







一、概述
在实际的软件开发项目中,经常需要处理大量的文件。某些文件中包含了相当多的数据记录数,如作者本人参与过的项目中,一个文件中有好几十万条记录。如果一次性将多条记录读入,则会花费大量的处理时间,且占用大量的内存。
为此,要求对于包含大量数据记录的文件进行分批读取操作,即每一轮读取一定数目的数据记录,待将这些记录处理完成之后,再读取下一批数据。本文介绍分批读取文件中数据的程序流程,并给出了C程序实现。
二、总体程序流程
实现分批读取文件中数据的程序流程如图1所示。
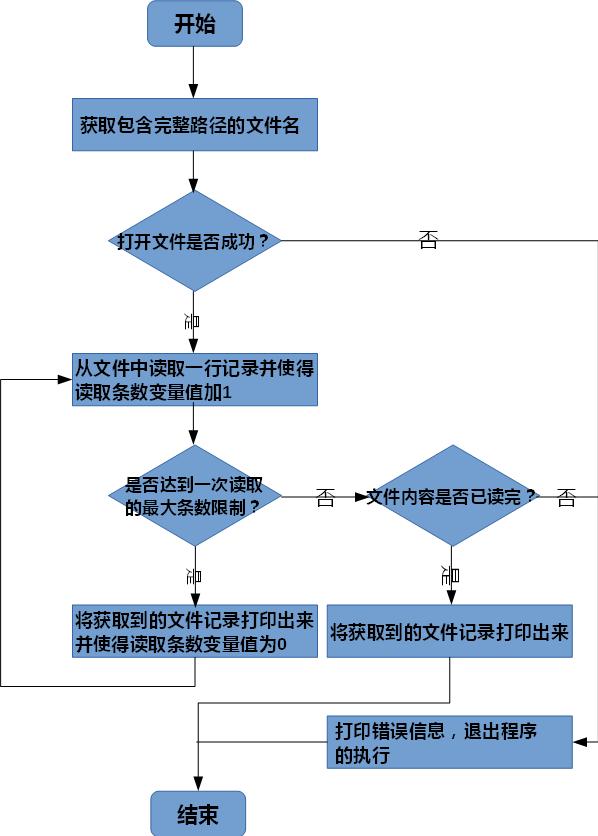
图1 实现分批读取文件中数据的程序流程
三、C程序实现
本程序命名为BatchReadFile.c,具体代码如下:
/**********************************************************************
* 版权所有 (C)2015, Zhou Zhaoxiong。
*
* 文件名称:BatchReadFile.c
* 文件标识:无
* 内容摘要:分批读取文件中的数据并打印出来
* 其它说明:无
* 当前版本:V1.0
* 作 者:Zhou Zhaoxiong
* 完成日期:20150528
*
**********************************************************************/
#include <stdio.h>
// 重定义数据类型
typedef signed int INT32;
typedef unsigned int UINT32;
typedef unsigned char UINT8;
// 宏定义
#define ONCE_READ_COUNT 5 // 一次读取的最大数据条数
#define MAX_RECORD_LEN 50 // 每条数据的最大长度
// 函数声明
INT32 ReadRecordFromFile(FILE *fp, UINT8 szRecordSet[][MAX_RECORD_LEN], UINT32 *piReadCnt);
INT32 main();
/**********************************************************************
* 功能描述:主函数
* 输入参数:无
* 输出参数:无
* 返 回 值:无
* 其它说明:无
* 修改日期 版本号 修改人 修改内容
* -------------------------------------------------------------------
* 20150528 V1.0 Zhou Zhaoxiong 创建
***********************************************************************/
INT32 main()
{
UINT8 szFileName[256] = {0}; // 包含完整路径的文件名
FILE *fp = NULL; // 文件句柄
UINT32 iReadCnt = 0; // 一次读取到的记录数
UINT32 iRecCnt = 0; // 记录数, 循环变量
UINT32 iReadTimes = 0; // 读取文件次数
INT32 iRetVal = 0; // 读取文件函数的返回值
UINT8 szRecordSet[ONCE_READ_COUNT][MAX_RECORD_LEN] = {0}; // 存放从文件中读取到的记录内容集
UINT8 szRecordInfo[MAX_RECORD_LEN] = {0}; // 存放从文件中读取到的每条记录内容
// 获取包含完整路径的文件名
strcpy(szFileName, "/home/zxin10/zhouzx/test/file/TestFile.txt");
// 打开文件
fp = fopen(szFileName, "r");
if (NULL == fp) // 打开失败
{
printf("Open file %s failed!\n", szFileName);
return -1;
}
// 读取文件内容并打印出来
while (1)
{
iReadCnt = 0;
memset(szRecordSet, 0x00, sizeof(szRecordSet));
iRetVal = ReadRecordFromFile(fp, szRecordSet, &iReadCnt);
if (iRetVal == -1) // 表示函数执行失败, 直接退出
{
printf("Exec ReadRecordFromFile failed, please check!\n");
break;
}
if (iReadCnt > 0)
{
iReadTimes ++; // 读取次数加1
printf("ReadTimes is: %d, the RecordInfo is:\n", iReadTimes);
}
for (iRecCnt = 0; iRecCnt < iReadCnt; iRecCnt ++) // 打印读取到的记录值
{
memset(szRecordInfo, 0x00, sizeof(szRecordInfo));
strncpy(szRecordInfo, szRecordSet[iRecCnt], sizeof(szRecordInfo)-1);
printf("%s\n", szRecordInfo);
}
if (iRetVal == 0) // 表示文件记录已扫描完, 直接退出
{
break;
}
}
return 0;
}
/**********************************************************************
* 功能描述:从文件中读取记录内容
* 输入参数:fp-文件指针
* 输出参数:szRecordSet-记录内容信息集
piReadCnt-读取到的条数
* 返 回 值:1-下一轮继续读取 0-本轮已读取完毕 -1-读取失败
* 其它说明:无
* 修改日期 版本号 修改人 修改内容
* -------------------------------------------------------------------
* 20150528 V1.0 Zhou Zhaoxiong 创建
***********************************************************************/
INT32 ReadRecordFromFile(FILE *fp, UINT8 szRecordSet[][MAX_RECORD_LEN], UINT32 *piReadCnt)
{
UINT8 szRecordInfo[MAX_RECORD_LEN] = {0}; // 存储读取到的每条记录信息
UINT32 iRecordLen = 0; // 存储读取到的每条记录信息的长度
if (fp == NULL || piReadCnt == NULL)
{
printf("ReadRecordFromFile: input paramter(s) is NULL!\n");
return -1;
}
// 读取文件记录
while ((!feof(fp)) && (!ferror(fp))) // 遇到文件结尾或读取错误则退出
{
// 读取一条记录
memset(szRecordInfo, 0x00, sizeof(szRecordInfo));
fgets(szRecordInfo, sizeof(szRecordInfo)-1, fp);
// 去掉记录后面的回车换行符
iRecordLen = strlen(szRecordInfo);
while (iRecordLen > 0)
{
if (szRecordInfo[iRecordLen-1] == '\n' || szRecordInfo[iRecordLen-1] == '\r')
{
szRecordInfo[iRecordLen-1] = '\0';
}
else
{
break;
}
iRecordLen --;
}
// 判断是否为空行, 是则继续读取
if (strlen(szRecordInfo) == 0)
{
continue;
}
// 将记录信息拷贝到输出缓存中
strncpy(szRecordSet[(*piReadCnt)++], szRecordInfo, MAX_RECORD_LEN-1);
// 如果超出最大条数限制, 则直接返回
if ((*piReadCnt) >= ONCE_READ_COUNT)
{
return 1;
}
}
return 0;
}
四、程序说明
1.被读取的文件命名为“TestFile.txt”,存放在“/home/zhou/zhouzx/test/file/”目录下。
2.为了方便看到效果,程序中设定每一次最大读取条数为5,每条记录的最大长度为50(最大长度值的设定的依据是读取的文件记录的长度)。将读取到的记录存放到一个二维数组变量中,其中第一维是每次读取到的记录条数,第二维是每条记录的长度。
3.如果一轮未读完数据,则文件指针会自动跳到下一次读取的记录的开头。结束一轮读取的条件有三个:已达读取上限、记录已全部读完、读取错误。
4.如果文件中出现了空行,那么程序并不会将之作为有效行而使得读取条数增加,而是从下一个非空行开始继续计数。
5.程序会打印出读取的次数及每次读取到的具体记录信息,方便查看程序分批处理的执行情况。
五、程序编译及运行结果
在Linux下,使用“gcc -g -o BatchReadFile BatchReadFile.c”命令对程序进行编译,生成“BatchReadFile”。下面执行“BatchReadFile”命令来对程序进行测试。
1.“TestFile.txt”文件中的内容如下:
100001
100002
100003
100004则程序运行结果为:
ReadTimes is: 1, the RecordInfo is:
100001
100002
100003
1000042.“TestFile.txt”文件中的内容如下:
100001
100002
100003
100004
100005则程序运行结果为:
ReadTimes is: 1, the RecordInfo is:
100001
100002
100003
100004
1000053.“TestFile.txt”文件中的内容如下:
100001
100002
100003
100004
100005
100006则程序运行结果为:
ReadTimes is: 1, the RecordInfo is:
100001
100002
100003
100004
100005
ReadTimes is: 2, the RecordInfo is:
1000064.“TestFile.txt”文件中的内容如下:
100001
100002
100003
100004
100005
100006
100007
100008
100009
100010
100011则程序运行结果为:
ReadTimes is: 1, the RecordInfo is:
100001
100002
100003
100004
100005
ReadTimes is: 2, the RecordInfo is:
100006
100007
100008
100009
100010
ReadTimes is: 3, the RecordInfo is:
100011可见,即使文件中存在空行,程序也能够正常处理。
六、总结
本文对分批读取文件中数据的程序流程进行了介绍,并给出了C程序实现。在实际的软件开发项目中,每个文件包含的记录条数要多很多,但基本的程序编写流程是一样的。大家可以根据实际需要对本文中的程序进行修改来满足具体的要求。
本人微信公众号:zhouzxi,请扫描以下二维码:
















 2089
2089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











