







 本文详细描述了如何在配备M2Max/32GB的MacBookPro上通过VMware搭建Ubuntu22.04.2LTS环境,配置依赖,拉取并构建llama.cpp工具,下载并量化LLaMA-2中文模型,以及执行模型的过程,包括使用量化工具和示例应用。
本文详细描述了如何在配备M2Max/32GB的MacBookPro上通过VMware搭建Ubuntu22.04.2LTS环境,配置依赖,拉取并构建llama.cpp工具,下载并量化LLaMA-2中文模型,以及执行模型的过程,包括使用量化工具和示例应用。
尝试在macbook上部署LLaMA-2的中文模型的详细过程。
(1)环境准备
MacBook Pro(M2 Max/32G);
VMware Fusion Player 版本 13.5.1 (23298085);
Ubuntu 22.04.2 LTS;
给linux虚拟机分配8*core CPU 16G RAM。
我这里用的是16bit的量化模型,至少需要13G内存,如果4bit的只需要3.8G内存,当然上述不包含系统本身需要的内存。
(2)环境依赖
sudo apt update
sudo apt-get install gcc g++ python3 python3-pip
python3 -m pip install torch numpy sentencepiece(3)拉取llama.cpp工具并进行构建
在目录/home/zhangzk下:
git clone https://github.com/ggerganov/llama.cpp.git#安装依赖,llama.cpp 项目下带有 requirements.txt 文件
pip install -r requirements.txt#构建llama.cpp
cd llama.cpp/
make -j8(4)下载LLAMA2中文模型
这里下载 Chinese-Alpace-2-7B的指令模型,模型文件12.9G。
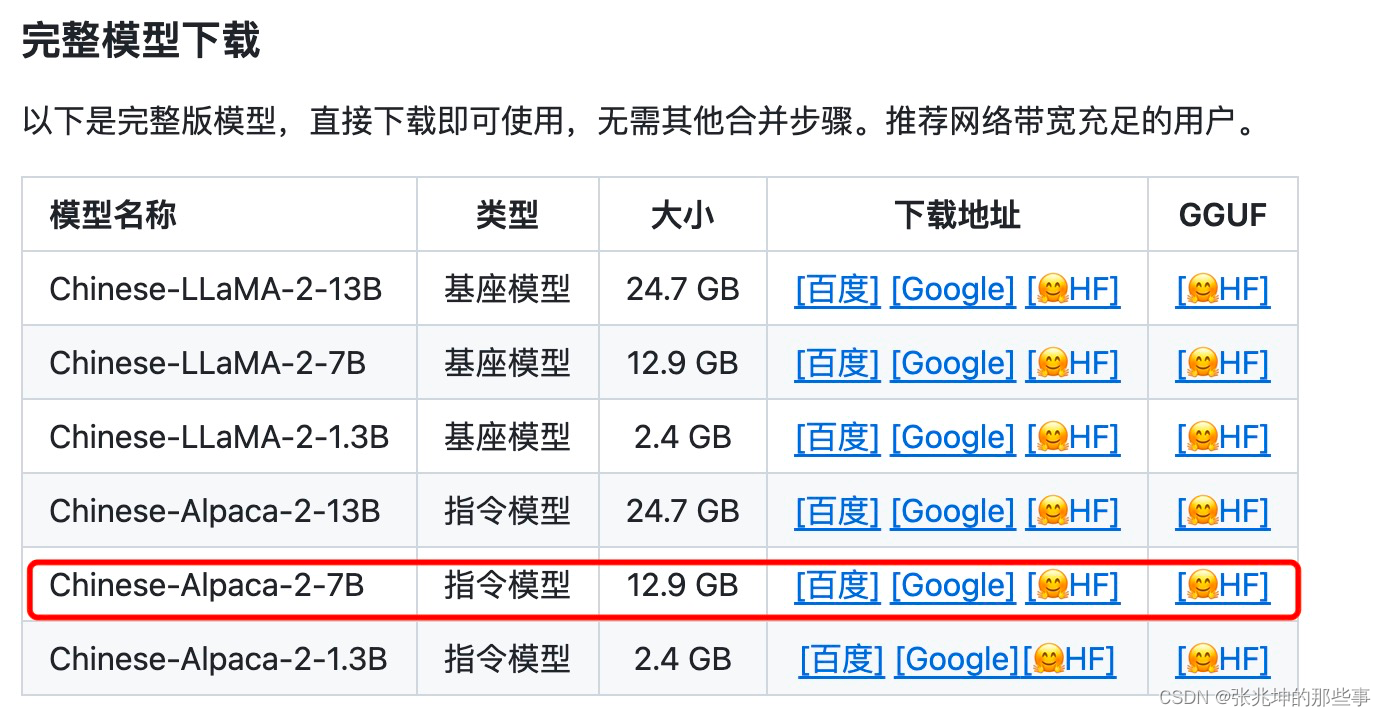
百度网盘那叫一个慢啊,没有会员能让你等死,还是梯子和GOOGLE网盘配合才叫一个快啊,几分钟的事。
把模型文件(共9个文件)都下载到 /home/zhangzk/llama.cpp/models/chinese-alpaca-2-7b-hf目录下。
(5)量化模型
在目录llama.cpp下执行:
#转换模型
python3 convert.py ./models/chinese-alpaca-2-7b-hf/
#16位量化
./quantize ./models/chinese-alpaca-2-7b-hf/ggml-model-f16.gguf ./models/chinese_7b_f16.gguf f16上述两步执行完会生成新文件llama.cpp/models/chinese_7b_f16.gguf
(6)启动模型
把Chinese-LLaMA-Alpaca-2/scripts/llama-cpp/chat.sh复制到llama.cpp目录下。
chmod +x chat.sh在目录llama.cpp下执行即可看到模型输出了:
./chat.sh models/chinese_7b_f16.gguf '中国北京有哪些著名的景点?'附1:QA例子
[INST] >
You are a helpful assistant. 你是一个乐于助人的助手。
>
中国北京有哪些著名的景点?
[/INST] 北京是中国的首都,拥有丰富的历史文化遗产和自然景观资源,以下是一些著名景点:
- 故宫博物院:中国古代皇宫建筑群,是明清两代皇帝的居所,保存了大量的文物和艺术品。
- 天坛公园:古代祭祀天地之场所,是中国现存规模最大、保存最完整的祭天文化遗产之一。
- 颐和园:中国传统皇家园林,被誉为"皇家园林博物馆",以其精美的建筑、湖泊和山水景观而闻名。
- 北京长城:中国古代防御工程的代表,是世界文化遗产,也是世界上最长的城墙。
- 北海公园:古代皇家园林之一,以碧波荡漾、荷花盛开、古树参天为特色,是中国最大的人工湖泊和岛屿园林。
- 圆明园:清代皇家园林,以其精美的建筑、精美的花园和珍贵文物而闻名于世,曾经是世界上最大的皇家园林。
- 北京鸟巢:2008年北京奥运会主体育场,是一座现代化体育场馆,也是北京市区的一个地标性建筑。
- 天安门广场:中国最大的城市广场之一,是中国政治和历史的重要场所,也是游客必去的地方。
- 王府井大街:北京的商业中心,拥有各种购物、餐饮和娱乐设施,是游客体验北京文化的好地方。
- 北京大学:中国的著名高等学府,以其美丽的校园建筑和悠久的历史而闻名于世。
附2: 查看quantize 提供各种精度的量化。
zhangzk@test-llm:~/llama.cpp$ ./quantize --help
usage: ./quantize [--help] [--allow-requantize] [--leave-output-tensor] [--pure] [--imatrix] [--include-weights] [--exclude-weights] model-f32.gguf [model-quant.gguf] type [nthreads]
--allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit
--leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing
--pure: Disable k-quant mixtures and quantize all tensors to the same type
--imatrix file_name: use data in file_name as importance matrix for quant optimizations
--include-weights tensor_name: use importance matrix for this/these tensor(s)
--exclude-weights tensor_name: use importance matrix for this/these tensor(s)
Note: --include-weights and --exclude-weights cannot be used together
Allowed quantization types:
2 or Q4_0 : 3.56G, +0.2166 ppl @ LLaMA-v1-7B
3 or Q4_1 : 3.90G, +0.1585 ppl @ LLaMA-v1-7B
8 or Q5_0 : 4.33G, +0.0683 ppl @ LLaMA-v1-7B
9 or Q5_1 : 4.70G, +0.0349 ppl @ LLaMA-v1-7B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
10 or Q2_K : 2.63G, +0.6717 ppl @ LLaMA-v1-7B
21 or Q2_K_S : 2.16G, +9.0634 ppl @ LLaMA-v1-7B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 2.75G, +0.5551 ppl @ LLaMA-v1-7B
12 or Q3_K_M : 3.07G, +0.2496 ppl @ LLaMA-v1-7B
13 or Q3_K_L : 3.35G, +0.1764 ppl @ LLaMA-v1-7B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 3.59G, +0.0992 ppl @ LLaMA-v1-7B
15 or Q4_K_M : 3.80G, +0.0532 ppl @ LLaMA-v1-7B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0400 ppl @ LLaMA-v1-7B
17 or Q5_K_M : 4.45G, +0.0122 ppl @ LLaMA-v1-7B
18 or Q6_K : 5.15G, +0.0008 ppl @ LLaMA-v1-7B
7 or Q8_0 : 6.70G, +0.0004 ppl @ LLaMA-v1-7B
1 or F16 : 13.00G @ 7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing















 7500
7500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









