







在WEB网站的规模从小到大不断扩展的过程中,数据库的访问压力也不断的增加,数据库的架构也需要动态扩展,在数据库的扩展过程基本上包含如下几步,每一个扩展都可以比上一步骤的部署方式的性能得到数量级的提升。
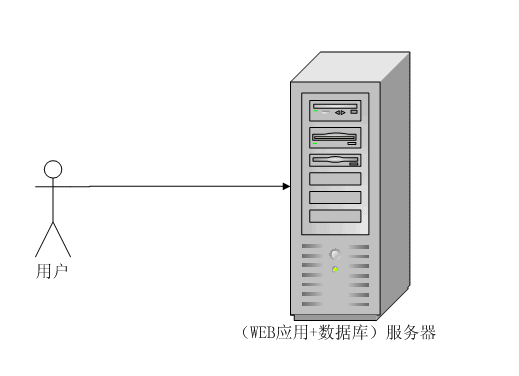
1、WEB应用和数据库部署在同一台服务器上
一般的小规模的网站采用这种方式,用户量、数据量、并发访问量都比较小,否则单台服务器无法承受,并且在遇到性能瓶颈的时候升级硬件所需要的费用非常高昂,在访问量增加的时候,应用程序和数据库都来抢占有限的系统资源,很快就又会遇到性能问题。
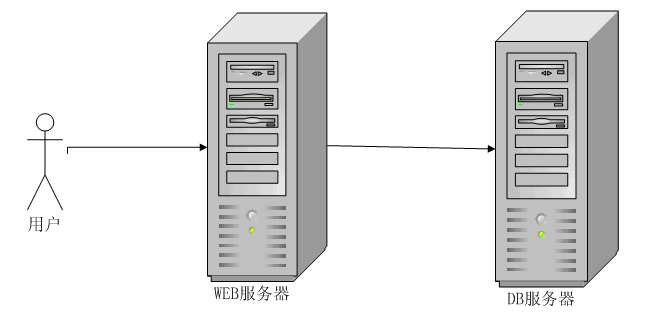
2、WEB应用和数据库部署在各自独立的服务器上
web应用和数据库分开部署,WEB应用服务器和数据库服务器各司其职,在系统访问量增加的时候可以分别升级应用服务器和数据库服务器,这种部署方式是一般小规模网站的典型部署方式。在将应用程序进行性能优化并且使用数据库对象缓存策略的情况下,可以承载较大的访问量,比如2000用户,200个并发,百万级别的数据量。
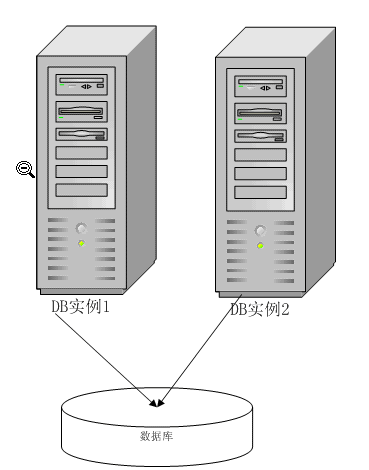
3、数据库服务器采用集群方式部署(比如Oracle的一个数据库多个实例的情况)
数据库集群方式能承担的负载是比较大的,数据库物理介质为一个磁盘阵列,多个数据库实例以虚拟IP方式向外部应用服务器提供数据库连接服务。这种部署方式基本上可以满足绝大多数的常见WEB应用,但是还是不能满足大用户量、高负载、数据库读写访问非常频繁的应用。
4、数据库采用主从部署方式
在面向大众用户的博客、论谈、交友、CMS等系统中,有上百万的用户,有上千万的数据量,存在众多的数据库查询操作,也有较多的数据库写操作,并且在多数情况下都是读操作远大于写操作的。在这个时候,假如能将数据库的读写操作分离的话,对于系统来讲是一个很大的提高啦。数据库的主从部署方式就走到我们面前啦。
主从复制:
几乎所有的主流数据库都支持复制,这是进行数据库简单扩展的基本手段。下面以Mysql为例来说明,它支持主从复制,配置也并不复杂,只需要开启主服务器上的二进制日志以及在主服务器和从服务器上分别进行简单的配置和授权。Mysql的主从复制是一句主服务器的二进制日志文件进行的,主服务器日志中记录的操作会在从服务器上重放,从而实现复制,所以主服务器必须开启二进制日志,自动记录所有对于主数据库的更新操作,从服务器再定时到主服务器取得二进制日志文件进行重放则完成了数据的复制。主从复制也用于自动备份。
读写分离:
为保证数据库数据的一致性,我们要求所有对于数据库的更新操作都是针对主数据库的,但是读操作是可以针对从数据库来进行。大多数站点的数据库读操作比写操作更加密集,而且查询条件相对复杂,数据库的大部分性能消耗在查询操作上了。
主从复制数据是异步完成的,这就导致主从数据库中的数据有一定的延迟,在读写分离的设计中必须要考虑这一点。以博客为例,用户登录后发表了一篇文章,他需要马上看到自己的文章,但是对于其它用户来讲可以允许延迟一段时间(1分钟/5分钟/30分钟),不会造成什么问题。这时对于当前用户就需要读主数据库,对于其他访问量更大的外部用户就可以读从数据库。
数据库反向代理:
在读写分离的方式使用主从部署方式的数据库的时候,会遇到一个问题,一个主数据库对应多台从服务器,对于写操作是针对主数据库的,数据库个数是唯一的,但是对于从服务器的读操作就需要使用适当的算法来分配请求啦,尤其对于多个从服务器的配置不一样的时候甚至需要读操作按照权重来分配。
对于上述问题可以使用数据库方向代理来实现。就像WEB方向代理服务器一样,MYsql Proxy同样可以在SQL语句转发到后端的Mysql服务器之前对它进行修改。
5、数据库垂直分割
主从部署数据库中,当写操作占了主数据库的CPU消耗的50%以上的时候,我们再增加从服务器的意义就不是很大了,因为所有的从服务器的写操作也将占到CPU消耗的50%以上,一台从服务器提供出来查询的资源非常有限。数据库就需要重新架构了,我们需要采用数据库垂直分区技术啦。
最简单的垂直分区方式是将原来的数据库中独立的业务进行分拆(被分拆出来的部分与其它部分不需要进行Join连接查询操作),比如WEB站点的BLOG和论坛,是相对独立的,与其它的数据的关联性不是很强,这时可以将原来的的数据库拆分为一个BLog库,一个论坛库,以及剩余的表所组成的库。这三个库再各自进行主从数据库方式部署,这样整个数据库的压力就分担啦。
另外查询扩展性也是采用数据库分区最主要的原因之一。将一个大的数据库分成多个小的数据库可以提高查询的性能,因为每个数据库分区拥有自己的一小部分数据。假设您想扫描1亿条记录,对一个单一分区的数据库来讲,该扫描操作需要数据库管理器独立扫描一亿条记录,如果您将数据库系统做成50个分区,并将这1亿条记录平均分配到这50个分区上,那么每个数据库分区的数据库管理器将只扫描200万记录。
6、数据库水平分割
在数据库的垂直分区之后,假如我们的BLOG库又再次无法承担写操作的时候,我们又该怎么办呢?数据库垂直分区这种扩展方式又无能为力了,我们需要的是水平分区。
水平分区意味着我们可以将同一个数据库表中的记录通过特定的算法进行分离,分别保存在不同的数据库表中,从而可以部署在不同的数据库服务器上。很多的大规模的站点基本上都是主从复制+垂直分区+水平分区这样的架构。水平分区并不依赖什么特定的技术,完全是逻辑村面的规划,需要的是经验和业务的细分。
如何分区呢?对于大型的WEB站点来说,必须分区,并且对于分区我们没有选择的余地,对于那些频繁访问导致站点接近崩溃的热点数据,我们必须分区。
在对数据分区的时候,我们必须要存在一个分区索引字段,比如USER_ID,它必须和所有的记录都存在关系,是分区数据库中的核心表的主键,在其它表中作为外键,并且在使用主键的时候,该主键不能是自增长的,必须是业务主键才可以。
余数分区:
我们可以将User_ID%10后的值为依据存入到不同的分区数据库中,该算法简单高效,但是在分区数据库个数有变动的时候,整个系统的数据需要重新分布。
范围分区:
我们可以将User_ID的范围进行分区,比如1-100000范围为一个分区数据库,100001-200000范围为一个分区数据库,该算法在分区数据库个数有变动的时候,系统非常有利于扩展,但是容易导致不同分区之间的压力不同,比如老用户所在的分区数据库的压力很大,但是新用户的分区数据库的压力偏小。
映射关系分区:
将对分区索引字段的每个可能的结果创建一个分区映射关系,这个映射关系非常庞大,需要将它们写入数据库中。比如当应用程序需要知道User_id为10的用户的BLOG内容在那个分区时,它必须查询数据库获取答案,当然,我们可以使用缓存来提高性能。
这种方式详细保存了每一个记录的分区对应关系,所以各个分区有非常强的可伸缩性,可以灵活的控制,并且将数据库从一个分区迁移到另一个分区也很简单,也可以使各个分区通过灵活的动态调节来保持压力的分布平衡。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









