







 本文深入探讨Spark的DAGScheduler如何进行stage划分,从行动操作出发,根据窄依赖和宽依赖原则倒推创建stage。同时,解析DAGScheduler的源码,重点关注onReceive方法。此外,文章还分析了Task的最佳位置计算算法。
本文深入探讨Spark的DAGScheduler如何进行stage划分,从行动操作出发,根据窄依赖和宽依赖原则倒推创建stage。同时,解析DAGScheduler的源码,重点关注onReceive方法。此外,文章还分析了Task的最佳位置计算算法。
①stage划分的算法的原理
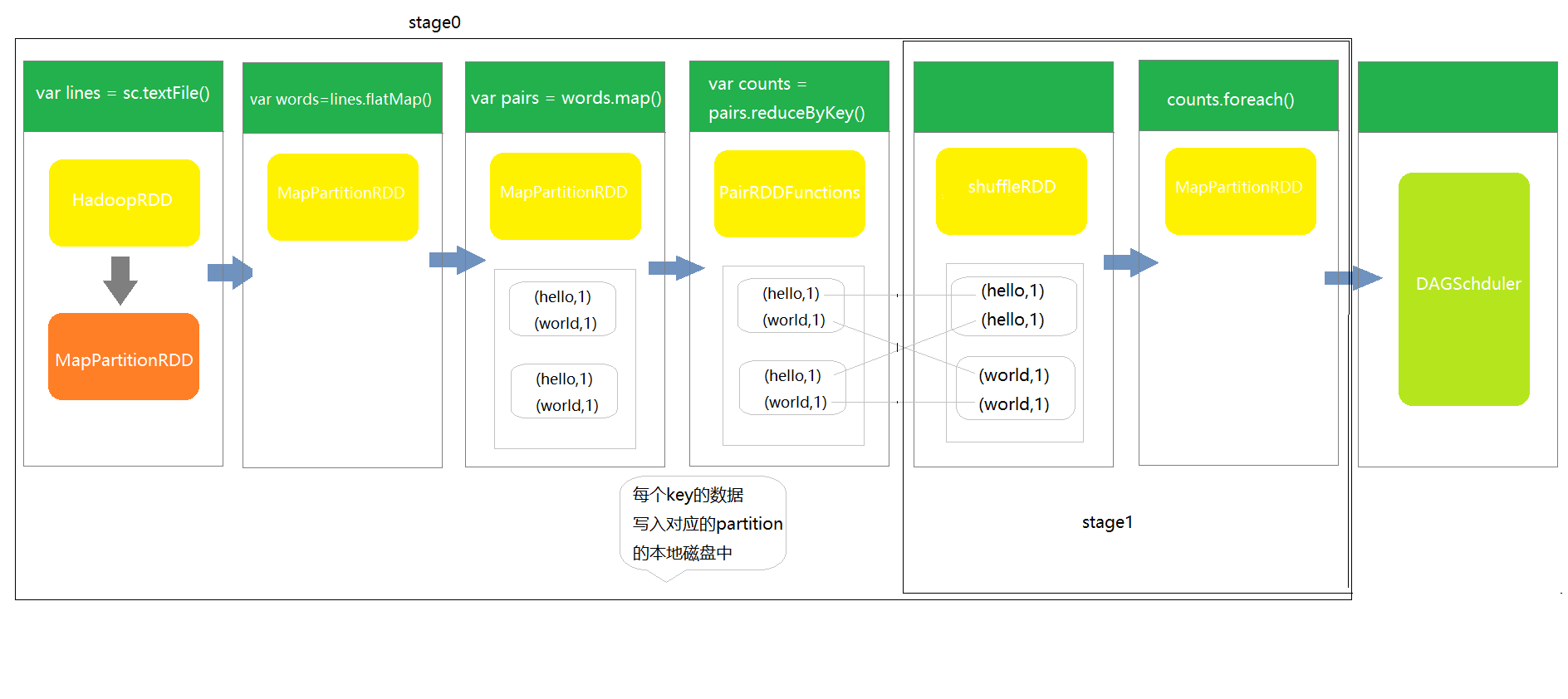
DAGSchduler对stage的划分,从出发action操作开始,往前倒推。首先会为最后一个rdd创建一个stage,往前倒推的过程中如果rdd之间存在宽依赖又创建一个新的stage,之前的最后一个rdd就是最新的stage的最后一个rdd ,以此类推,根据窄依赖和宽依赖判断,直到所有rdd遍历完成为止。
②stage划分源码解析
DAGSchduler.scala
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
...
}最终会掉到方法onReceive上
/**
* The main event loop of the DAG scheduler.
*/
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
...
}/**
* DAGSchduler的job调度核心入口
*/
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
// 使用触发job的最后一个rdd,创建stage
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
//第一步 创建一个结果输出stage,并加入DAGSchduler内部的内存缓存中
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// 第二步 用finalStage创建一个job,即这个job的最后一个stage
val job = new ActiveJob(jobId, finalStage, callSite, listener,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









