







散列表
闲话散列表
一直以来,有用到Java中的HashMap、HashTable,知道它们是以散列表的结构实现数据存放,但到底什么是散列表,存储结构到底是怎么样子的,始终没有弄清楚过。
经过多方查询,最终找到一个好的例子来帮我们解释了到底散列表是什么东西,现引用一下。
我们以一个小故事来说明散列表的概念。
试想有这样的场景,我在学校很想学太极拳,听说学校有个叫张三丰的人打得特别好,于是就到学生处找人。学生处的工作人员可能会拿出学生名单,一个一个的査找, 最终告诉我,学校没这个人,张三丰几百年前就已经在武当山作古了。可如果找对了人,比如到操场上找那些爱运动的同学,他们会告诉我,“哦,你找张三丰呀,有有有,我带你去。”于是他把我带到了体育馆内,并告诉我,那个正在教大家打太极的小伙子就是“张三丰”,原来“张三丰”是因为他太极拳打得好而得到的外号。
数据结构的知识可以和生活上的事情类比,查找其实跟找人就很像。学生处的老师找张三丰,那就是顺序査找,依赖的是姓名关键字的比较。而通过爱好运动的同学询问时,没有遍历,没有比较,就凭他们“欲找太极‘张三丰’,必在体育馆当中”的经验,直接告诉你位置。
也就是说,我们只需要通过某个函数f,使得通过一个关键字就可以查找到需要的记录的存储位置,即
存储位置 = f(关键字)这就是一种散列技术。
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字对应一个存储位置f(key)。
我们在使用散列技术进行査找时,根据这个确定的对应关系找到给定值key的映射f(key),若査找集合中存在这个记录,则必定在f(key)的位置上。
这里我们把这种对应关系f称为散列函数,又称为哈希(Hash)函数。按这个思想,采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hashtable)。关键字对应的记录存储位置我们称为散列地址。
散列过程
整个散列过程其实就是两步:存储和查找。
在存储的时候,通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
就像张三丰我们就让他在体育馆,那如果是“爱因斯坦”我们让他在图书馆,如果是“居里夫人”,那就让她在化学实验室。如果是“巴顿将军”,这个打即时战略游戏的高手,我们可以让他到网吧。总之,不管什么记录,我们都需要用同一个散列函数计算出地址再存储。
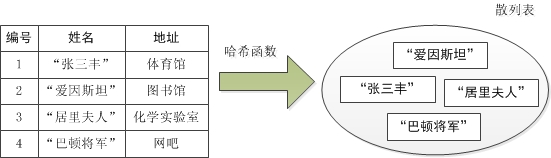
当査找记录时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。也就是说,在哪存的,上哪去找,由于存取用的是同一个散列函数,因此结果当然也是相同的。
所以说,散列技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向査找的存储结构。
散列表优缺点
散列技术最适合的求解问题是査找与给定值相等的记录。对于査找来说,简化了比较过程,效率就会大大提高。但万事有利就有弊,散列技术不具备很多常规数据结构的能力。
比如那种同样的关键字,它能对应很多记录的情况,却不适合用散列技术。一个班级几十个学生,他们的性别有男有女,你用关键字“男”去査找,对应的有许多学生的记录,这显然是不合适的。这个时候可以用班级学生的学号或者身份证号来散列存储,此时一个号码唯一对应一个学生才比较合适。
同样散列表也不适合范围查找,比如査找一个班级18-22岁的同学,在散列表中没法进行。想获得表中记录的排序也不可能,像最大值、最小值等结果也都无法从散列表中计算出来。
设计一个简单、均匀、存储利用率高的散列函数是散列技术中最关键的问题。我们在这儿不深究如何设计散列函数,实际上Object.hashCode()方法就是一个散列函数,用来计算散列值以实现散列表这种数据结构。
Hash冲突
在理想的情况下,每一个关键字,通过散列函数计算出来的地址都是不一样的,可现实中,却可能出现当key1 != key2时 f (key1) = f (key2)的现象,这种现象就叫冲突。
在这儿如何处理冲突不是我们的重点,所以感兴趣的读者可以自己查阅相关的资料。
使用Java实现散列表
下面我们来看一个例子,自己实现一个简单的散列表。当然,如果要深入了解散列表的具体实现,最好还是研究Java的源码。
package com.hash.demo;
/**
* 自定义的散列表类
*
* @author 小明
*
*/
public class MyHashTable<K, V> {
private final int CAPACITY = 1 << 8;
private Entry[] hashTable; // 哈希表,存放所有散列表记录的数组
private int count; // 记录个数
/**
* 初始化数组大小及记录个数
*/
public MyHashTable() {
this.hashTable = new Entry[CAPACITY];
this.count = 0;
}
/**
* 判断哈希表是否为空
*
* @return 是否为空(没有记录)
*/
public boolean isEmpty() {
return count == 0;
}
/**
* 清空哈希表
*/
public void clear() {
if (count > 0) {
// 循环遍历将每个数组元素置空
for (int i = 0; i < hashTable.length; i++) {
hashTable[i] = null;
}
count = 0; // 元素个数归0
}
}
/**
* 获取散列表大小
*
* @return 大小
*/
public int size() {
return this.count;
}
/**
* 根据关键字key获取散列码,大小不超过哈希表的大小
*
* @param key
* 关键字
* @return 散列码
*/
private int hash(K key) {
return Math.abs(key.hashCode());
}
/**
* 根据哈希码计算出在数组中的索引位置
*
* @param hash
* 哈希码
* @return 索引
*/
private int findIndex(int hash) {
return hash % hashTable.length;
}
/**
* 将key-value映射关联到哈希表中保存
*
* @param key
* 键
* @param value
* 值
* @return 如果之前在哈希表中存放了相同的关键字,则返回该关键字之前映射的value值,否则返回null
*/
public V put(K key, V value) {
int hash = hash(key); // 获取散列码
int index = findIndex(hash); // 找出数组中索引
// 如果索引处存在存放的元素,说明有冲突
// 循环的作用是判断冲突处是否是有重复的关键字,以便替换映射值
for (Entry<K, V> e = hashTable[index]; e != null; e = e.next) {
K k;
if (hash == e.hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// 获取索引处记录,如果原来未存放有,则为null,如果已存放,执行到此处则说明散列码有冲突但
// 关键字不同,以链表的方式保存记录值
Entry<K, V> e = hashTable[index];
hashTable[index] = new Entry<K, V>(key, value, e, hash);
count++; // 哈希表中保存的记录个数增加
return null;
}
/**
* 根据关键字获取映射的值
*
* @param key
* 关键字
* @return 映射值
*/
public V get(K key) {
int hash = hash(key); // 获取哈希码
int index = findIndex(hash); // 计算在数组中是索引
for (Entry<K, V> e = hashTable[index]; e != null; e = e.next) {
K k;
if (hash == e.hash && ((k = e.key) == key || key.equals(k))) {
return e.value;
}
}
return null;
}
/**
* 根据关键字移除映射值
*
* @param key
* @return
*/
public V remove(K key) {
int hash = hash(key); // 获取哈希码
int index = findIndex(hash); // 计算在数组中是索引
for (Entry<K, V> e = hashTable[index], pre = e; e != null; e = e.next) {
Entry<K, V> next = e.next; // 链表中下一个元素
K k;
// 如果比较到相同的关键字,则移除链表中的一个元素
if (hash == e.hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
count--; // 移除一个记录,则个数减少
if (pre == e){
hashTable[index] = next;
} else { // 记前一个元素的下一个指针指向下一个元素
pre.next = next;
}
return oldValue;
}
pre = e;
}
return null;
}
/**
* 用来表示Hash表中的一个记录,key-value(键-值对)信息保存在一个Entry对象中
*
* @author 小明
*
*/
class Entry<K, V> {
K key; // 键
V value; // 值
Entry<K, V> next; // Hash冲突时,使用链表保存下一个记录值
int hash; // 哈希码
public Entry(K key, V value, Entry<K, V> next, int hash) {
this.key = key;
this.value = value;
this.next = next;
this.hash = hash;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return value;
}
public void setValue(V value) {
this.value = value;
}
}
}这个实现只是简单地模拟了一下哈希表,可能算法并不严谨,仅供参考。更严谨的算法请大家参照JavaAPI中的HashMap。
测试:
package com.hash.demo;
public class Test {
public static void main(String[] args) {
MyHashTable<String, String> hashTable = new MyHashTable<String, String>();
hashTable.put("abc", "张三");
hashTable.put("abc2", "李四");
hashTable.put("abc", "李小四");
hashTable.put("k", "张小三");
hashTable.remove("k");
System.out.println(hashTable.size());
System.out.println(hashTable.get("abc"));
System.out.println(hashTable.get("abc2"));
System.out.println(hashTable.get("k"));
}
}运行结果:
2
李小四
李四
null














 8443
8443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









