







首先,贴上经典示例WordCount的代码
package com.dt.spark.apps.cores
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("Word Count").master("local[4]")
.getOrCreate()
spark.sparkContext.textFile("C://frank//Spark//lib//spark-2.0.0-bin-hadoop2.7//README.md")
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
.foreach(pair => println(pair._1 + ":" + pair._2))
while (true) {}
spark.stop()
}
}
代码解析:
1) 读取数据
先从hadoop层面来理解数据,在textFile方法中,原始数据被分割成若干split,每个split作为一个map任务的输入。 split 以128M block为单位,除非最后一个split可能会比128M小,这样保证每一行数据都是完整的。hadoopFile读进来的数据是一个个split,split里面是一行行的数据,包括行号和具体的数据。
下面是textFile方法代码:
/**
* Read a text file from HDFS, a local file system (available on all nodes), or any
* Hadoop-supported file system URI, and return it as an RDD of Strings.
*/
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}2) flatMap
读到数据之后,就是flatMap对集合进行操作,对split的每一行内容进行操作,以空格进行切分每个单词。通过flatMap操作,得到一个好大的数组,仅仅返回了一个数组对象!
数组中的每个成员也就是split,现在这个split中的数据是单词的实例。
3)map
然后进行map操作,对每个元素进行操作,其实是对split中的每个元素,也就是对单词实例进行操作,生成一个tuple:(word,1),把每个单词实例计数为1。
图1:DAG Visualization
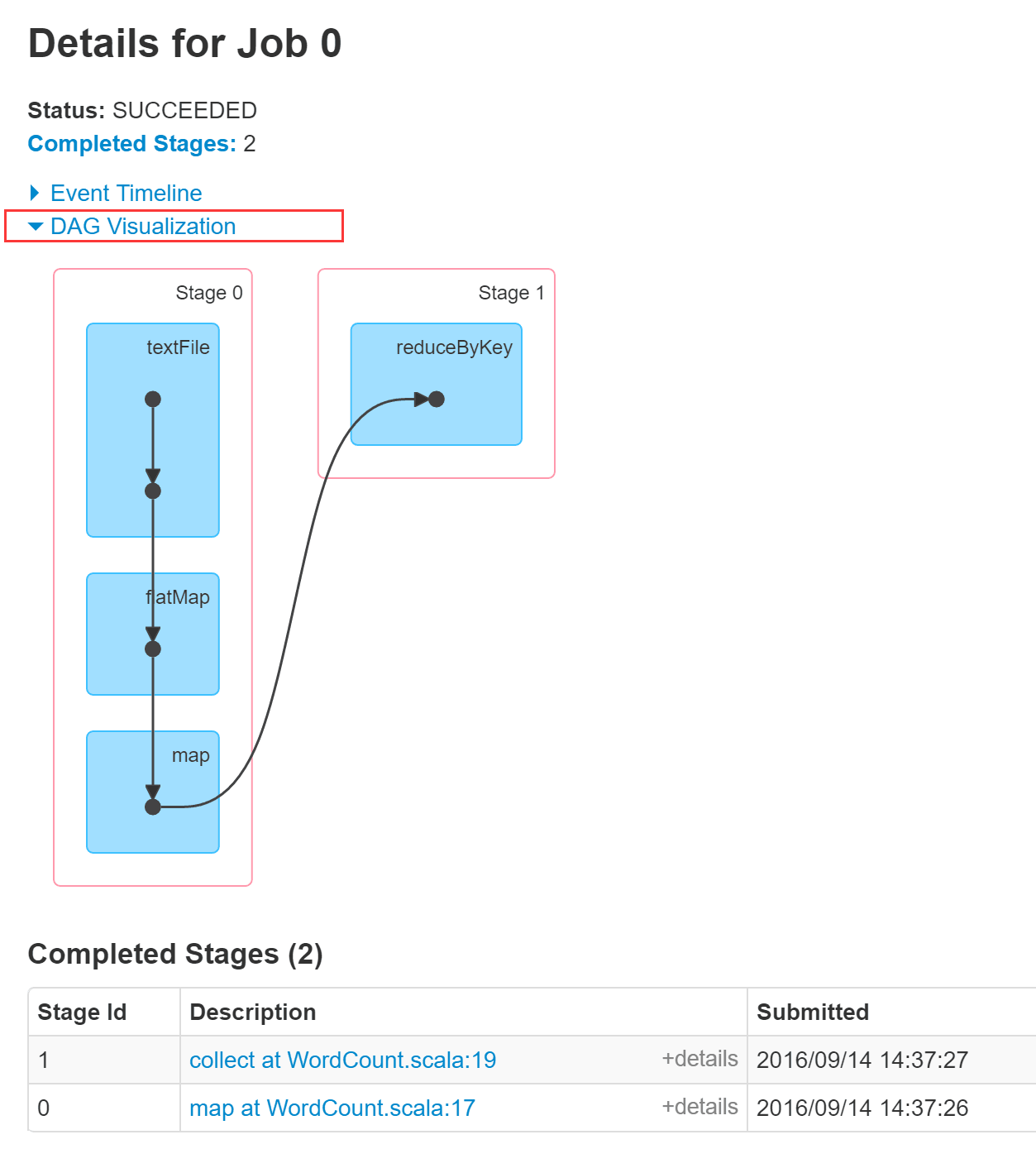
在Stage 0中:flatMap和map 产生的是MapPartitionsRDD
在Stage 1中:
reduceByKey 产生的是ShuffledRDD,全局级别的统计,在所有数据分片上,统计每个单词的总次数。基于Stage 0的输出进行计算。
4)collect
数据的采集回收给Driver
5)foreach
打印collect中的数据
总结:
假设1000个文件作为1000个数据分片,那么就有1000个并行的任务这1000个并行的任务,处理的逻辑是完全一样的,由Driver发送到Executor上,在Executor的线程池执行这1000个任务,线程池中的多条线程按处理能力,分批次并行执行这些任务,这也就是并行计算。在当前Stage,业务逻辑一样,只是数据不一样。
如果当前Stage没有计算完,下一个Stage就不能计算,Executor的计算结果,先保留在当前节点上,再汇报给Driver,这样Driver就知晓上一个Stage的数据输出在哪里了,就可以提供给下一个Stage的输入。
线程池中的线程持续复用。
对于某个单词,比如hadoop这个单词,出现了5000次,相同的Key被抓取到某个线程中进行处理,先从所有的节点上抓取过来,汇集给一个任务,而不是同时在全部节点统计。
并行度也就是表示Task的个数,并行度,下一个Stage和上一个Stage的并行度是一样的。















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









