







七种排序算法总结(冒泡、插入、选择、希尔、归并、堆、快速)
首先声明一下,本文只对七种排序算法做简单总结,并参照一些资料给出自己的代码实现,并没有对某种算法理论讲解,更详细的
了 解可以参考以下资料(本人参考):
1、《 data structure and algorithm analysis in c 》
2、《大话数据结构》
3、 http://blog.csdn.net/morewindows/article/details/7961256
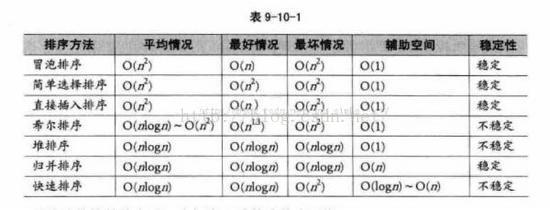
一、冒泡排序
基本思想是:两两比较相邻记录的关键字,如果反序则交换
冒泡排序时间复杂度最好的情况为O(n),最坏的情况是O(n^2)
改进思路1:设置标志位,明显如果有一趟没有发生交换(flag = flase),说明排序已经完成
改进思路2:记录一轮下来标记的最后位置,下次从头部遍历到这个位置就Ok
二、直接插入排序
将一个记录插入到已经排好序的有序表中, 从而得到一个新的,记录数增1的有序表
时间复杂度也为O(n^2), 比冒泡法和选择排序的性能要更好一些
三、简单选择排序
通过n-i次关键字之间的比较,从n-i+1 个记录中选择关键字最小的记录,并和第i(1<=i<=n)个记录交换之
尽管与冒泡排序同为O(n^2),但简单选择排序的性能要略优于冒泡排序
四、希尔排序
先将整个待排元素序列分割成若干子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排
序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。其时间复杂度为O(n^3/2),要好于直接
插入排序的O(n^2)
五、归并排序
假设初始序列含有n个记录,则可以看成n个有序的子序列,每个子序列的长度为1,然后两两归并,得到(不小于n/2的最小整数)个长度为2
或1的有序子序列,再两两归并,...如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序。 时间复杂度为
O(nlogn),空间复杂度为O(n+logn),如果非递归实现归并,则避免了递归时深度为logn的栈空间 空间复杂度为O(n)
六、堆排序
堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆; 或者每个节点的值都小于或等于其左
右孩子节点的值,称为小顶堆。
堆排序就是利用堆进行排序的方法.基本思想是:将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶 的根结点.将它移
走(其实就是将其与堆数组的末尾元素交换, 此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元
素的次大值.如此反复执行,便能得到一个有序序列了。 时间复杂度为 O(nlogn),好于冒泡,简单选择,直接插入的O(n^2)
七、快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。时间复杂度为O(nlogn)
下文没有给出快速排序的实现,参考以前的 文章 。
代码实现:(含3种swap交换函数,6个排序算法,不含快速排序)
C++ Code
#include <iostream>
using namespace std;
void swap1( int *left, int *right)
{
int temp = *left;
*left = *right;
*right = temp;
}
void swap2( int &left, int &right)
{
int temp = left;
left = right;
right = left;
}
void swap3( int &left, int &right)
{
if (left != right) //如果相同按下面方法会被置0
{
left ^= right;
right ^= left;
left ^= right;
}
}
/*****************************************************************/
/* 冒泡排序时间复杂度最好的情况为O(n),最坏的情况是O(n^2)
* 基本思想是:两两比较相邻记录的关键字,如果反序则交换 */
void BubbleSort1( int arr[], int num)
{
int i, j;
for (i = 0 ; i < num; i++)
{
for (j = 1 ; j < num - i; j++)
{
if (arr[j - 1 ] > arr[j])
swap1(&arr[j - 1 ], &arr[j]);
}
}
}
// 改进思路:设置标志位,明显如果有一趟没有发生交换(flag = flase),说明排序已经完成.
void BubbleSort2( int arr[], int num)
{
int k = num;
int j;
bool flag = true ;
while (flag)
{
flag = false ;
for (j = 1 ; j < k; j++)
{
if (arr[j - 1 ] > arr[j])
{
swap1(&arr[j - 1 ], &arr[j]);
flag = true ;
}
}
k--;
}
}
//改进思路:记录一轮下来标记的最后位置,下次从头部遍历到这个位置就Ok
void BubbleSort3( int arr[], int num)
{
int k, j;
int flag = num;
while (flag > 0 )
{
k = flag;
flag = 0 ;
for (j = 1 ; j < k; j++)
{
if (arr[j - 1 ] > arr[j])
{
swap1(&arr[j - 1 ], &arr[j]);
flag = j;
}
}
}
}
/*************************************************************************/
/**************************************************************************/
/*插入排序: 将一个记录插入到已经排好序的有序表中, 从而得到一个新的,记录数增1的有序表
* 时间复杂度也为O(n^2), 比冒泡法和选择排序的性能要更好一些 */
void InsertionSort( int arr[], int num)
{
int temp;
int i, j;
for (i = 1 ; i < num; i++)
{
temp = arr[i];
for (j = i; j > 0 && arr[j - 1 ] > temp; j--)
arr[j] = arr[j - 1 ];
arr[j] = temp;
}
}
/****************************************************************************/
/*希尔排序:先将整个待排元素序列分割成若干子序列(由相隔某个“增量”的元素组成的)分别进行
直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,
再对全体元素进行一次直接插入排序。其时间复杂度为O(n^3/2),要好于直接插入排序的O(n^2) */
void ShellSort( int arr[], int num)
{
int i, j, gap, temp;
for (gap = num / 2 ; gap > 0 ; gap /= 2 ) //gap 的取值方法不一
{
for (i = gap; i < num; i++)
{
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
arr[j + gap] = arr[j];
arr[j + gap] = temp;
}
}
}
/**************************************************************************/
/* 简单选择排序(simple selection sort) 就是通过n-i次关键字之间的比较,从n-i+1
* 个记录中选择关键字最小的记录,并和第i(1<=i<=n)个记录交换之
* 尽管与冒泡排序同为O(n^2),但简单选择排序的性能要略优于冒泡排序 */
void SelectSort( int arr[], int num)
{
int i, j, Mindex;
for (i = 0 ; i < num; i++)
{
Mindex = i;
for (j = i + 1 ; j < num; j++)
{
if (arr[j] < arr[Mindex])
Mindex = j;
}
swap1(&arr[i], &arr[Mindex]);
}
}
/********************************************************************************/
/*假设初始序列含有n个记录,则可以看成n个有序的子序列,每个子序列的长度为1,然后
* 两两归并,得到(不小于n/2的最小整数)个长度为2或1的有序子序列,再两两归并,...
* 如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序
* 时间复杂度为O(nlogn),空间复杂度为O(n+logn),如果非递归实现归并,则避免了递归时深度为logn的栈空间
* 空间复杂度为O(n) */
/*lpos is the start of left half, rpos is the start of right half*/
void merge( int a[], int tmp_array[], int lpos, int rpos, int rightn)
{
int i, leftn, num_elements, tmpos;
leftn = rpos - 1 ;
tmpos = lpos;
num_elements = rightn - lpos + 1 ;
/*main loop*/
while (lpos <= leftn && rpos <= rightn)
if (a[lpos] <= a[rpos])
tmp_array[tmpos++] = a[lpos++];
else
tmp_array[tmpos++] = a[rpos++];
while (lpos <= leftn) /*copy rest of the first part*/
tmp_array[tmpos++] = a[lpos++];
while (rpos <= rightn) /*copy rest of the second part*/
tmp_array[tmpos++] = a[rpos++];
/*copy array back*/
for (i = 0 ; i < num_elements; i++, rightn--)
a[rightn] = tmp_array[rightn];
}
void msort( int a[], int tmp_array[], int left, int right)
{
int center;
if (left < right)
{
center = (right + left) / 2 ;
msort(a, tmp_array, left, center);
msort(a, tmp_array, center + 1 , right);
merge(a, tmp_array, left, center + 1 , right);
}
}
void merge_sort( int a[], int n)
{
int *tmp_array;
tmp_array = ( int *)malloc(n * sizeof ( int ));
if (tmp_array != NULL )
{
msort(a, tmp_array, 0 , n - 1 );
free(tmp_array);
}
else
printf( "No space for tmp array!\n" );
}
/************************************************************************************/
/* 堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆;
* 或者每个节点的值都小于或等于其左右孩子节点的值,称为小顶堆*/
/*堆排序就是利用堆进行排序的方法.基本思想是:将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶
* 的根结点.将它移走(其实就是将其与堆数组的末尾元素交换, 此时末尾元素就是最大值),然后将剩余的n-1个序列重新
* 构造成一个堆,这样就会得到n个元素的次大值.如此反复执行,便能得到一个有序序列了
*/
/* 时间复杂度为 O(nlogn),好于冒泡,简单选择,直接插入的O(n^2) */
// 构造大顶堆
void HeapAdjust( int arr[], int i, int num)
{
int j, temp;
temp = arr[i];
for (j = 2 * i + 1 ; j < num; j = 2 * j + 1 )
{
if (j + 1 < num && arr[j + 1 ] > arr[j])
j++; //如果右孩子比左孩子大,记录位置
if (arr[j] <= temp)
break ; //如果父节点大,没必要交换,直接退出循环
arr[i] = arr[j]; //否则交换
i = j;
}
arr[i] = temp;
}
void HeapSort( int arr[], int num)
{
int i;
for (i = num / 2 - 1 ; i >= 0 ; i--)
HeapAdjust(arr, i, num); //构造大顶堆
for (i = num - 1 ; i >= 1 ; i--)
{
swap1(&arr[i], &arr[ 0 ]); //将堆顶放置最后
HeapAdjust(arr, 0 , i); //重新构造大顶堆
}
}
int main( void )
{
int arr[] = { 9 , 2 , 5 , 8 , 3 , 4 , 7 , 1 , 6 , 10 };
HeapSort(arr, 10 );
for ( int i = 0 ; i < 10 ; i++)
cout << arr[i] << ' ' ;
cout << endl;
return 0 ;
} 













 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









