







就那官方的例子来说明,代码基本上有注释
package com.lgh.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by Administrator on 2017/8/22.
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
//创建SparkConf对象,在这我指定master为local[2],
// 本地模式方便测试,另外需要注意,本地模式下local的必须大于等于2,否则就无法正确运行
//因为接收数据和处理数据需要两个线程。
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]");
//批处理间隔,每10s,创建Streaming
val ssc = new StreamingContext(sparkConf, Seconds(10))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
//构建数据源为socket,
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
//transform操作,数据转换
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//output操作,streaming中必须至少有一个output 操作
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
程序运行方法:
在linux主机192.168.53.100上执行 nc -lk 9999(有不明白的大家可以百度下nc的用法)然后开始输入单词。
在idea中传入参数192.168.53.100 9999,开始运行。
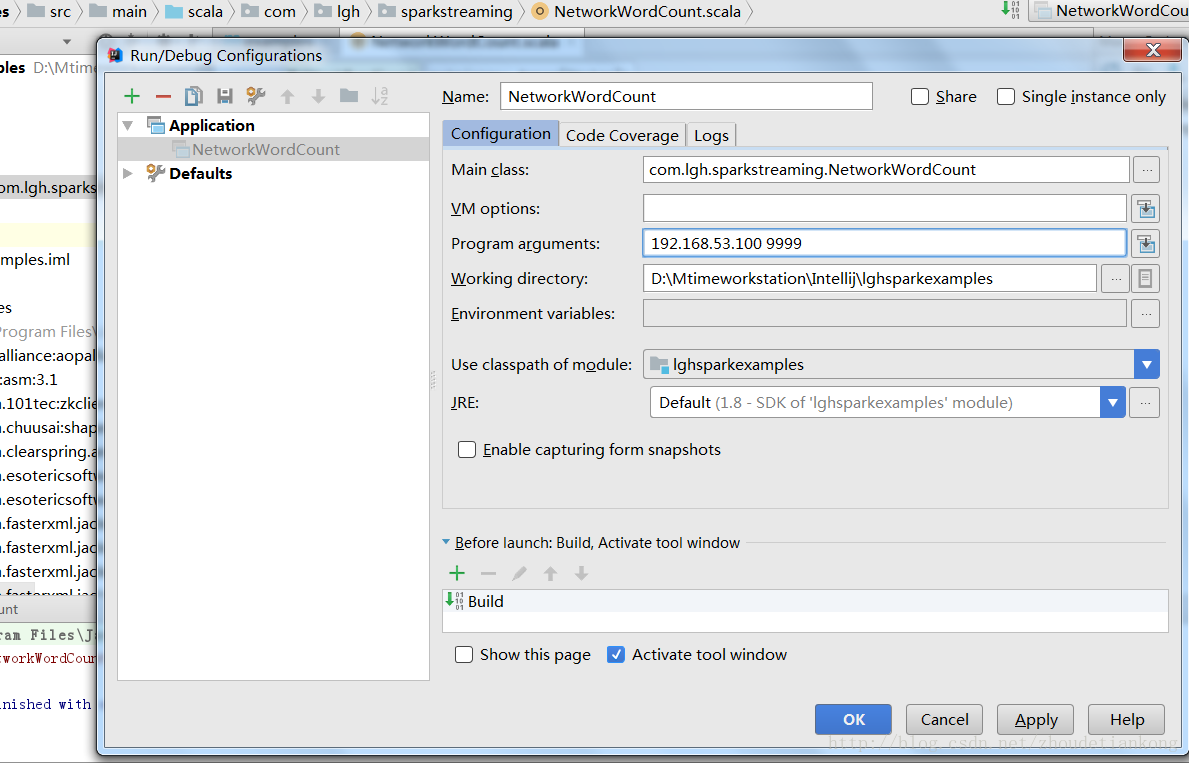
可以在idea的本机通过web界面查看程序运行。
http://localhost:4040
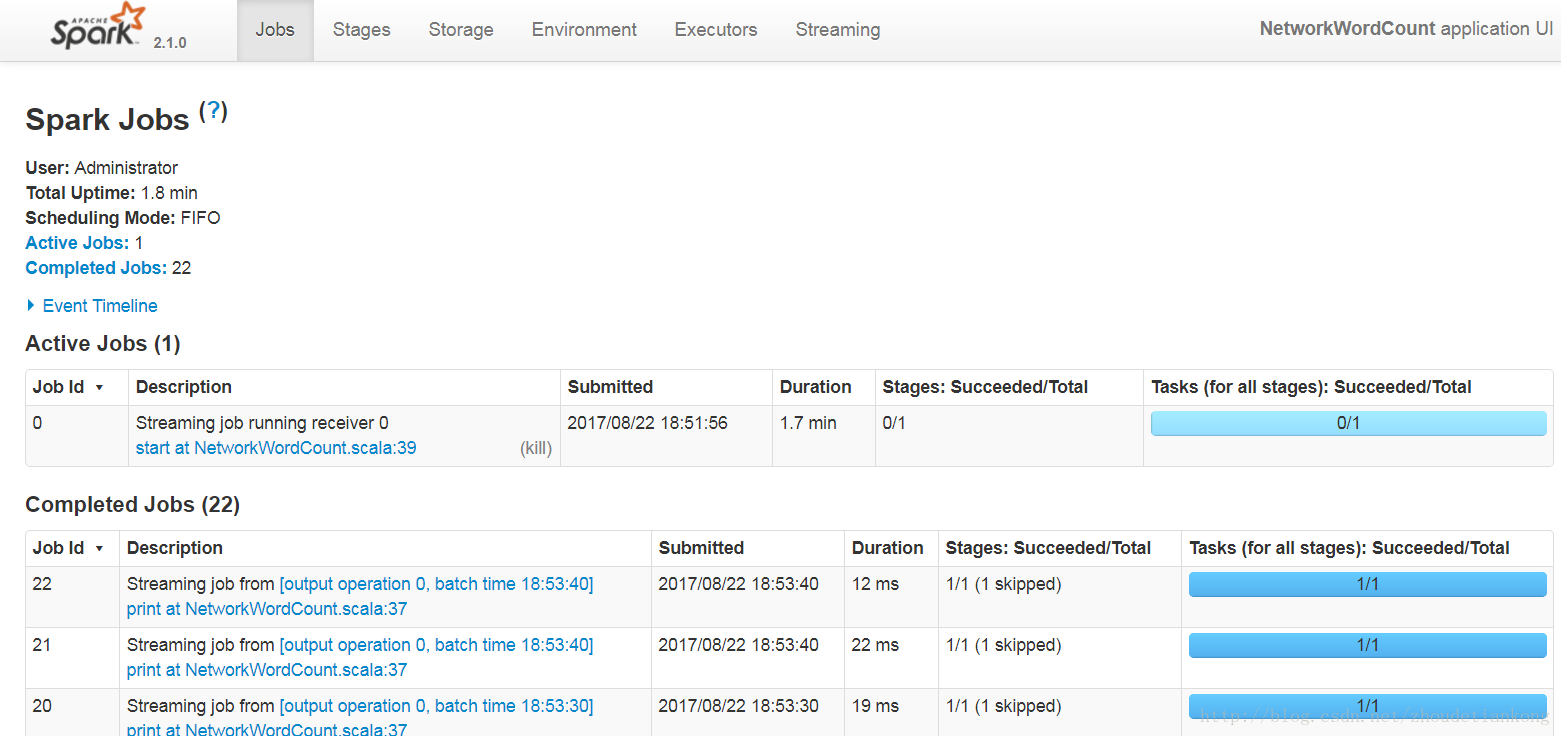
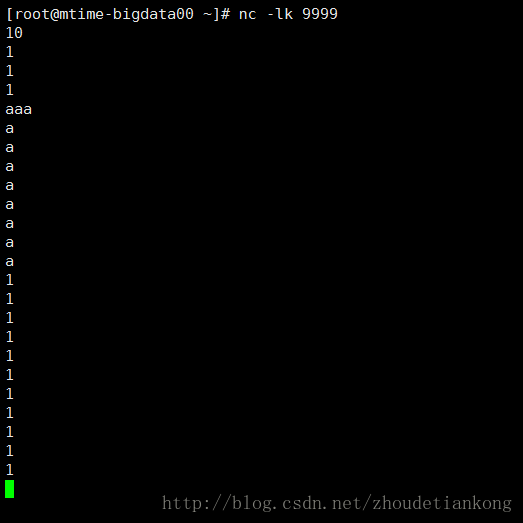

这个例子简单来说呢,就是统计每10s内的单词,然后计算这10s内的单词个数并输出。对于transformation以及output 的用法,可以自己查阅文档。















 2223
2223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









