







SA*****210 *明
进程是计算机中已运行程序的实体。程序本身只是指令的集合,进程才是程序(那些指令)的真正运行。进程也是一个可以执行的程序指令集;和该进程相关联的全部数据(包括变量,内存空间,缓冲区等等);程序的执行上下文
系统用一个叫做“进程表”的东西来维护中系统中的进程,进程表中的一个条目维护着存储着一个进程的相关信息,比如进程号,进程状态,寄存器值等等...
当分配给进程A的“时间片”使用完时,CPU会进行上下文切换以便运行其他进程,比如进程B,这里所谓的“上下文切换”,主要就是在操作那个“进程表”,其将进程A的相关信息(上下文)保存到其对应的进程表项中, 与之相反,其会从对应于进程B的进程表项中读取相关信息并运行之................
Linux操作系统提供了一个虚拟文件系统/proc用于实时的以文件的形式描述操作系统中正在运行的各进程的相关信息,截图如下所示:
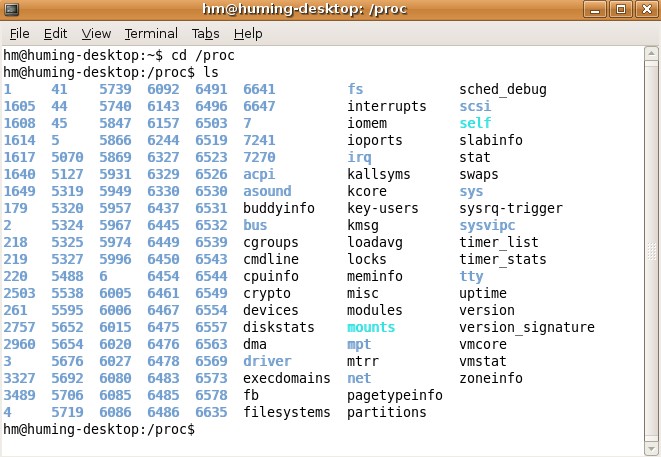
/proc中的所有文件如上图所示,其中每个数字命名的文件夹对应一个正在执行的进程,其中包含了进程的所有信息。
我们写一个小的无休止睡眠程序Sleep.cpp,代码如下:
#include<iostream>
using namespace std;
int main()
{
while(1)
sleep(10);
return 0;
}

结果为7387。进入目录/proc/7387,其中文件信息如下:

打开文件maps:
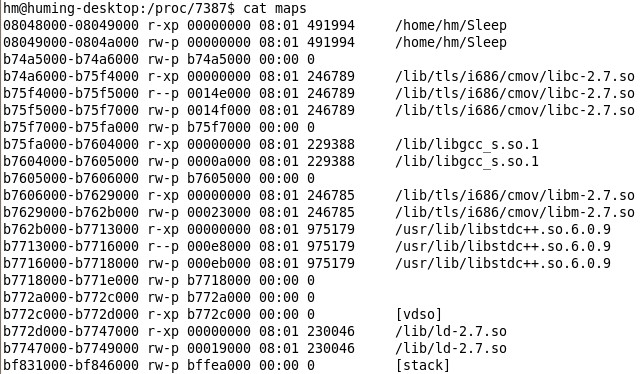
其中显示了该进程调用的各动态链接库及SleepELF代码相关信息,这里我暂且先不深入探讨下去。
通过阅读相关Blog和书籍可知,在Linux操作系统中,每个进程被分配了一个叫做“进程描述符”的结构体 task_struct ,用来对某个进程进行准确全面的描述,task_struct 在\linux-3.9.2\include\linux\Sched.h 中定义(由于代码段过长,不再粘贴)。其中定义了和进程相关的所有属性、标志位等信息。
task_struct 的结构如下图所示:
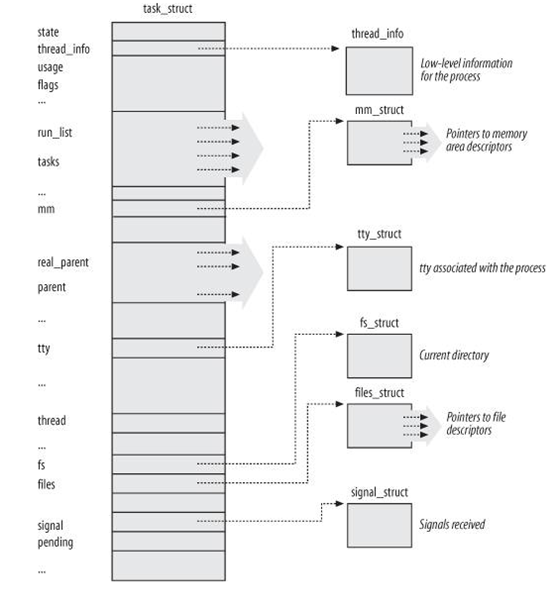
阅读其代码,发现其中有一段代码需要我们特别关注,如下:
struct mm_struct *mm, *active_mm;
这一行定义了两个mm_struct类型的指针,mm_struct和task_struct类似,这个结构体抽象描述了Linux视角下进程地址空间的所有相关信息,称为“内存描述符”。现在我们去读\linux-3.9.2\include\linux \mm_types.h中mm_struct的定义,代码如下(为了节省篇幅,我舍弃了与本文内容无关的代码段):
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* Shared pages (files) */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long nr_ptes; /* Page table pages */
<span style="font-size:12px;">unsigned long start_code, end_code, start_data, end_data;
<span style="white-space:pre"> </span>unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;</span>
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
struct uprobes_state uprobes_state;
};
结构体中使用stark_start/stark_end/mmap_base/brk/start_brk/end_data/start_data/end_code/start_code几个参数分别定义了进程储存空间中栈段,堆段,BSS段,数据段,代码段的起止起止,如下图所示:
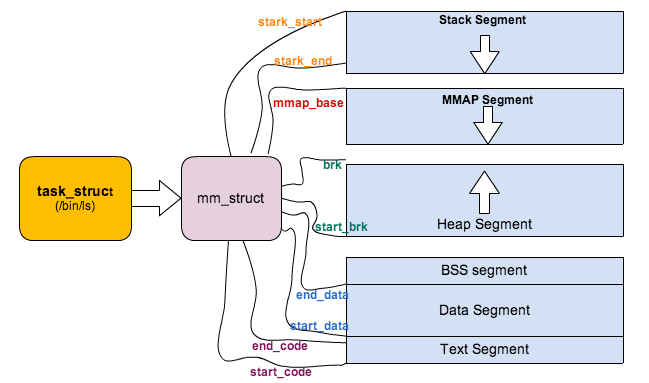
一、Linux操作系统中新进程的创建
下面,我会通过实验,逐步分析进程创建具体过程。
在Linux操作系统中,新进程是由旧进程创建的,比如说,进程parent新建了一个进程children,则进程表会多这样一个表项,该表项拥有一个唯一的ID,也就是进程号(pid),进程表项的其他值大部分与进程A的相同,具体说来,children和parent共享代码段,并且将parent的数据空间,堆栈等复制一份给children ,然后从parent创建children的地方开始运行。
从代码角度来看,创建一个新进程的函数声明如下:
#include<unistd.h>
pid_t fork(void);其中pid_t是表示“type of process id”的32位整数, 调用一次fork函数会返回两个返回值。至于函数的返回值,取决于在哪个进程中来检测该值,如果是在新创建的进程中,其为0;如果是在父进程中(创建新进程的进程),其为新创建的进程的id; 如果创建失败,则返回负值。
可以通过实验验证这个特性:
#include <stdio.h>
#include <unistd.h>
int main ()
{
printf("app start...\n");
pid_t id = fork();
if (id<0) {
printf("error\n");
}else if (id==0) {
printf("hi, i'm in new process, my id is %d \n", getpid());
}else {
printf("hi, i'm in old process, my id is %d \n", getpid());
}
return 0;
}

下面,我们进一步讨论fork(void)函数的具体执行过程。在linux-3.9.2\kernel\Fork.c中找到fork的定义处,发现其调用了do_fork()函数。而除了fork(),我们发现还有一个函数vfork()也能够实现创建新进程的功能。易知他和fork()函数一样调用了do_fork()函数,转入do_fork()函数中,得到代码如下:
/*
* Ok,this is the main fork-routine.
*
* It copies the process, and if successfulkick-starts
* it and waits for it to finish using the VMif required.
*/
longdo_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Do some preliminary argument and permissionschecking before we
* actually start allocating stuff
*/
if (clone_flags & (CLONE_NEWUSER |CLONE_NEWPID)) {
if (clone_flags &(CLONE_THREAD|CLONE_PARENT))
return -EINVAL;
}
/*
* Determine whether and which event to reportto ptracer. When
* called from kernel_thread or CLONE_UNTRACEDis explicitly
* requested, no event is reported; otherwise,report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)){
if (clone_flags &CLONE_VFORK)
trace =PTRACE_EVENT_VFORK;
else if ((clone_flags &CSIGNAL) != SIGCHLD)
trace =PTRACE_EVENT_CLONE;
else
trace =PTRACE_EVENT_FORK;
if(likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags,stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - thethread pointer
* might get invalid after that point, if thethread exits quickly.
*/
if (!IS_ERR(p)) {
structcompletion vfork;
trace_sched_process_fork(current,p);
nr = task_pid_vnr(p);
if (clone_flags &CLONE_PARENT_SETTID)
put_user(nr,parent_tidptr);
if (clone_flags &CLONE_VFORK) {
p->vfork_done =&vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and childstarted to run, tell ptracer */
if (unlikely(trace))
ptrace_event(trace,nr);
if (clone_flags &CLONE_VFORK) {
if(!wait_for_vfork_done(p, &vfork))
ptrace_event(PTRACE_EVENT_VFORK_DONE,nr);
}
} else {
nr = PTR_ERR(p);
}
return nr;
}通过阅读代码,我们可以得出函数的执行流程为:
-
通过查找pidmap_array位图,为子进程分配新的PID
-
检查父进程的ptrace字段(current->ptrace):如果它的值不等于0,说明有另外一个进程正在跟踪父进程,因而,do_fork()检查debugger程序是否自己想跟踪子进程(独立于由父进程指定的CLONE_PTRACE标志的值)。在这种情况下,如果子进程不是内核线程(CLONE_UNTRACED标志被清0),那么do_fork()函数设置CLONE_PTRACE标志。
-
调用copy_process()复制进程描述符。如果所有必须的资源都是可用的,该函数返回刚创建的task_struct描述符的地址。这是创建过程的关键步骤,将在do_fork()之后描述它。
-
如果设置了CLONE_STOPPED标志,或者必须跟踪子进程,即在p->ptrace中设置了PT_PTRACED标志,那么子进程的状态被设置成TASK_STOPPED,并为子进程增加挂起的SIGSTOP信号。在另外一个进程(不妨假设是跟踪进程或是父进程)把子进程的状态恢复为TASK_RUNNING之前(通常是通过发送SIGCONT信号),子进程将一直保持TASK_STOPPED状态。
-
如果没有设置CLONE_STOPPED标志,则调用wake_up_new_task()函数以执行下述操作:
a.调整父进程和子进程的调度参数
b.如果子进程将和父进程运行在同一个CPU上(当内核创建一个新进程时父进程有可能会被转移到另一个CPU上执行),而且父进程和子进程不能共享同一组页表(CLONE_VM标志被清0),那么,就把子进程插入父进程运行队列,插入时让子进程恰好在父进程前面,因此而迫使子进程先于父进程运行。如果子进程刷新其地址空间,并在创建之后执行新程序,那么这种简单的处理会产生较好的性能。而如果我们让父进程先运行,那么写时复制机制将会执行一系列不必要的页面复制。
c.否则,如果子进程与父进程运行在不同的CPU上,或者父进程和子进程共享同一组页表(CLONE_VM标志被置位),就把子进程插入父进程运行队列的队尾。
-
如果CLONE_STOPPED标志被置位,则把子进程置为TASK_STOPPED状态。
-
如果父进程被跟踪,则把子进程的PID存入current的ptrace_message字段并调用ptrace_notify()。ptrace_notify()是当前进程停止运行,并向当前进程的父进程发送SIGCHLD信号。子进程的祖父进程是跟踪父进程的debugger进程。SIGCHLD信号通知debugger进程:current已经创建了一个子进程,可以通过查找current->ptrace_message字段获得子进程的PID。
-
如果设置了CLONE_VFORK标志,则把父进程插入等待队列,并挂起父进程直到子进程释放自己的内存地址空间(也就是说,直到子进程结束或执行新的程序)。
-
结束并返回子进程的PID。
二、Linux操作系统中可执行程序的加载
在上文中已经说明,当启动一个新进程以后,新进程会复制父进程的大部份上下文并接着运行父进程中的代码,但如果我们使新进程不运行原父进程的代码,转而运行另外一个程序集中的代码,这就相当于启动了一个新程序。这里的代码我们可以理解成一个可执行程序。
所以,要运行一个新程序,需要最基本的两步:
1、创建一个可运行程序的环境,也就是进程。
2、将环境中的内容替换成你所希望的,也就是用你希望运行的可执行文件去覆盖新进程中的原有映像,并从该可执行文件的起始处开始执行。
要做到第一点,非常简单,fork函数就可以,要做到第二点,则可以利用exec函数族。
exec是一族函数的简称,包含在<unistd.h>中它们作用都一样,用一个可执行文件覆盖进程的现有映像,并转到该可执行文件的起始处开始执行。
原型如下:
intexecl(const char *path, const char *arg0, ... /*, (char *)0 */);
intexeclp(const char *file, const char *arg0, ... /*, (char *)0 */);
intexecle(const char *path, const char *arg0, ... /*, (char *)0, char *const envp[]*/);
intexecv(const char *path, char *const argv[]);
intexecvp(const char *file, char *const argv[]);
intexecve(const char *path, char *const argv[],char *const envp[]);
我们先以最简单的execl函数为例,其他的大同小异,其第一个参数path是可执行文件的路径,是绝对路径;从arg0参数开始及后面所有的是你要传递给可执行文件的命令行参数,值得注意的是,arg0是可执行文件本身,当然,不传程序本身或传一些乱七八糟的值并不代表不能通过编译或不能运行,只不过,如果可执行文件要用到arg0时会产生一些迷惑;最后有一个注释/*,(char*)0 */是提醒我们最后一个参数应该传空字符串。如何函数运行成功,则不会有任何返回值,否则返回-1,而具体的错误号会被设置在errno,errno是一个全局变量,用于程序设置错误号,跟win32的getLastError函数类似。
我们通过一个实验来验证execl()函数的使用(这里,我们通过execl函数加载ls -l命令):
#include <stdio.h>
#include <unistd.h>
int main ()
{
printf("app start...\n");
execl("/bin/ls", "/bin/ls", "-l",NULL);
printf("app end\n");
return 0;
}程序运行结果如图所示:
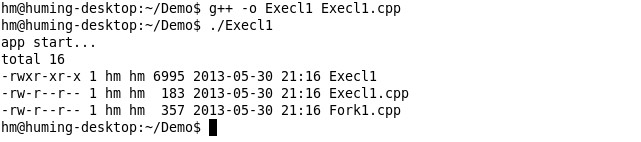
可以看出,我们运行了bin目录下的ls程序,参数arg0时ls程序本身路径,arg1为-l,使得其以列表的形式列举当前目录,ls程序运行成功了。但注意到了吗?没有输出“app end”这个字符串,原因很简单,我们没有新起进程,而是直接用ls程序覆盖了main函数所在的进程。
那我们接下来,试着用fork(),以免影响原进程。
#include <stdio.h>
#include <unistd.h>
int main ()
{
printf("app start...\n");
if(fork() == 0)
{
execl("/bin/ls", "/bin/ls", "-l", NULL);
}
printf("app end\n");
return 0;
}程序运行结果如图所示:
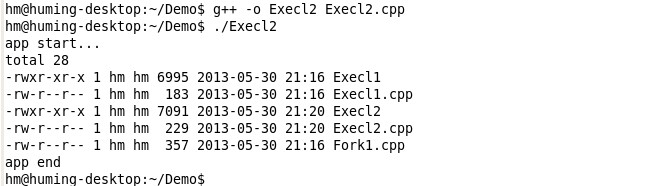
在这个实验中,我用fork创建了一个新进程,当其成功创建后(返回值为0),我们用execl来加载ls程序并运行之,可以看出,和之前的不同,这次程序输出我们希望的结果。
现在回过头来看除execl外的其他几个函数 :
intexeclp(const char *file, const char *arg0, ... /*, (char *)0 */);execlp和execl差不多,但区别在于前者会去系统环境变量查找file所指的程序的位置,所以如果通过环境变量能找到可执行文件,则file可以不是绝对路径了,比如execlp("ls", "ls", "-l", NULL);
intexecle(const char *path, const char *arg0, ... /*, (char *)0, char*const envp[]*/); 与execlp不同的是,其最后一个参数作为你自定义的环境变量参数传进去,而不是查找系统环境变量
char *env[]={ "HOME=/usr/home", "LOGNAME=home",(char *)0 };
execle("/bin/ls", "ls", "-l", NULL,env);
intexecv(const char *path, char *const argv[]);
intexecvp(const char *file, char *const argv[]);
intexecve(const char *path, char *const argv[], char*const envp[]);这三个函数和前面的三个类似,函数名由后缀l变成了v,其表达的含义是参数不再用参数列表传递而是用一个参数数组argv[],当然,数组最后一个元素也必须是char*0
名字这么相近的函数,感觉好容易混淆,那么就从l,v,p,e 这样的后缀来区分吧:
l:参数为一个逗号分隔的参数列表,并以char* 0作为列表结尾
v: 参数为字符串数组,数组的最后一个元素为char* 0
p: 可以通过系统环境变量查找文件位置
e:调用者显示传入环境变量
前面大概介绍了exec函数族,下面我们开始深入讨论可执行文件的加载过程。
首先,在Linux中,可执行文件被称为ELF文件,它具有两种固定的文件格式,如下图所示:
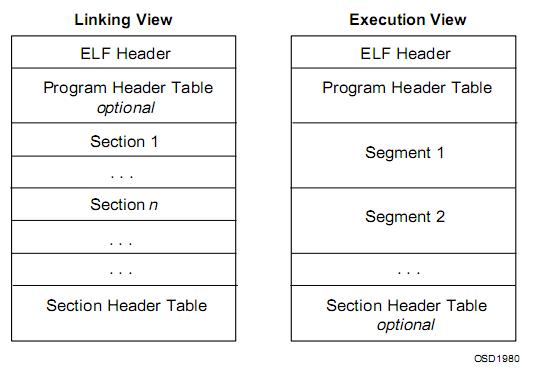
现对ELF文件进行简要说明:ELF文件包括三部分,ELF header,Program header table,Section header table.
ELF header:在文件的开始,保存了路线图,描述该文件的组织情况。
Program header table:告诉系统如何创建进程映像。用来构造进程映像的目标文件具有程序头部表,可重定位文件没有这个表。
Section header table:包含了描述文件节区的信息,每个节区在表中都有一个项,给出节区的名称、节区大小这类心里。用于链接的目标文件(可重定向文件)必须包含节区头部表,而可执行文件可以没有。
在Linux中,我们需要使用hexdump,objdump,readelf等工具来查看ELF文件格式。
具体分析如下:
我们使用readelf -h bin/ls命令阅读上面实验中ls的ELF文件,如下图所示:
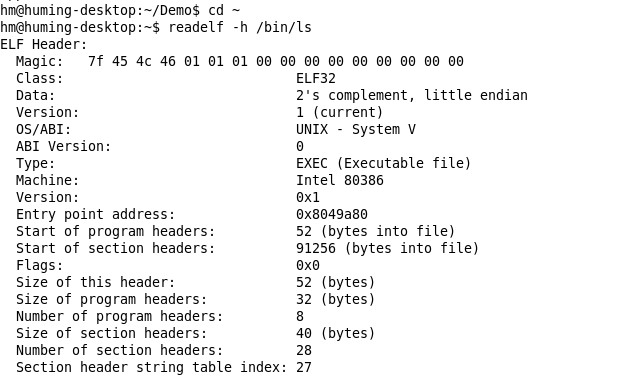
在图中,可以得出:
ELF header 的大小为52Bytes
Program header table的大小为32Bytes
下面,我们使用readelf -S命令读取ls的Section header table部分,如下图所示:
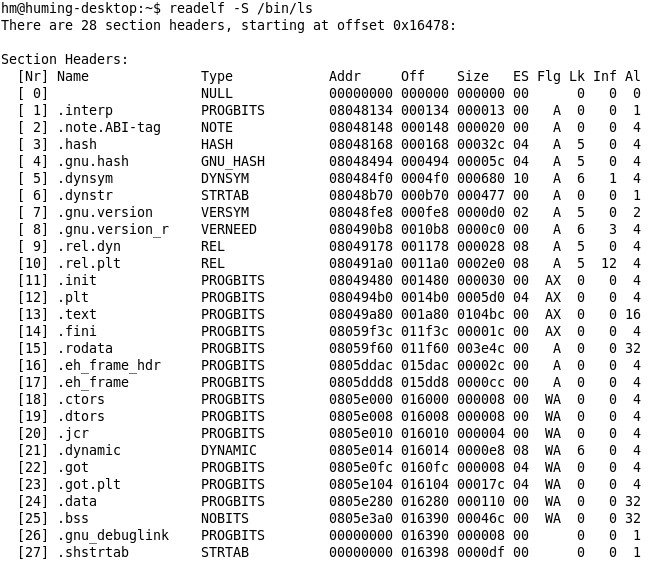
由上图可知,在一个ELF文件中有一个section header table,通过它可以定位到所有的section,而在ELF header中的e_shoff变量中保存section header table入口对文件头的偏移量。而每个section都会对应一个section header,所以只要在section header table中找到每个section header,就可以通过section header找到你想要的section。
以可执行文件execl为例,以保存字符串表的section为例来讲解读取某个section的过程。选择保存字符串表的section因为我们从ELF header中就可以得知它在section header table的索引值为27。
下面,我们具体讨论execl()函数的具体实现流程:
通过阅读execl()函数代码,可知exec系统调用在内核中的执行过程:
- exec系统调用要求以参数形式提供可执行文件名,并存储该参数以备将来使用。连同文件名一起,还要提供和存储其他参数,例如如果shell命令是"ls -l",那么ls作为文件名,-l作为选项,一同存储起来以备将来使用。
- 现在,内核解析文件路径名,从而得到该文件的索引节点号。然后,访问和读取该索引节点。内核知道对任何shell命令而言,它要先在/bin目录中搜索。
- 内核确定用户类别(是所有者、组还是其他)。然后从索引节点得到对应该可执行文件用户类别的执行(X)权限。内核检查该进程是否有权执行该文件。如果不可以,内核提示错误消息并退出。
- 如果一切正常,它访问可执行文件的头部。
- 现在,内核要将期望使用的程序(例如本例中的ls)的可执行文件加载到子进程的区域中。但"ls"所需的不同区域的大小与子进程已经存在的区域不同,因为它们是从父进程中复制过来的。因此,内核释放所有与子进程相关的区域。这是准备将可执行镜像中的新程序加载到子进程的区域中。在为仅仅存储在内存中的该系统调用存储参数后释放空间。进行存储是为了避免"ls"的可执行代码覆盖它们而导致它们丢失。根据实现方式的不同,在适当的地方进行存储。例如,如果"ls"是命令,"-l"是它的参数,那么就将"-l"存储在内核区。/bin目录中"ls"实用程序的二进制代码就是内核要加载到子进程内存空间中的内容。
- 然后,内核查询可执行文件(例如ls)镜像的头部之后分配所需大小的新区域。此时,建立区域表和页面映射表之间的链接。
- 内核将这些区域和子进程关联起来,也就是创建区域表和P区表之间的链接。
- 然后,内核将实际区域中的内容加载到分配的内存中。
- 内核使用可执行文件头部中的寄存器初始值创建保存寄存器上下文。
- 此时,子进程("ls"程序)已经运行。因此,内核根据子进程优先级,将其插到"准备就绪"进程列表的合适位置。最终,调度这个子进程。
- 在调度该子进程后,由前述(9)中介绍的保存寄存器上下文生成该进程的上下文。然后,PC、SP等就有了正确的值。
- 然后,内核跳转到PC指明的地址。这就是要执行的程序中第一个可执行指令的地址。现在开始执行"ls"这样的新程序。 内核从步骤(5)中存储的预先确定的区域中得到参数,然后生成所需的输出。如果子进程在前台执行,父进程会一直等到子进程终止;否则它会继续执行。
- 子进程终止,进入僵尸状态,期望使用的程序已经完成。现在,内核向父进程发送信号,指明"子进程死亡",这样现在就可以唤醒父进程了。
如果这个子进程打开新文件,那么这个子进程的用户文件描述符表、打开文件列表和inode表结构就和父进程的不同。如果该子进程调用另一个子程序,就会重复执行/分支进程。这样就会创建不同深度层次的进程结构。














 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









