







前言:
对于大数据计算框架而言,Shuffle阶段的设计优劣是决定性能好坏的关键因素之一。
shuffle的优化是一个不断发展的过程。
shuffle基本概念
shuffle是一个算子,表达的是多对多的依赖关系,在MapReduce计算框架中,是连接Map阶段和Reduce阶段的纽带,即每个Reduce Task从每个Map Task产生数的据中读取一片数据。
通常shuffle分为两部分:Map阶段的数据准备和Reduce阶段的数据拷贝。
Map阶段的数据准备
Map阶段需根据Reduce阶段的Task数量决定每个Map Task输出的数据分片数目,有多种方式存放这些数据分片,不同的数据存放方式各有优缺点和适用场景。
一般而言,shuffle在Map端的数据要存储到磁盘上,以防止容错触发重算带来的庞大开销(如果保存到Reduce端内存中,一旦Reduce Task挂掉了,所有Map Task需要重算)。
数据在磁盘上存放方式有多种可选方案,在MapReduce前期设计中,每个Map Task为每个Reduce Task产生一个文件,该文件只保存特定Reduce Task需处理的数据,这样会产生M*R个文件,如果M和R非常庞大,比如均为1000,则会产生100w个文件,产生和读取这些文件会产生大量的随机IO,效率非常低下。解决这个问题的一种直观方法是减少文件数目,常用的方法有:
1) 将一个节点上所有Map产生的文件合并成一个大文件(MapReduce现在采用的方案),
2) 每个节点产生{(slot数目)*R}个文件(Spark优化后的方案)。
不管是MapReduce 1.0还是Spark,每个节点的资源会被抽象成若干个slot,由于一个Task占用一个slot,因此slot数目可看成是最多同时运行的Task数目。如果一个Job的Task数目非常多,限于slot数目有限,可能需要运行若干轮。这样,只需要由第一轮产生{(slot数目)*R}个文件,后续几轮产生的数据追加到这些文件末尾即可。因此,后一种方案可减少大作业产生的文件数目。
Reduce阶段的数据拷贝
在Reduce端,各个Task会并发启动多个线程同时从多个Map Task端拉取数据。
在Reduce阶段的主要任务是对数据进行按组规约。也就是说,需要将数据分成若干组,以便以组为单位进行处理。大家知道,分组的方式非常多,常见的有:
1)Map/HashTable(key相同的,放到同一个value list中);
2)Sort(按key进行排序,key相同的一组,经排序后会挨在一起)。
这两种方式各有优缺点:
第一种复杂度低,效率高,但是需要将数据全部放到内存中;
第二种方案复杂度高,但能够借助磁盘(外部排序)处理庞大的数据集。
Spark前期采用了第一种方案,而在最新的版本中加入了第二种方案,Hadoop MapReduce则从一开始就选用了基于sort的方案。下面将对其进行详细分析。
1、什么是Spark的Shuffle
图1
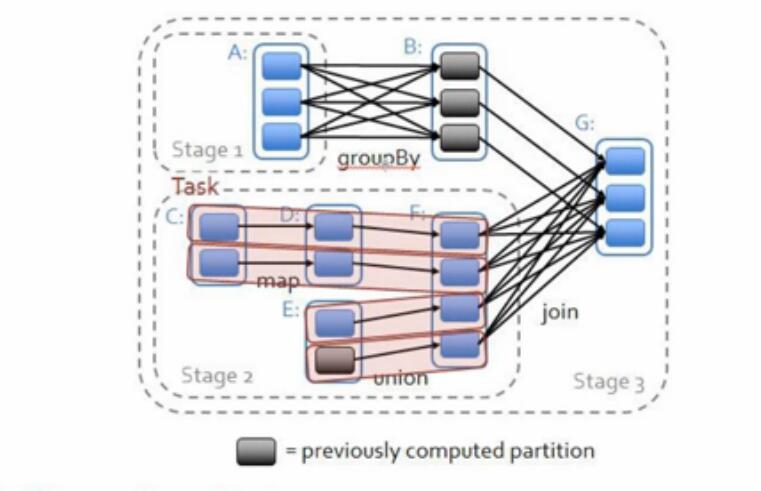
Spark有很多算子,比如:groupByKey、join等等都会产生shuffle。
产生shuffle的时候,首先会产生Stage划分。
上一个Stage会把
计算结果放在LocalSystemFile中,并汇报给Driver;
下一个Stage的运行由Driver触发,Executor向Driver请求,把上一个Stage的计算结果抓取过来。
2、Hadoop MapReduce Shuffle发展史
图2
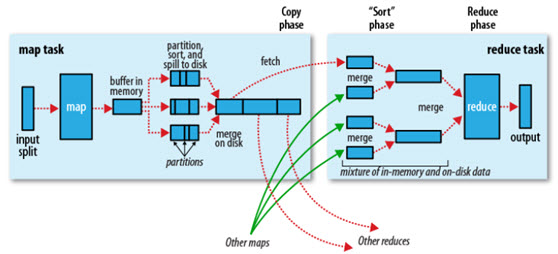
该图表达了Hadoop的map和reduce两个阶段,通过Shuffle怎样把map task的输出结果有效地传送到reduce端,描述着数据从map task输出到reduce task输入的这段过程。
map的计算为reduce产生不同的文件,在Hadoop集群环境中,大部分map task与reduce task的执行是在不同的节点上,reduce执行时需要跨节点去拉取其它节点上的map task结果,那么对集群内部的网络资源消耗会很严重。我们希望最大化地减少不必要的消耗, 于是对Shuffle过程的期望有:
- 完整地从map task端拉取数据到reduce 端。
- 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
可优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。
map端的Shuffle细节:
整个map流程,简单些可以这样说:
1)input, 根据split输入数据,运行map任务;
2)patition, 每个map task都有一个内存缓冲区,存储着map的输出结果;
3)spill, 当缓冲区快满的时候需要将缓冲区的数据以临时文件的方式存放到磁盘;
4)merge, 当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
下面对map流程的细节进行说明:
1)输入数据:在Map Reduce中,map task只读取split,Split与block的对应关系可能是多对一,默认是一对一;
2)mapper运行后,通过Partitioner接口,根据key或value及reduce的数量来决定当前map的输出数据最终应该交由哪个reduce task处理。然后将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组;
3)内存缓冲区有大小限制,默认是100MB。需要在一定条件下将缓冲区中的数据临时写入磁盘,从内存往磁盘写数据的过程被称为Spill(溢写);
splill是由单独线程来完成,不影响往缓冲区写map结果的线程,splill的过程会涉及到Sort和Combiner,当splill线程启动后,需要对锁定内存块空间内的key做排序,是对序列化的字节做排序。 如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录,非正式地合并数据叫做combine了, Combiner会优化MapReduce的中间结果。
4)每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果很大,就会有多个溢写文件存在。当map task完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。
Merge是怎样的?比如WordCount示例中,某个单词“aaa”从某个map task读取过来时值是5,从另外一个map task 读取时值是8,因为它们有相同的key,所以就是像这样:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。
因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
至此,map端的所有工作都已结束,最终生成的这个文件也存放在TaskTracker够得着的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,如果获知TaskTracker上的map task执行完成,Shuffle的后半段过程开始启动。
下面讲解reduce 端的Shuffle细节:
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
1) Copy过程,简单地拉取数据。
Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2)Merge阶段。
这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达阈值,就启动内存到磁盘的merge。
与map 端类似,这也是溢写的过程,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3)Reducer的输入文件。
不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,hadoop是把这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
3、Hadoop的MapReduce Shuffle数据流动过程
图3
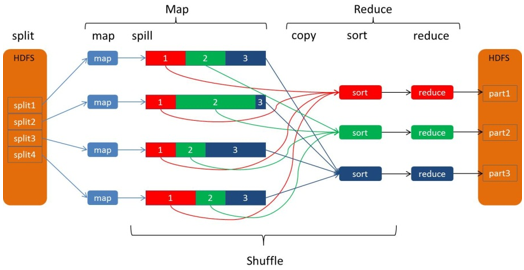
这张图非常有意思,形象地描述了整个数据流动的过程。
图上map阶段,有4个map;Reduce端,有3个reduce。
4个map 也就是4个JVM,每个JVM处理一个数据分片(split1~split4),每个map产生一个map输出文件,但是每个map都为后面的reduce产生了3部分数据(分别用红1、绿2、蓝3标识),也就是说每个输出的map文件都包含了3部分数据。正如前面第二节所述:
mapper运行后,通过Partitioner接口,根据key或value及reduce的数量来决定当前map的输出数据最终应该交由哪个reduce task处理
Reduce端一共有3个reduce,去前面的4个map的输出结果中抓取属于自己的数据。
在构建算法时,Shuffle是最重要的思考点。
4、Spark Shuffle
图4
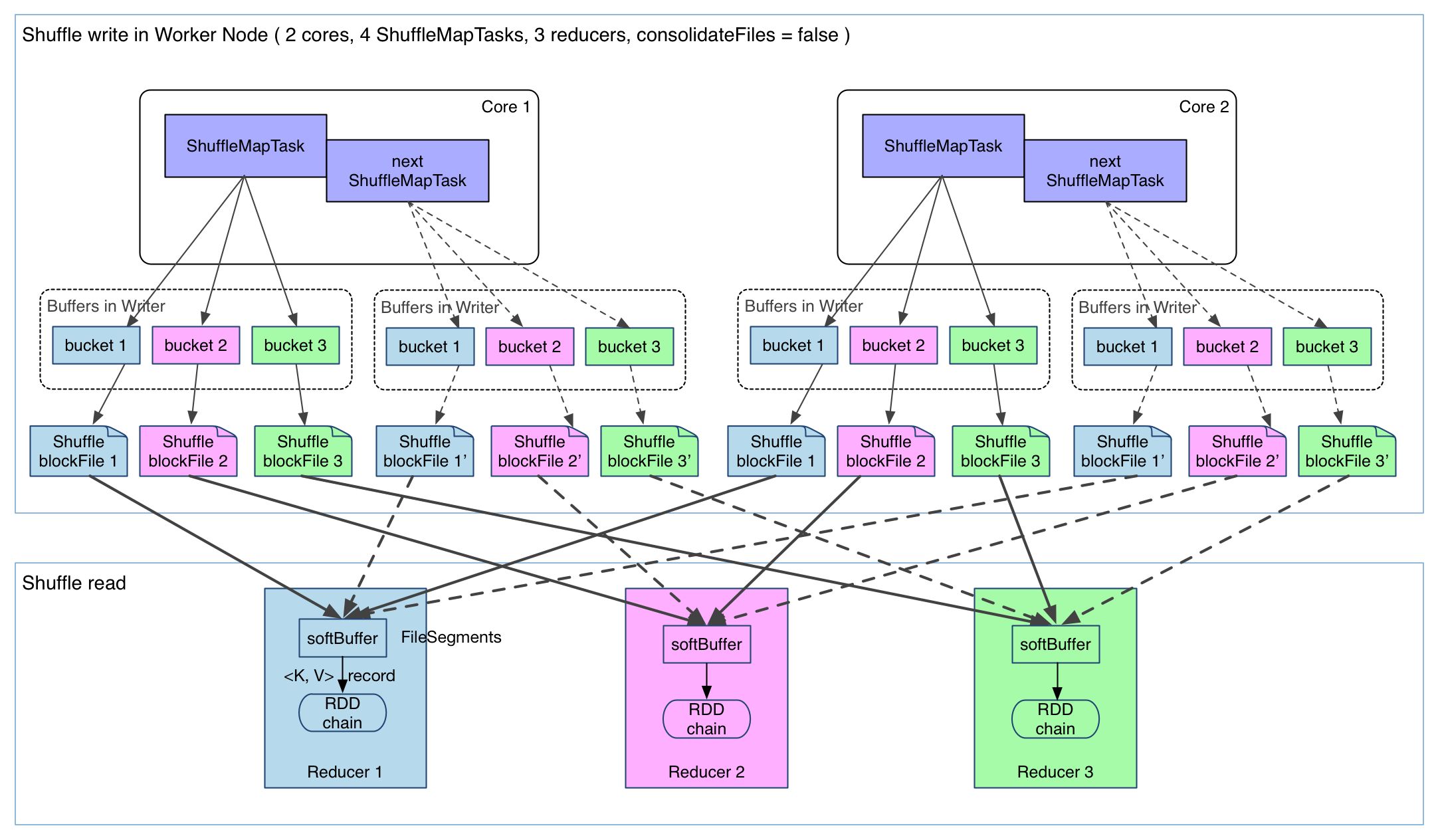
该图描述了最简单的Spark 0.X版本的Spark Shuffle过程。
与Hadoop Map Reduce的区别在于输出文件个数的变化。
每个ShuffleMapTask产生与Ruducer个数相同的Shuffle blockFile文件,图中有3个reducer,那么每个ShuffleMapTask就产生3个Shuffle blockFile文件,4个ShuffleMapTask,那么一共产生12个Shuffle blockFile文件。
在内存中每个Shuffle blockFile文件都会存在一个句柄从而消耗一定内存,又因为物理内存的限制,就不能有很多并发,这样就限制了Spark集群的规模。
该图描绘的只是Spark 0.X版本而已,让人误以为Spark不支持大规模的集群计算,当时这只是Hash Based Shuffle。Spark后来做了改进,引入了Sort Based Shuffle之后,就再也没有人说Spark只支持小规模的集群运算了。
4.1 Hash based shuffle
Hash based shuffle的每个mapper都需要为每个reducer写一个文件,供reducer读取,即需要产生M*R个数量的文件,如果mapper和reducer的数量比较大,产生的文件数会非常多。
Hadoop Map Reduce被人诟病的地方,很多不需要sort的地方的sort导致了不必要的开销,于是Spark的Hash based shuffle设计的目标之一就是避免不需要的排序,
但是它在处理超大规模数据集的时候,产生了大量的磁盘IO和内存的消耗,很影响性能。
Hash based shuffle不断优化,Spark 0.8.1引入的file consolidation在一定程度上解决了这个问题。
4.2 Sort based shuffle
为了解决hash based shuffle性能差的问题,Spark 1.1 引入了Sort based shuffle,完全借鉴map reduce实现,每个Shuffle Map Task只产生一个文件,不再为每个Reducer生成一个单独的文件,将所有的结果只写到一个Data文件里,同时生成一个index文件,index文件存储了Data中的数据是如何进行分类的。Reducer可以通过这个index文件取得它需要处理的数据。 下一个Stage中的Task就是根据这个Index文件来获取自己所要抓取的上一个Stage中的Shuffle Map Task的输出数据。
Shuffle Map Task产生的结果只写到一个Data文件里, 避免产生大量的文件,从而节省了内存的使用和顺序Disk IO带来的低延时。节省内存的使用可以减少GC的风险和频率。
而减少文件的数量可以避免同时写多个文件对系统带来的压力。
Sort based shuffle在速度和内存使用方面也优于Hash based shuffle。
以上逻辑可以使用下图来描述:
图5
Sort based Shuffle包含两阶段的任务:
1)产生Shuffle数据的阶段(Map阶段)
需要实现ShuffleManager中的getWriter来写数据,数据可以通过BlockManager写在内存、磁盘以及Tachyon等,例如想非常快的Shuffle,此时考虑可以把数据写在内存中,但是内存不稳定,建议采用内存+磁盘。
2)使用Shuffle数据的阶段(Reduce阶段)
需要实现ShuffleManager的getReader,Reader会向Driver去获取上一个Stage产生的Shuffle数据)
Sort based shuffle 源码分析
ShuffleMapTask的runTask方法
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}manager.getWriter 默认是返回是SortShuffleWriter
SortShuffleWriter的write方法
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
/*
* 根据ShuffledRDD的ShuffleHandler对paritition的数据进行处理
* 1. 将partition的数据存放到ExternalSorter.map中,ExternalSorter.map是一个PartitionedAppendOnlyMap对象
* 2. 如果partition的数据量太大,超过了允许的最大内存,则将ExternalSorter.map中的数据进行排序,然后将这些数据spill到磁盘文件
* */
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
/**
* Write all the data added into this ExternalSorter into a file in the disk store.
* This is called by the SortShuffleWriter.
*
* @param blockId block ID to write to.
* The index file will be blockId.name + ".index".
* @return array of lengths, in bytes, of each partition of the file
* (used by map output tracker)
*/
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
/**
* Write an index file with the offsets of each block, plus a final offset at the end for the
* end of the output file. This will be used by getBlockData to figure out where each block
* begins and ends.
*
* It will commit the data and index file as an atomic operation, use the existing ones, or
* replace them with new ones.
*
* Note: the `lengths` will be updated to match the existing index file if use the existing ones.
* */
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
}BlockStoreShuffleReader的read方法
Fetches and reads the partitions in range [startPartition, endPartition) from a shuffle by
requesting them from other nodes’ block stores.
/** Read the combined key-values for this reduce task */
override def read(): Iterator[Product2[K, C]] = {
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
// Wrap the streams for compression based on configuration
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
serializerManager.wrapForCompression(blockId, inputStream)
}
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// Create an ExternalSorter to sort the data. Note that if spark.shuffle.spill is disabled,
// the ExternalSorter won't spill to disk.
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
}4.3 Tungsten-sort Based Shuffle
Tungsten-sort 在特定场景下基于现有的Sort Based Shuffle处理流程,对内存/CPU/Cache使用做了非常大的优化。带来高效的同时,也就限定了自己的使用场景,所以Spark 默认开启的还是Sort Based Shuffle。
Tungsten 是钨丝的意思。 Tungsten Project 是 Databricks 公司提出的对Spark优化内存和CPU使用的计划,该计划初期对Spark SQL优化的最多,不过部分RDD API 还有Shuffle也因此受益。
Tungsten-sort是对普通sort的一种优化,排序的不是内容本身,而是内容序列化后字节数组的指针(元数据),把数据的排序转变为了指针数组的排序,实现了直接对序列化后的二进制数据进行排序。由于直接基于二进制数据进行操作,所以在这里面没有序列化和反序列化的过程。内存的消耗降低,相应的也会减少gc的开销。
Tungsten-sort优化点主要在三个方面:
1)直接在serialized binary data上进行sort而不是java objects,减少了memory的开销和GC的overhead。
2)提供cache-efficient sorter,使用一个8 bytes的指针,把排序转化成了一个指针数组的排序。
3)spill的merge过程也无需反序列化即可完成。
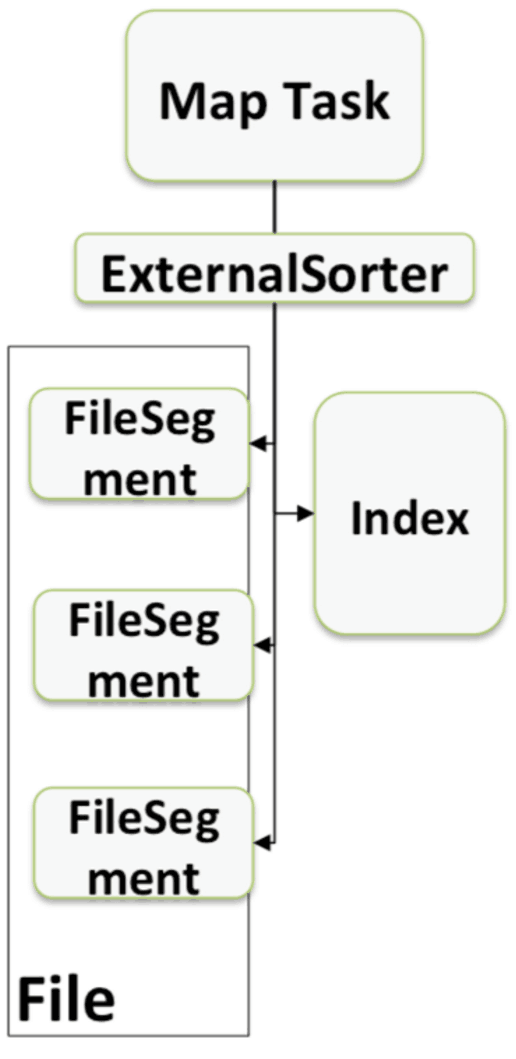
这些优化的实现导致引入了一个新的内存管理模型,类似OS的Page,Page是由MemoryBlock组成的, 支持off-heap(用NIO或者Tachyon管理) 以及 on-heap 两种模式。为了能够对Record 在这些MemoryBlock进行定位,又引入了Pointer的概念。
下面是内存管理类的实现代码:
图6. MemoryBlock
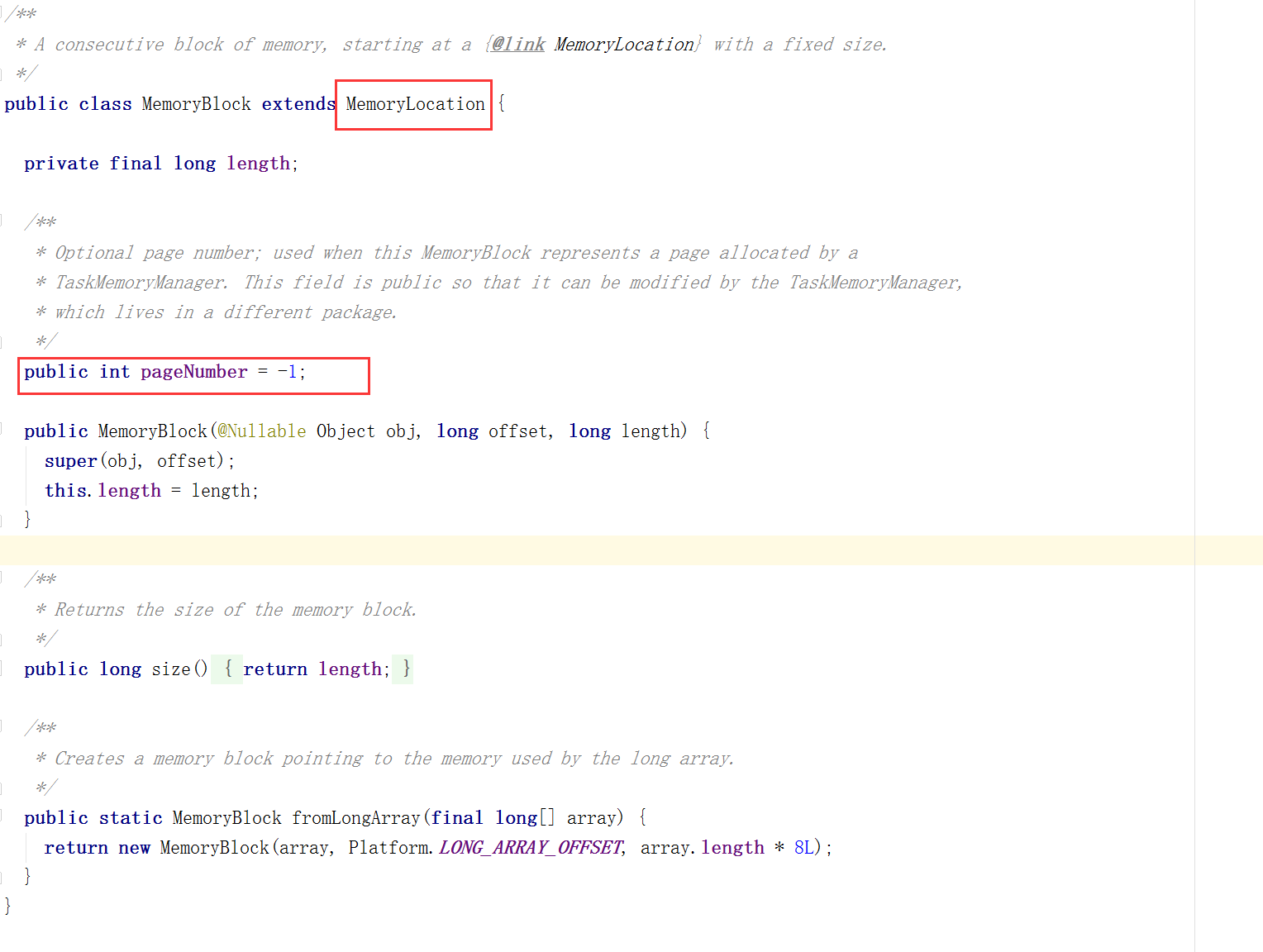
从MemoryBlock的结构可以看到除了记录page编号外,MemoryBlock内部组成是MemoryLocation。
图7. MemoryLocation
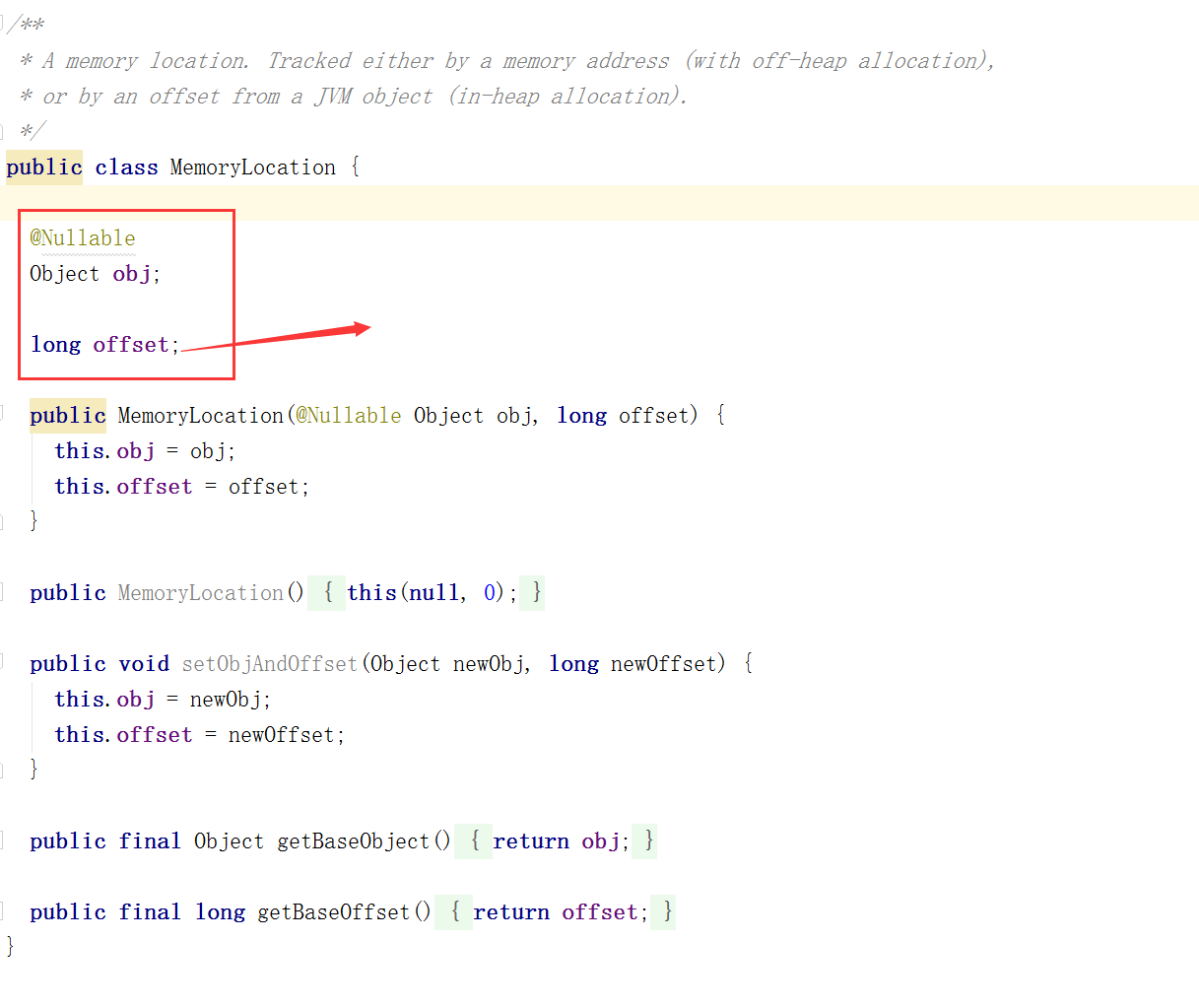
在MemoryLocation中,重要的就是记录了对象及初始位置的定位offset。
Sort Based Shuffle里存储数据的对象是PartitionedAppendOnlyMap,这只是一个放在JVM heap里普通对象。在Tungsten-sort中,它被替换成了类似操作系统内存页的对象。如果无法申请新的Page,这个时候就要执行spill溢写操作,将数据写到磁盘。具体触发条件和Sort Based Shuffle 类似。
Spark 默认开启的是Sort Based Shuffle, 如需打开Tungsten-sort 通过设置:
spark.shuffle.manager=tungsten-sort具体的实现类是:
org.apache.spark.shuffle.sort.UnsafeShuffleWriter
数据一旦进来,就使用shuffle write进行序列化,在序列化的二进制基础上进行排序,这样就可以减少内存的GC。这种优化需要序列化器可以在不反序列化的情况下重新排序。
当且仅当下面条件都满足时,才能使用Tungsten-sort Shuffle:
1)Shuffle 文件的数量不能大于 16777216
final int numPartitions = handle.dependency().partitioner().numPartitions();
if (numPartitions > SortShuffleManager.MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE()) {
throw new IllegalArgumentException(
“UnsafeShuffleWriter can only be used for shuffles with at most ” +
SortShuffleManager.MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE() +
” reduce partitions”);
}
2)Shuffle 的序列化器需要是 KryoSerializer 或者 Spark SQL’s 自定义的一些序列化方式. 因为整个过程是追求不反序列化的,所以不能做aggregation
3)Shuffle dependency 不能带有aggregation 或者输出不需要排序
4)序列化时,单条记录不能大于 128 MB
要理解上面的限制,需要了解一下Tungsten内存模型:
图8. Tungsten内存模型
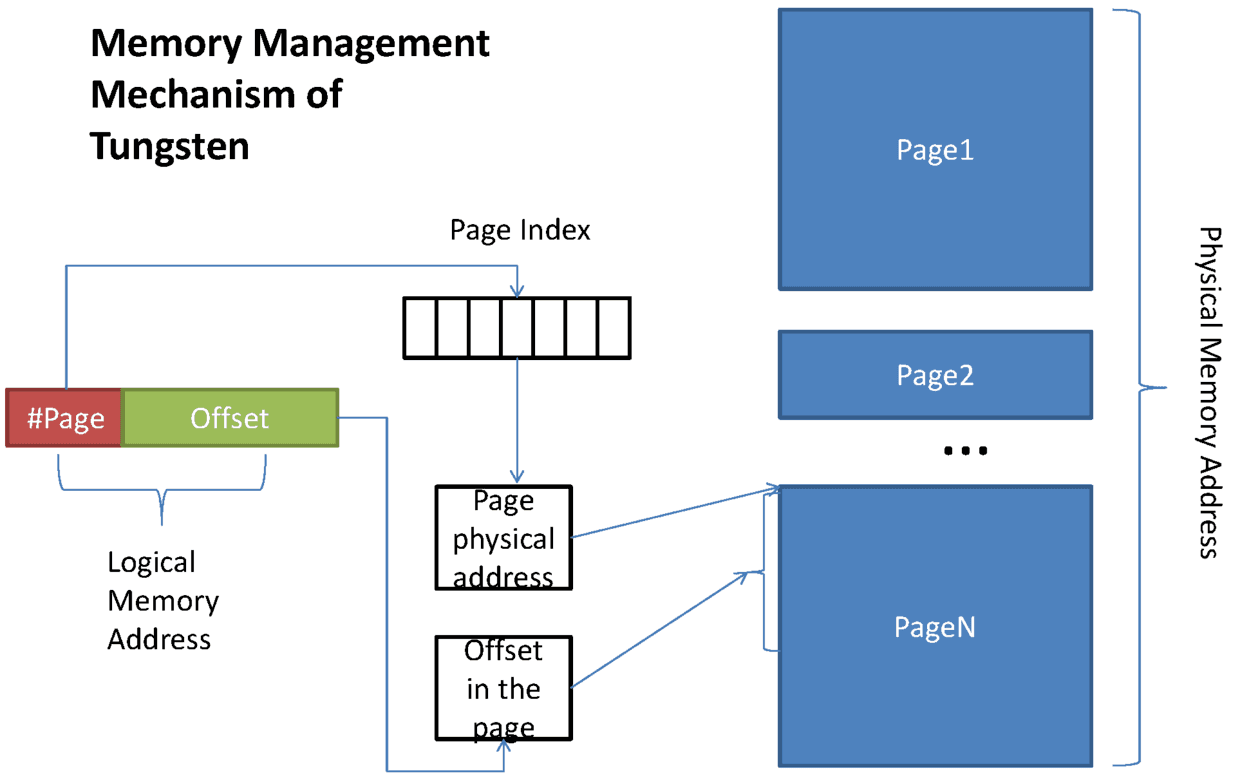
这张图画的是 on-heap 的内存逻辑图,其中:
#Page 部分为13bit, Offset 为51bit, 我们发现 2^51 是远大于128M的。
在Shuffle的过程中,对51bit 做了压缩,只使用了27bit,具体如下:
[24 bit partition number] [13 bit memory page number][27 bit offset in page]
预留24bit给partition number,留给后面的排序用,上面的好几个限制都是因为这个指针引起的:
1)第一个是partition 的限制,Shuffle 文件的数量不能大于 16777216, 就是因为partition number 使用24bit 表示,2^24=16777216;
2)第二个是page number:2^13;
3)第三个是偏移量最大能表示到: 2^27=128M,那么一个task 能管理到的内存是受限于这个指针的,最多是: 2^13 * 128M ,也就是1TB左右。
有了这个指针,我们就可以定位和管理到off-heap (堆外内存)或者 on-heap(堆内内存)里的内存了。
这个模型的内存管理非常高效,预估PartitionedAppendOnlyMap的内存是非常困难的,但是通过现在这种内存管理机制,是非常快速并且精确的。
前面提到的限制:Shuffle dependency 不能带有aggregation 或者输出需要排序,这是因为后续Shuffle Write进行的sort 部分,只对前面24bit的partiton number 进行排序,key的值没有被编码到这个指针,所以没办法进行排序。同时因为整个过程是追求不反序列化的,所以不能做aggregation。
UnsafeShuffleWriter核心方法解析:
UnsafeShuffleWriter的构造函数:
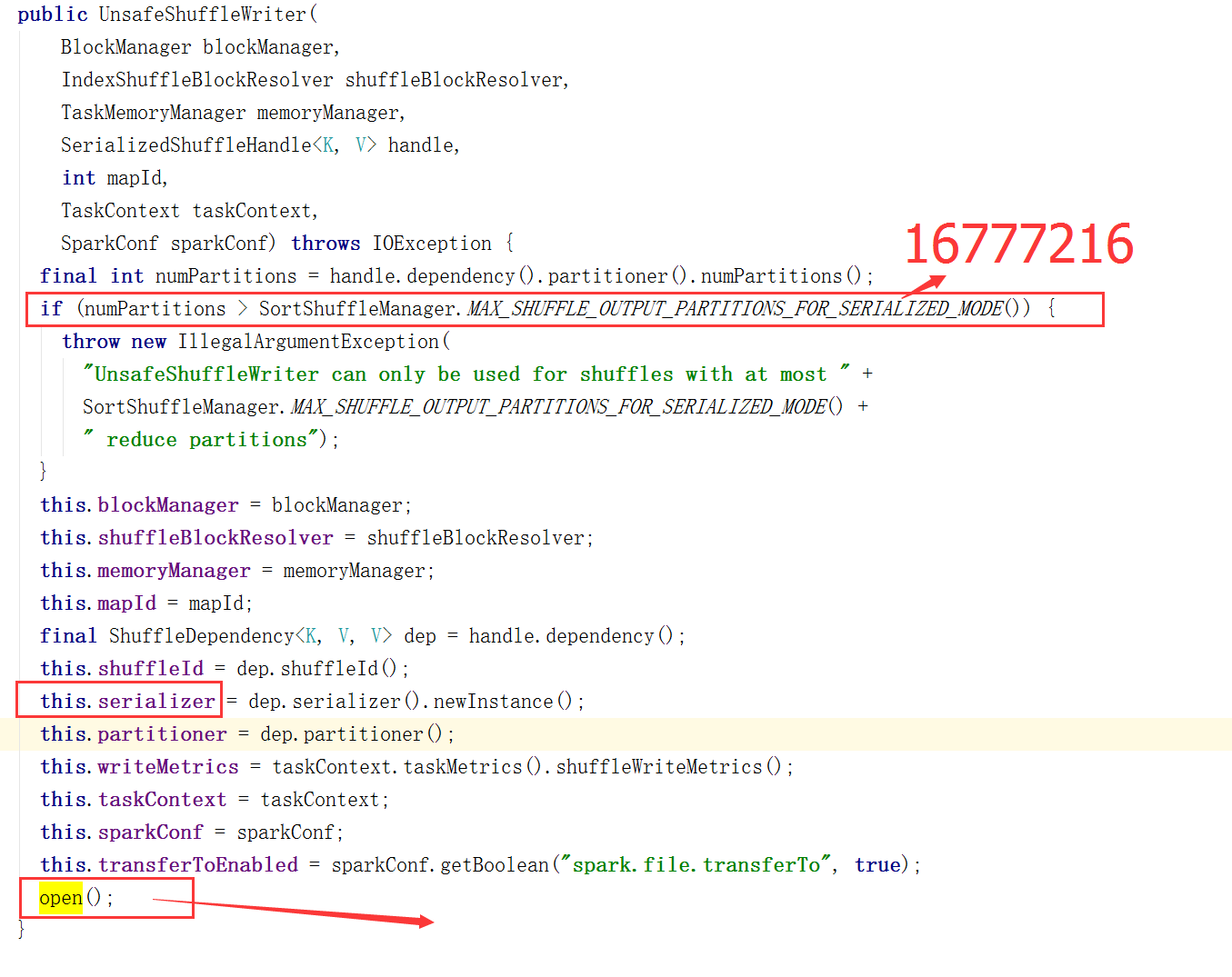
UnsafeShuffleWriter.open初始化方法:
private void open() throws IOException {
assert (sorter == null);
sorter = new ShuffleExternalSorter(
memoryManager,
blockManager,
taskContext,
INITIAL_SORT_BUFFER_SIZE,
partitioner.numPartitions(),
sparkConf,
writeMetrics);
serBuffer = new MyByteArrayOutputStream(1024 * 1024);
serOutputStream = serializer.serializeStream(serBuffer);
}创建ShuffleExternalSorter,serBuffer大小为1M,通过MyByteArrayOutputStream直接对内存操作。
MyByteArrayOutputStream类:
/** Subclass of ByteArrayOutputStream that exposes `buf` directly. */
private static final class MyByteArrayOutputStream extends ByteArrayOutputStream {
MyByteArrayOutputStream(int size) { super(size); }
public byte[] getBuf() { return buf; }
}write方法:
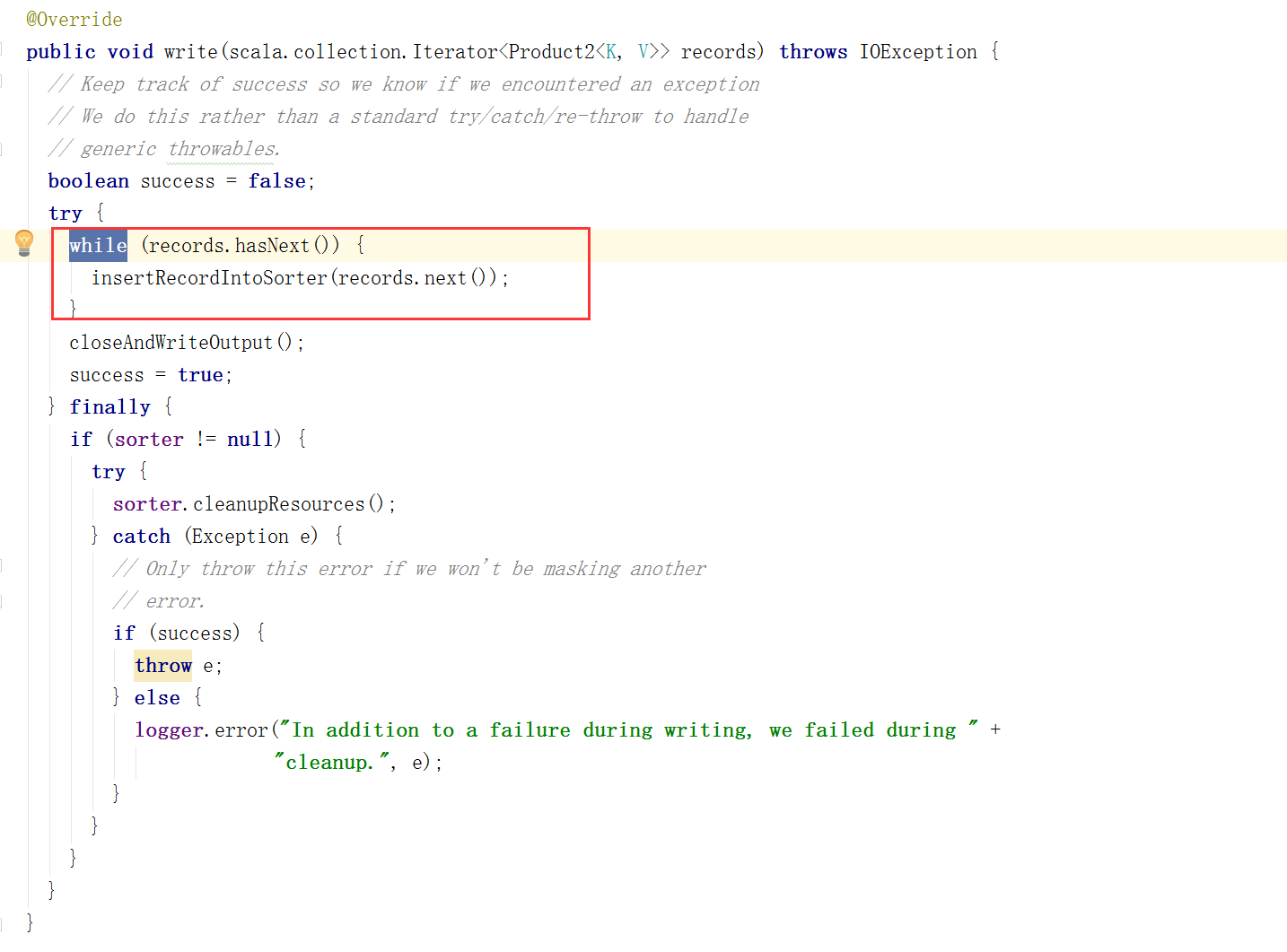
循环记录,通过insertRecordIntoSorter方法吧数据写入ShuffleExternalSorter。
insertRecordIntoSorter方法:
@VisibleForTesting
void insertRecordIntoSorter(Product2<K, V> record) throws IOException {
assert(sorter != null);
final K key = record._1();
final int partitionId = partitioner.getPartition(key);
serBuffer.reset();
serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
serOutputStream.flush();
final int serializedRecordSize = serBuffer.size();
assert (serializedRecordSize > 0);
sorter.insertRecord(
serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
}其中,serBuffer在上面的open方法初始化为serBuffer = new MyByteArrayOutputStream(1024 * 1024); 大小为1M,而且是序列化之后的数据。
sorter.insertRecord方法:
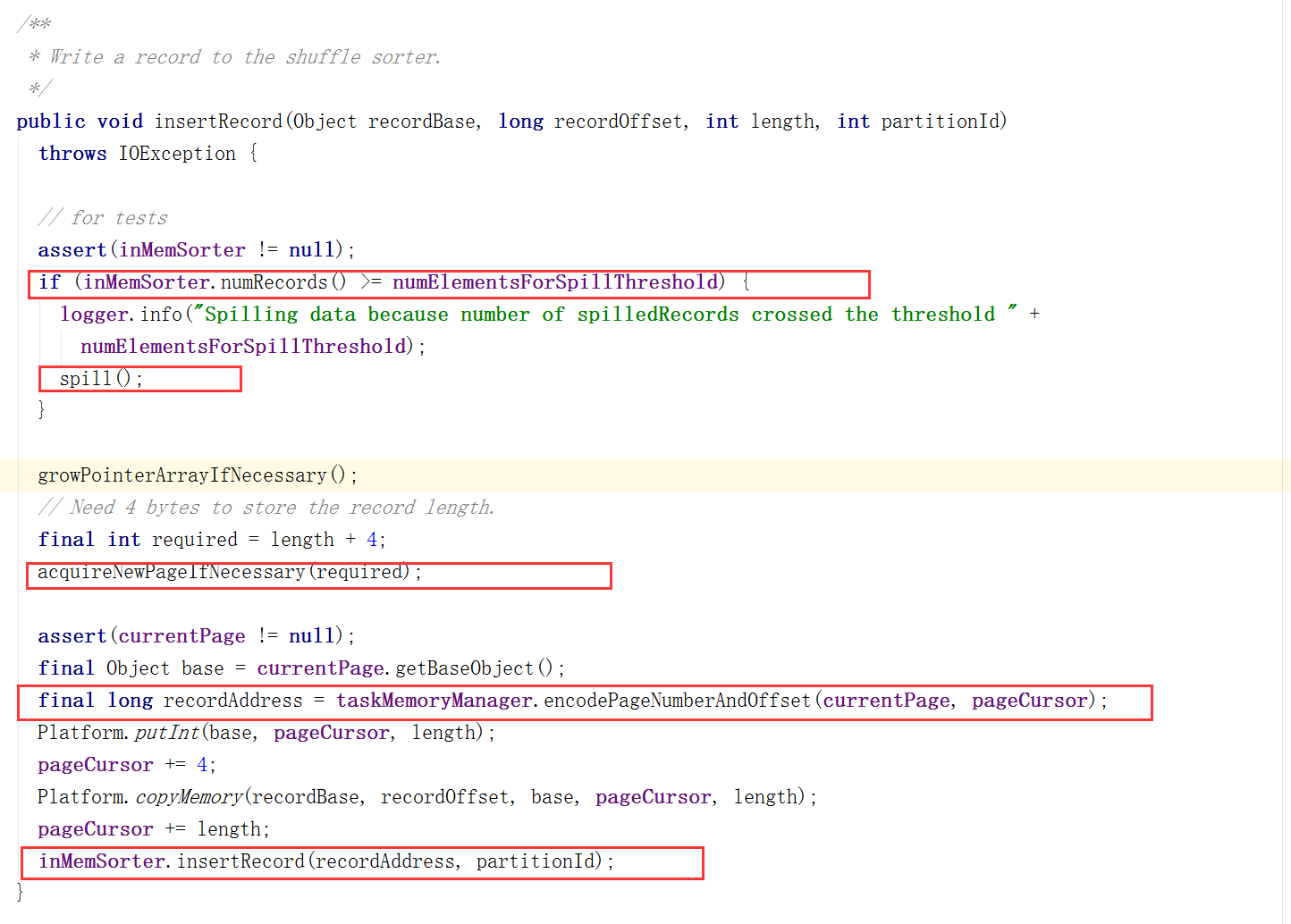
在插入前首先分配内存,再根据每条数据,采用游标的方式进行遍历,计算并找到recordAddress,完成插入操作。
MemoryManager.tungstenMemoryAllocator内存分配
/**
* Allocates memory for use by Unsafe/Tungsten code.
*/
private[memory] final val tungstenMemoryAllocator: MemoryAllocator = {
tungstenMemoryMode match {
case MemoryMode.ON_HEAP => MemoryAllocator.HEAP
case MemoryMode.OFF_HEAP => MemoryAllocator.UNSAFE
}在内存分配时,会有两种分配方式UNSAFE和HEAP,内部各有一套自己的实现机制。
MemoryAllocator接口定义
public interface MemoryAllocator {
/**
* Allocates a contiguous block of memory.
* Note that the allocated memory is not guaranteed
* to be zeroed out (call `zero()` on the result if this is necessary).
*/
MemoryBlock allocate(long size) throws OutOfMemoryError;
void free(MemoryBlock memory);
MemoryAllocator UNSAFE = new UnsafeMemoryAllocator();
MemoryAllocator HEAP = new HeapMemoryAllocator();
}














 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









