







 本文详细介绍了Spark运行架构,重点解析了DAGScheduler如何根据RDD之间的依赖关系形成DAG,并进行Stage划分。在Action触发后,DAGScheduler提交TaskSet给TaskScheduler。接着,深入探讨了DAGSchedulerEventProcessLoop的角色,以及DAGScheduler在handleJobSubmitted方法中创建ResultStage和提交Stage的过程。最后,简述了Stage提交的逻辑,为后续TaskSet的提交和TaskScheduler的调度打下基础。
本文详细介绍了Spark运行架构,重点解析了DAGScheduler如何根据RDD之间的依赖关系形成DAG,并进行Stage划分。在Action触发后,DAGScheduler提交TaskSet给TaskScheduler。接着,深入探讨了DAGSchedulerEventProcessLoop的角色,以及DAGScheduler在handleJobSubmitted方法中创建ResultStage和提交Stage的过程。最后,简述了Stage提交的逻辑,为后续TaskSet的提交和TaskScheduler的调度打下基础。
一、Spark 运行架构
![]()
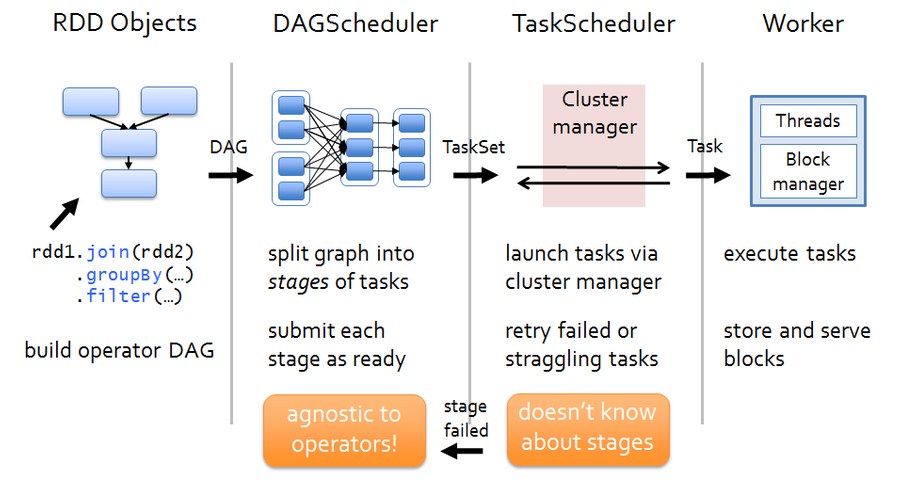
Spark 运行架构如下图:
各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分,DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,在Worker节点上启动task。
二、源码解析:DAGScheduler中的DAG划分
当RDD触发一个Action操作(如:colllect)后,导致SparkContext.runJob的执行。而在SparkContext的run方法中会调用DAGScheduler的run方法最终调用了DAGScheduler的submit方法:
def submitJob[T, U](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],callSite: CallSite,resultHandler: (Int, U) => Unit,properties: Properties): JobWaiter[U] = {// Check to make sure we are not launching a task on a partition that does not exist.val maxPartitions = rdd.partitions.lengthpartitions.find(p => p >= maxPartitions || p < 0).foreach { p =>throw new IllegalArgumentException("Attempting to access a non-existent partition: " + p + ". " +"Total number of partitions: " + maxPartitions)}val jobId = nextJobId.getAndIncrement()if (partitions.size == 0) {// Return immediately if the job is running 0 tasksreturn new JobWaiter[U](this, jobId, 0, resultHandler)}assert(partitions.size > 0)val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)//给eventProcessLoop发送JobSubmitted消息eventProcessLoop.post(JobSubmitted(jobId, rdd, func2, partitions.toArray, callSite, waiter,SerializationUtils.clone(properties)))waiter
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









