









文章目录
1 版本说明
- Spark:3.0.0
- JDK:1.8
- Scala:2.12.11
2 IDEA 开发环境
2.1 创建 Maven 工程
创建 Maven 聚合工程,方便之后学习 Spark 时,分模块创建多个子工程,更清晰。
2.2 配置 Scala 环境
在项目结构中导入 Scala 开发包,可以在 IDEA 中在线下载。
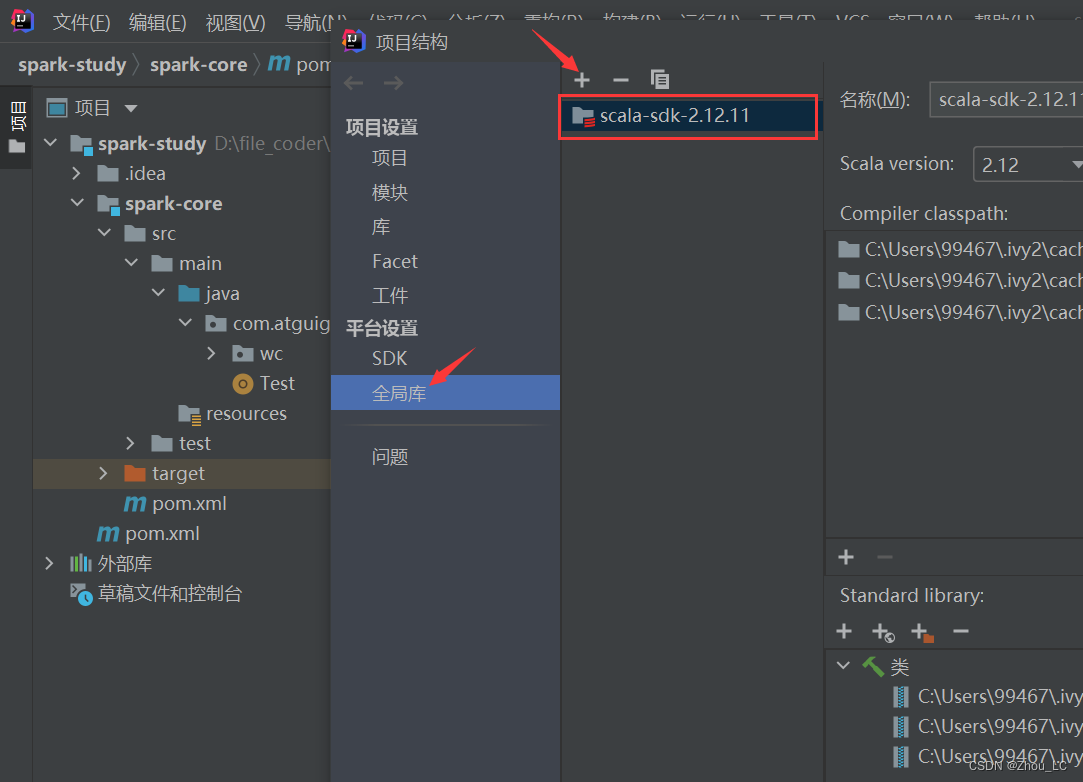
测试一下 Scala 环境是否已经配置进来,写一个 Object 静态类来测试一下,发现是可以正常输出的。

2.3 配置 Spark 环境
配置 pom.xml,引入依赖、插件:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将 Scala 代码编译成 class 文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<!-- 声明绑定到 maven 的 compile 阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3 Spark 实现 WordCount 单词统计
3.1 方式一
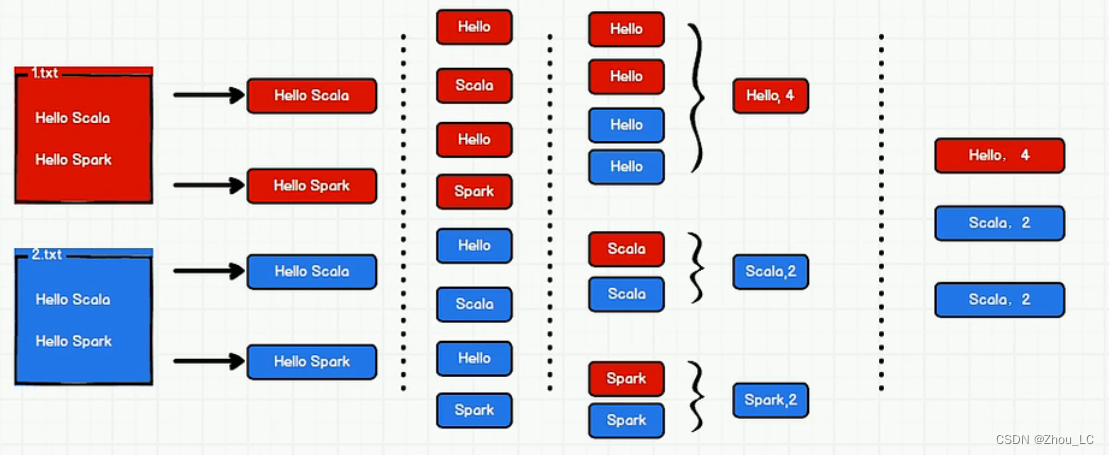
如下图所示,先拆分出一个个单词,再按类分组,再统计出每类中单词个数。
编写测试数据

Hello World
Hello World
Hello Spark
Hello Spark
代码部分:
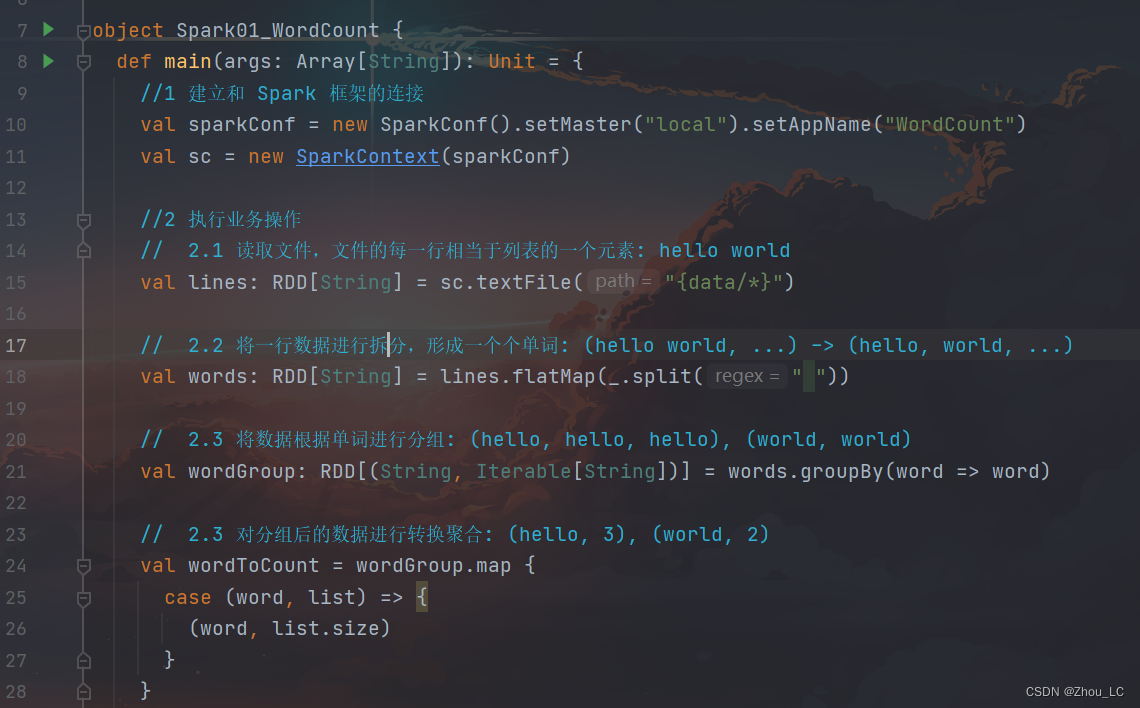
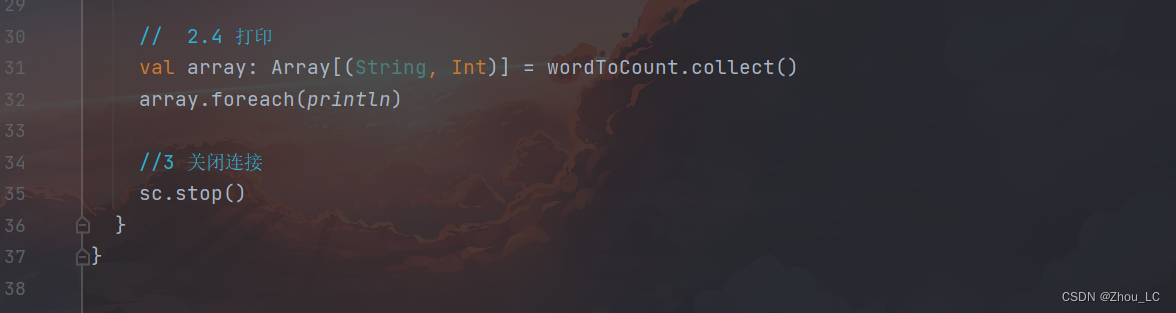
虽然当前这个程序运行没什么问题,但是一大堆爆红看着难受,这里可以自定义一下 log 日志配置

log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell,
the
# log level for this class is used to overwrite the root logger's log level, so
that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent
UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
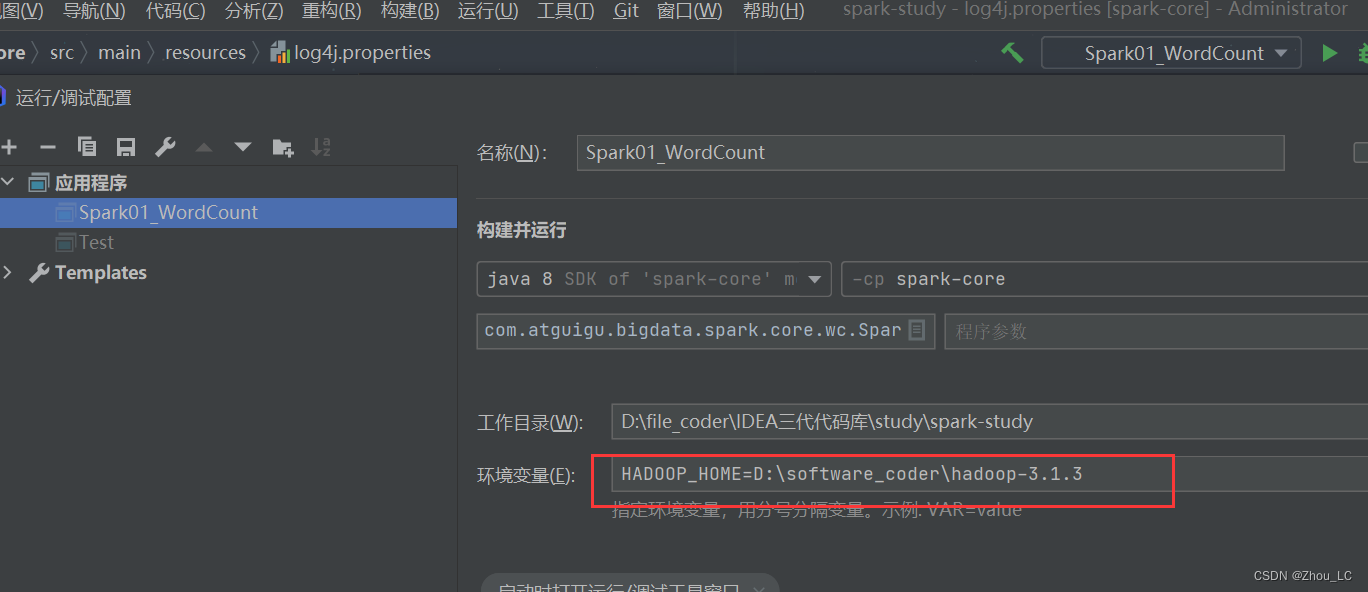
然后再配置一下 Hadoop 的环境变量就可以了
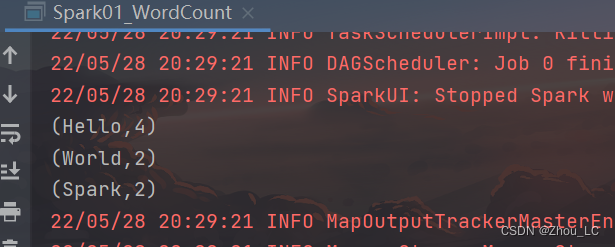
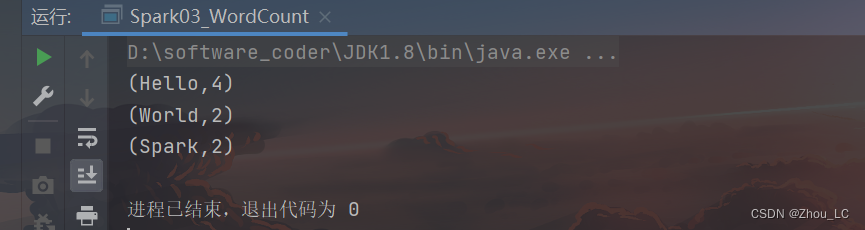
再次运行,结果就很清晰了

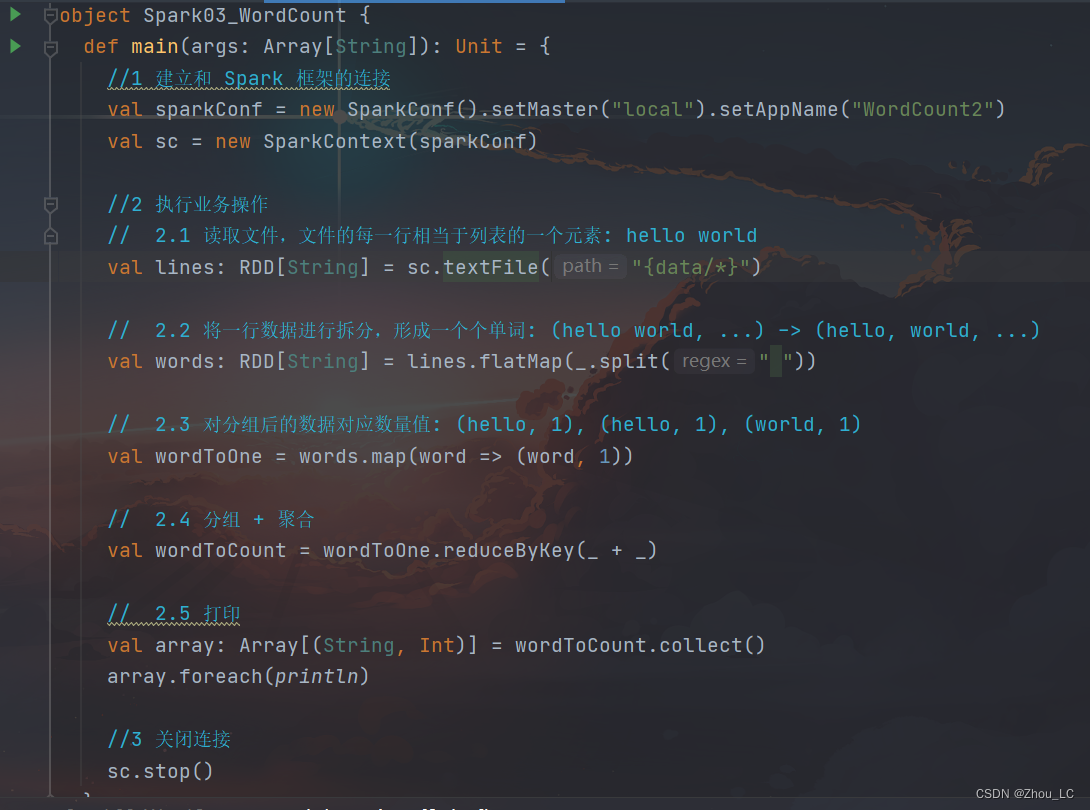
3.2 方式二
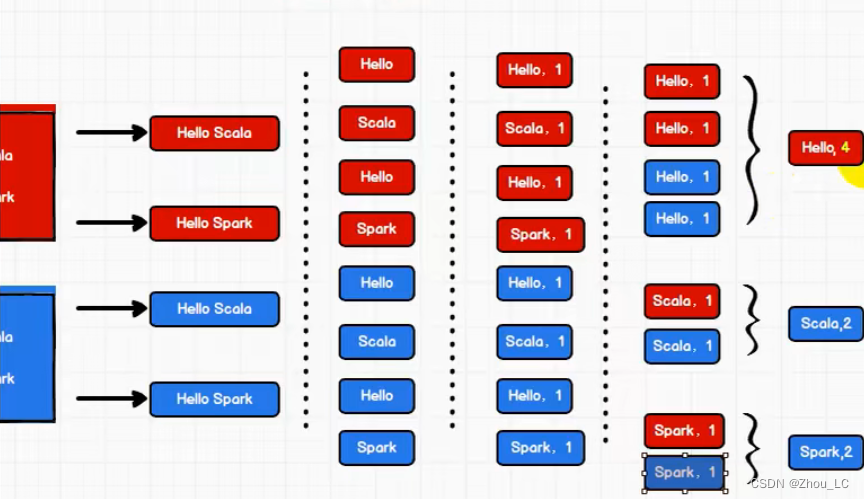
如下图所示,先拆分出一个个单词,并携带数量1,再按类聚合相加数量值
测试数据还是和上面一样
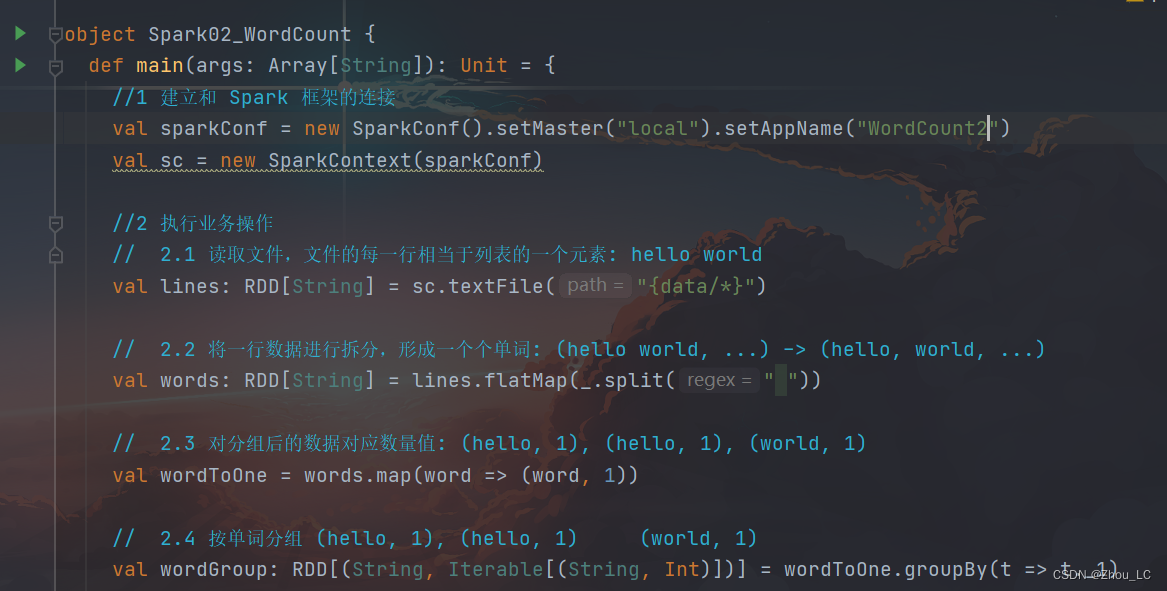
代码部分:
还需要再配一次当前应用程序的参数环境变量

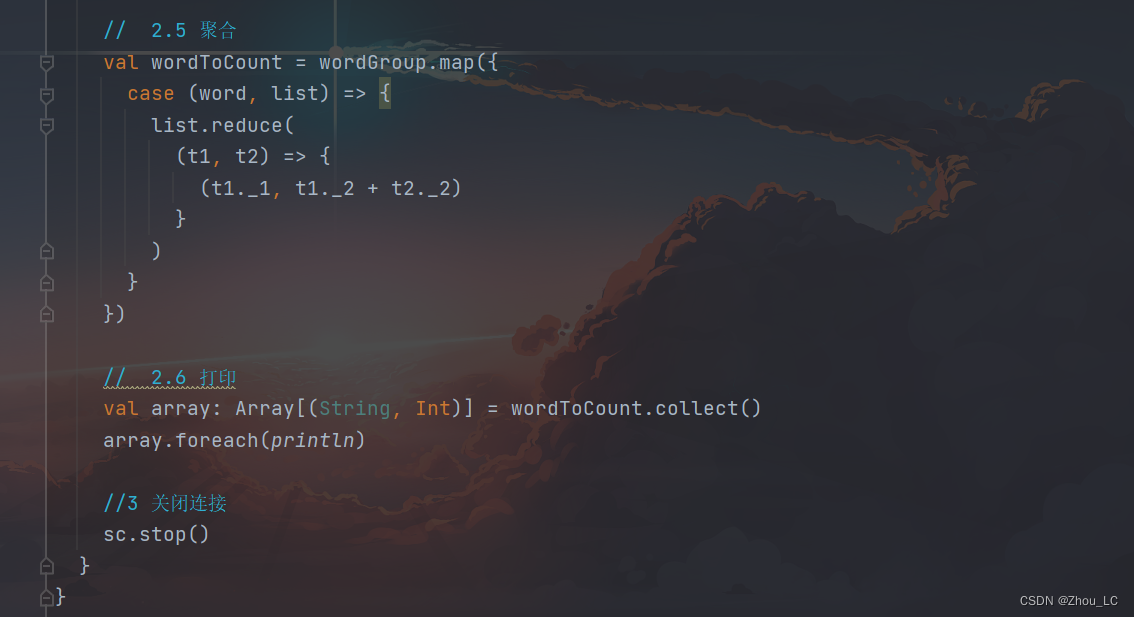
3.3 方式三

















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











