







Ambry简介
LinkedIn开源了多媒体对象存储数据库Ambry,开源不久,算是一个很新的事物。Ambry用来做对象存储,非常适合用于存储像LinkedIn这种社交媒体网站的对象数据(如图片,视频等等)。
LinkedIn过去使用的是一种闭源技术,非常复杂,而且也难以随着用户数和数据量的增长而扩展。LinkedIn工程总监Sriram Subramanian在博客中指出:
我们开始尝试在市场中寻找更好的替代方案,包括各种分布式文件系统、存储一体机、云服务和内部部署方案都考察过,通过权衡我们的设计目标和得失后发现,我们需要自己开发一个能更好满足我们需求的方案——Ambry,如今Ambry已经在LinkedIn的生产环境中使用多年,表现良好。
之前我的博客翻译了Ambry作者的官方博客,大家感兴趣的可以去看看:
- 分布式对象存储Ambry - 官方博客翻译与摘录(1)背景介绍
- 分布式对象存储Ambry - 官方博客翻译与摘录(2)Ambry设计目标
- 分布式对象存储Ambry - 官方博客翻译与摘录(3)整体设计
- 分布式对象存储Ambry - 官方博客翻译与摘录(4)路由设计
- 分布式对象存储Ambry - 官方博客翻译与摘录(5)运维与迁移
Ambry可以简单地理解成为一个静态资源服务器,实现CDN网络的功能。Ambry的优点在于:
- 简单的高可用以及水平可扩展
- 低操作与运维开销
- 低MTTR(Mean Time To Recover)
- 跨机房多活
- 对于大小对象操作灵活并高效
- 节约成本(支持P2P,硬盘阵列,磁盘交换等等)
我们利用Ambry,可以很方便的部署一个静态资源服务器集群,从而快捷稳定的提供内容服务。
Ambry集群部署
官网没有集群部署的教程,这里补充下。
代码编译打包
我们先把代码从github拉下来,本地编译,我的IDE用的IDEA,变异的过程中,发现有个依赖失效了,所以一直报:Error:Cause: peer not authenticated;
在项目根目录build.gradle中的第15行:
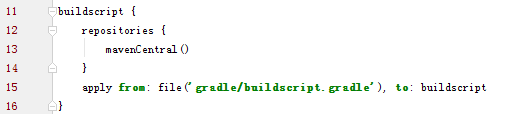
gradle的buildscript还依赖于buildscript.gradle,这个文件中保存着一个关于gradle-license-plugin的依赖(如果不能翻墙,这个依赖可能下载不到,所以我们需要修改库地址和库依赖版本),我们将它改变成maven库中的gradle-license-plugin对应的版本依赖:
repositories {
repositories {
// For license plugin.
maven {
url "http://repo1.maven.org/maven2"
}
}
}
dependencies {
classpath "nl.javadude.gradle.plugins:license-gradle-plugin:0.10.0"
}
之后,就可以导入这个项目,执行./gradlew allJar
会生成一个ambry.jar的文件。
Ambry分为前端与后端。Ambry包含负责保存和检索数据的数据节点(data node),前端节点(Frontend node)将请求经过预处理发送到后端数据节点,并且集群管理者(Cluster manager)管理并协调数据节点上的数据。数据节点之间互相复制数据,并且可以跨机房复制,并需要保证写之后读的一致性。前端提供HTTP API,包括POST,GET和DELETE对象。同样的,这个路由库可以直接被客户端调用以提升性能。
部署设计
一个简单的部署架构(不包含集群管理者)如下图所示:
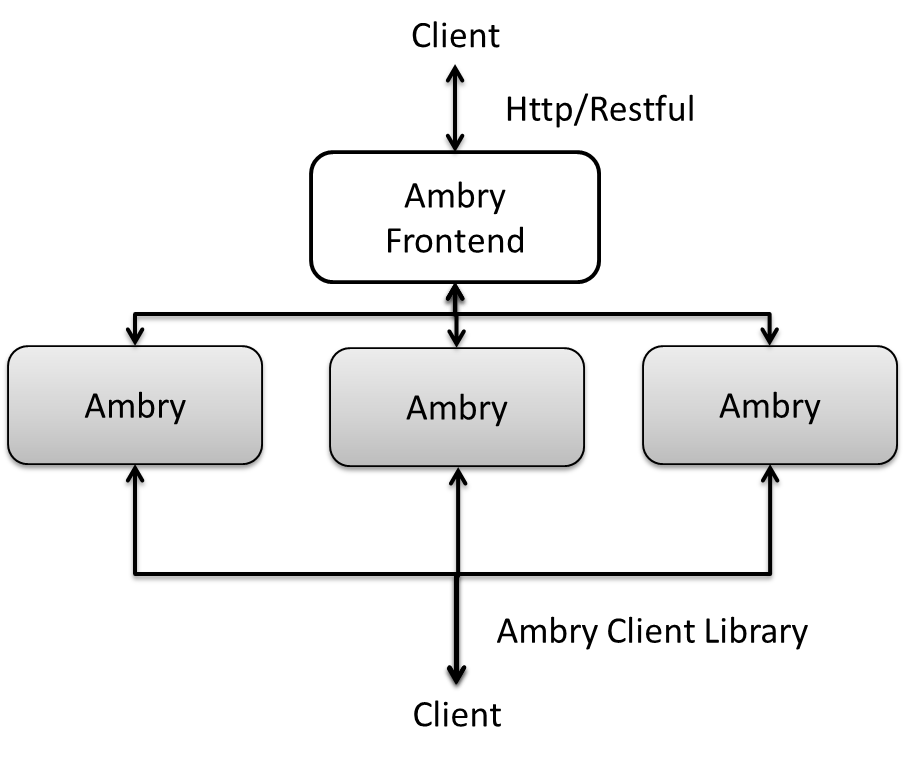
Ambry代码中本身不包含集群管理者,Ambry的集群配置有配置文件,这个分布式配置管理中心一般基于zookeeper实现(不得不说,LinkedIn的所有开源分布式框架,都离不开Zookeeper)。国内的配置中心还有disconf(baidu的)和diamond(阿里的),这里Ambry的集群相关的配置文件都是Json格式的,利用原生的zookeeper就可以实现。
我们下面的示例配置将按照上面的图配置,不会加入集群配置中心,每个后台Ambry数据节点的集群配置Json文件都是保存在本地,配置中心的部署方法,在后面的关于数据迁移与横向扩展相关章节文章中会涉及。
我们现在拿到了Ambry.jar,但是还要一些配置文件,而且,启动脚本也还没提供。我们先设计下这个集群的基本配置:
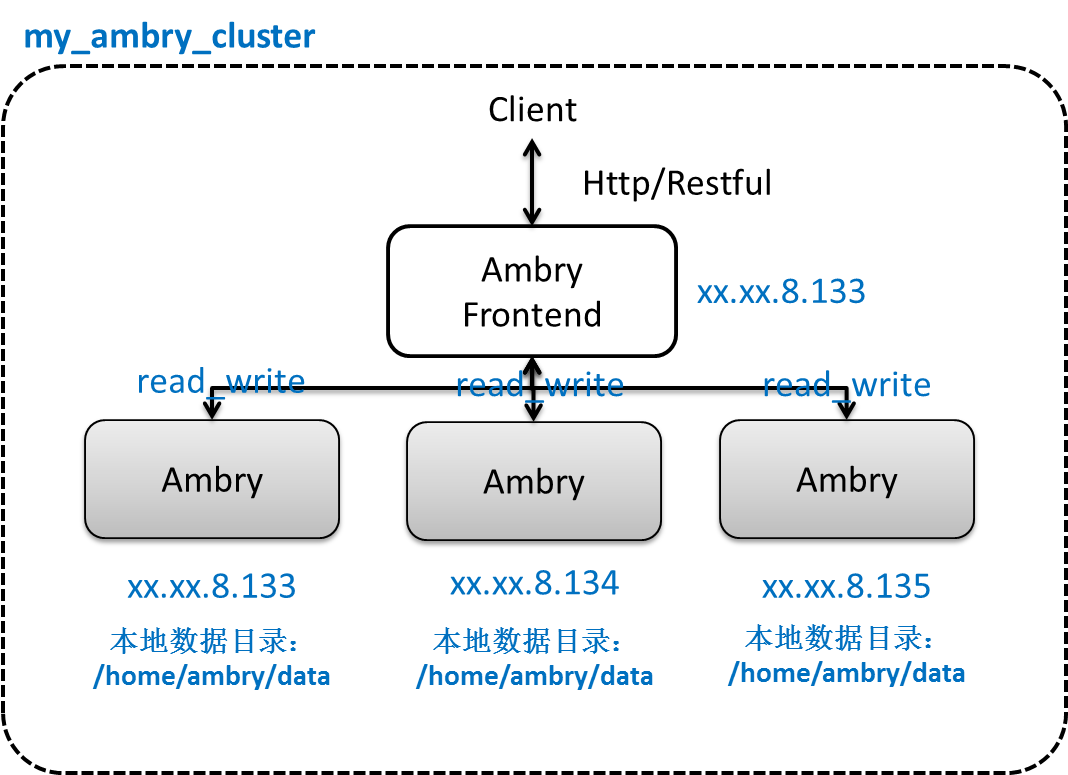
我们建立一个三个节点的在同一个机房的集群,将后端Ambry节点部署在xx.xx.8.133,xx.xx.8.134,xx.xx.8.135这三台机器上,同时,数据目录都是本机的/home/ambry/data这个目录,每个节点都是读写节点。前端节点部署在xx.xx.8.133这台机器上。集群名称叫做my_ambry_cluster。
接下来编写配置文件:
首先是集群硬件配置hardware_layout.json:
{
//填写集群名称
"clusterName": "my_ambry_cluster",
"version": 1,
"datacenters": [
{
"dataNodes": [
{
"disks": [
{
//填写容量,这里是20G
"capacityInBytes": 21474836480,
"hardwareState": "AVAILABLE",
//保存路径
"mountPath": "/home/ambry/data"
}
],
"hardwareState": "AVAILABLE",
"hostname": "xx.xx.8.133",
"port": 6670,
"sslport": 7670
},
{
"disks": [
{
"capacityInBytes": 21474836480,
"hardwareState": "AVAILABLE",
"mountPath": "/home/ambry/data"
}
],
"hardwareState": "AVAILABLE",
"hostname": "xx.xx.8.134",
"port": 6670,
"sslport": 7670
}
,
{
"disks": [
{
"capacityInBytes": 21474836480,
"hardwareState": "AVAILABLE",
"mountPath": "/home/ambry/data"
}
],
"hardwareState": "AVAILABLE",
"hostname": "xx.xx.8.135",
"port": 6670,
"sslport": 7670
}
],
"name": "Datacenter"
}
]
}
接着是集群逻辑分片设置partition_layout.json:
{
"clusterName": "my_ambry_cluster",
"version": 1,
"partitions": [
{
"id": 0,
"partitionState": "READ_WRITE",
//这里是10G,因为我们下面的配置是put成功一个,备份一个,所以,每个硬盘20G其实是存储10G数据还有10G其他的备份
"replicaCapacityInBytes": 10737418240,
"replicas": [
{
"hostname": "xx.xx.8.133",
"mountPath": "/home/ambry/data",
"port": 6670
},
{
"hostname": "xx.xx.8.134",
"mountPath": "/home/ambry/data",
"port": 6670
},
{
"hostname": "xx.xx.8.135",
"mountPath": "/home/ambry/data",
"port": 6670
}
]
}
]
}Server数字证书集群配置
由于集群配置必须要SSL连接,所以,需要在每一台机器上生成数字证书。这里用java自带的keystore生成数字证书。
Keytool是一个Java数据证书的管理工具。Keytool将密钥(key)和证书(certificates)存在一个称为keystore的文件中在keystore里。
在每台机器上执行:
$ keytool -genkeypair -alias certificatekey -validity 7000 -keystore keystore.jks
$ keytool -export -alias certificatekey -keystore keystore.jks -rfc -file selfsignedcert.cer
$ keytool -import -alias certificatekey -file selfsignedcert.cer -keystore truststore.jks
记住你的配置的keytool文件位置还有密码,在每台机器上配置server.ssl.properties:
#填写本机的ip地址,这里举例
host.name=xx.xx.8.133
port=6670
#the path to the store. this location must exist
ssl.keystore.path=/home/ambry/keystore.jks
# set key store password. this cannot be blank
ssl.keystore.password=xxxxxx
ssl.key.password=xxxxxxxxxxx
# the path to the trust store. this location must exist
ssl.truststore.path=/home/ambry/truststore.jks
# set trust store password. this cannot be blank
ssl.truststore.password=xxxxxxxxx
之后,我们在每台机器上面启动:
java -Xms2g -Xmx4g -Dlog4j.configuration=file:./log4j.properties -jar ambry.jar --serverPropsFilePath ./server.ssl.properties --hardwareLayoutFilePath ./hardware_layout.json --partitionLayoutFilePath ./partition_layout.json & > logs/server.log看到日志中启动成功,即可。
启动前端
前端也会依赖–hardwareLayoutFilePath ./hardware_layout.json –partitionLayoutFilePath ./partition_layout.json这两个配置,另外还有前端配置文件frontend.properties:
# rest server
rest.server.blob.storage.service.factory=com.github.ambry.frontend.AmbryBlobStorageServiceFactory
# router
# 如果是本机,就填写localhost,因为不参与端口监听
router.hostname=localhost
# datacenter一定要填写之前hardware_layout.json中的
router.datacenter.name=Datacenter
# 在put请求时,只要成功一个partition就算是成功
router.put.success.target=1
# coordinator
# 如果是本机,就填写localhost,因为不参与端口监听
coordinator.hostname=localhost
# datacenter一定要填写之前hardware_layout.json中的
coordinator.datacenter.name=Datacenter
# 超时限制,在某个请求处理过长时间时会停掉
coordinator.operation.timeout.ms=100000
# 连接池相关,这个需要设置的长一些,否则大文件来不及上传或者读取
connectionpool.read.timeout.ms=100000
connectionpool.connect.timeout.ms=100000
# netty连接空闲时间,这个需要设置的长一些,否则大文件来不及上传
netty.server.idle.time.seconds = 600填写好后,启动:
java -Dlog4j.configuration=file:log4j.properties -cp "*" com.github.ambry.frontend.AmbryFrontendMain --serverPropsFilePath frontend.properties --hardwareLayoutFilePath sfpp_prod_ambry_hardware_layout.json --partitionLayoutFilePath sfpp_prod_ambry_partition_layout.json &
常见问题
- 找不到某个配置文件:
对于后端:–serverPropsFilePath ./server.ssl.properties –hardwareLayoutFilePath ./hardware_layout.json –partitionLayoutFilePath ./partition_layout.json 这三个参数必须正确而且文件存在。 - 某个属性为null:
检查是否哪个配置出错,三个配置文件中的属性有交叉,很容易写的不一致,需要细心点。















 1833
1833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









