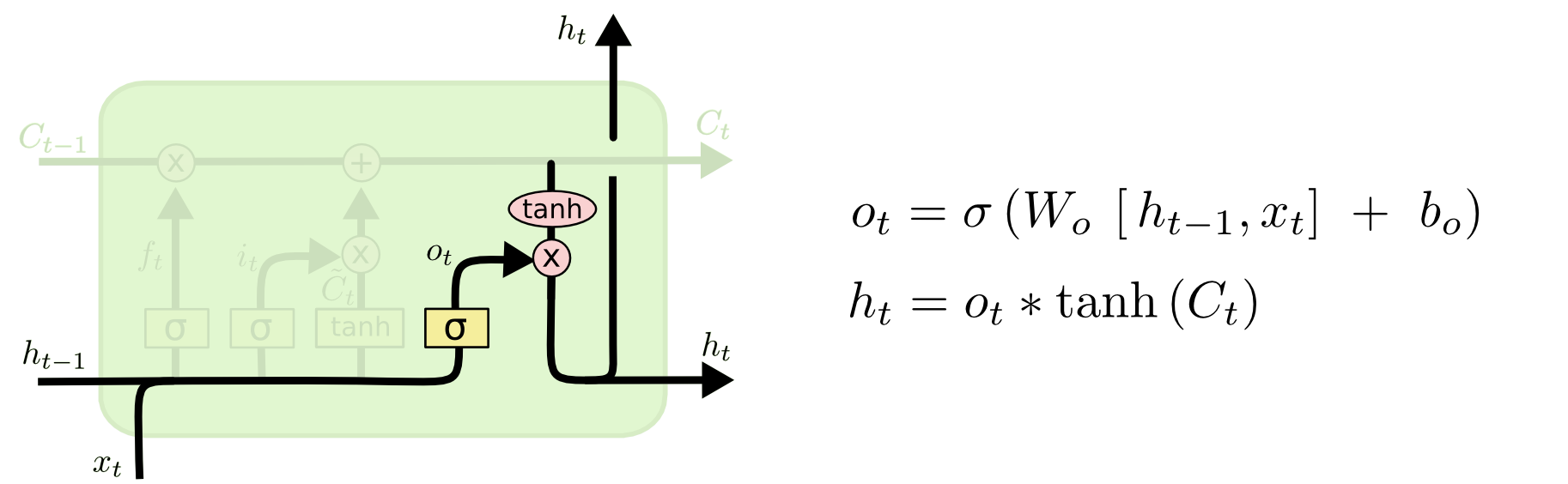
ht用来从上一层传入下一层,则下一层的输入为xt+1和ht+1。
此外,还有一些LSTM的其他变种形式,参考:
http://colah.github.io/posts/2015-08-Understanding-LSTMs/(
http://blog.csdn.net/ycheng_sjtu/article/details/48792467)
随着神经网络层数的增加,会出现梯度消失或者梯度爆炸的问题(vanishing gradient problem, exploding gradient problem)
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。
随着我们添加越来越多的隐含层,反向传播传递给较低层的信息会越来越少。实际上,由于信息向前反馈,不同层次间的梯度开始消失,对网络中权重的影响也会变小。
具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,
反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小
。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”.
反过来,若是
梯度
非常大,那乘积就是变得无比的大,也就
爆炸
了
解决:
用relu激活函数替换sigmoid或tanh(但又会有relu dying问题。。)
初始化较大的权重















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









