







 本文讲述了探探在面对海量图片、视频存储需求时,从调研到选择Minio作为对象存储解决方案的全过程。Minio因其简洁设计、高度兼容S3协议以及数据可靠性的特点,成为探探的最佳选择。文章详细介绍了Minio的架构、核心流程、部署扩容以及性能优化,包括如何通过合并小文件提升性能,以及在实际使用中遇到的挑战和解决方案。
本文讲述了探探在面对海量图片、视频存储需求时,从调研到选择Minio作为对象存储解决方案的全过程。Minio因其简洁设计、高度兼容S3协议以及数据可靠性的特点,成为探探的最佳选择。文章详细介绍了Minio的架构、核心流程、部署扩容以及性能优化,包括如何通过合并小文件提升性能,以及在实际使用中遇到的挑战和解决方案。
前言
在 2019年第五届 Gopher China 大会上,探探研发工程师于乐做了题为《基于 MINIO 的对象存储方案在探探的实践》的技术演讲。探探作为一个亿级用户千万日活的社交平台,每天会处理用户上传的大量图片、视频等媒体文件。最初将所有的对象存储在S3上,但随着存储容量越来越大,开始着手调研自己的存储系统。
经过一番比较,纯 Go 写的 Minio 最适合探探的业务场景。Minio 在设计上去繁就简,接口完全兼容 S3 协议。本次演讲会重点分享 Minio 在探探应用实践过程中积累的一些经验。以下为演讲实录。
No.0
自我介绍
大家好,我叫于乐,我是探探的工程师,很高兴今天在这里跟大家一起分享交流,今天来聊一下对象存储相关的话题。
接下来我以第一视角把探索整个对象存储的历程跟大家分享一下,希望对大家有所帮助。
No.1
探探 APP 的几个功能
1. 关于探探 APP
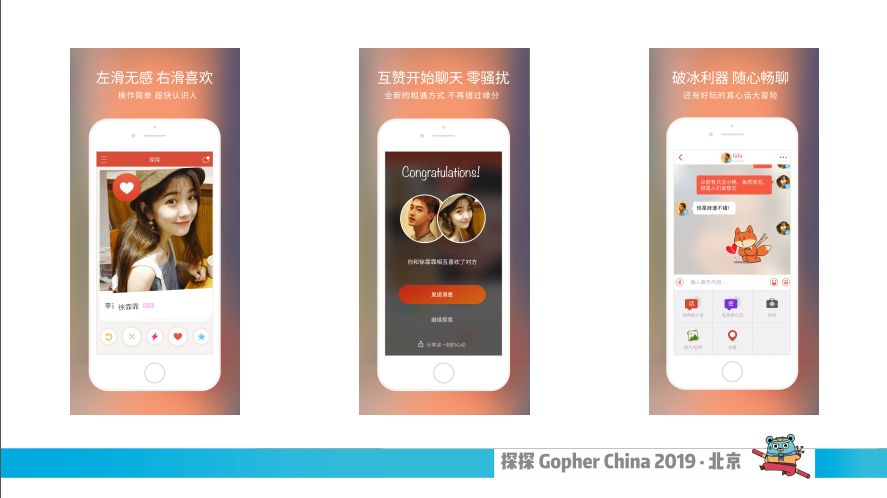
这是探探app的几个功能,它的基础功能非常简单左划右划,左划是不喜欢,右划是喜欢,当两个人相互喜欢就配对成功了,配对成功之后就开始相互聊天。你所看到的一些图片、视频还有在聊天中产生的语音,这些元素在对象存储的范畴里面,就是以对象保存下来。所以用户量的增长,探探所要存储的对象越来越多。
2. 存储的文件类型
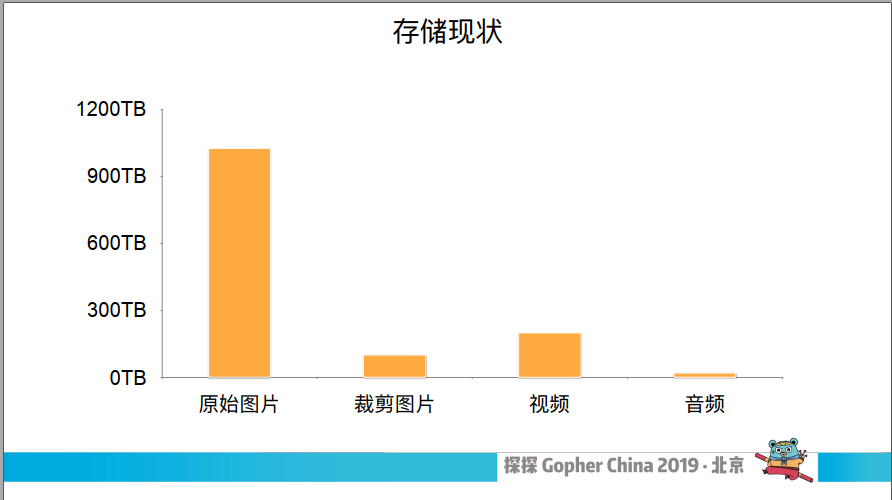
这是探探目前不同类型对象所占的空间,显而易见图片是存储的一个大头,目前超过了 1PB,它定期清理所以大小基本上保持了稳定的状态。我们目前写入的 QPS 大概是 1 千左右,读取是 5 千左右,压力不是很大。之后在做技术转型的时候,我们在满足基本性能的前提下,希望方案越简单越好。
3. 开源方案

于是,我们就开始调研当前的一些开源方案,这些存储方案里面可以分为两种:一种是可以自定对象名称的;另外一种是系统自动生成对象名称。我们的对象名是自己生成的,里面包含了业务逻辑。像 FS 就是国内大佬开源的一个分支存储,但是因为不能自定义文件名所以不合适,左划掉。还有像领英的 Ambry、MogileFS 其实都不能自定对象名的,所以是不合适的。左上角 LeoFS 对我们来说不是很可控,所以不合适。TFS 是淘宝开源的,但是目前已经很少有人维护它并且也不是很活跃,所以当时就没有考虑。ceph 是一个比较强大的分布式存储,但是它整个系统非常复杂需要大量的人力进行维护,对我们的产品不是很符合,所以暂时不考虑。
No.2
初识 MINIO
剩下的比较有意思,GlusterFS 为本身是一个非常成熟的对象存储的方案。2011年左右被收购了,他们原版人马又做了另外一个存储系统MINIO,仙鹤就是他们的 logo,MINIO 对我们来说它是可控的,并且他们的文档非常详细、具体,再加上他们之前在存储方面有十几年的经验,所以就这样打动了我们,果断把它右划。
1. MINIO 架构
从那儿之后我们更加深入的了解一下 MINIO。首先我们先宏观的介绍一下 MINIO 的框架。
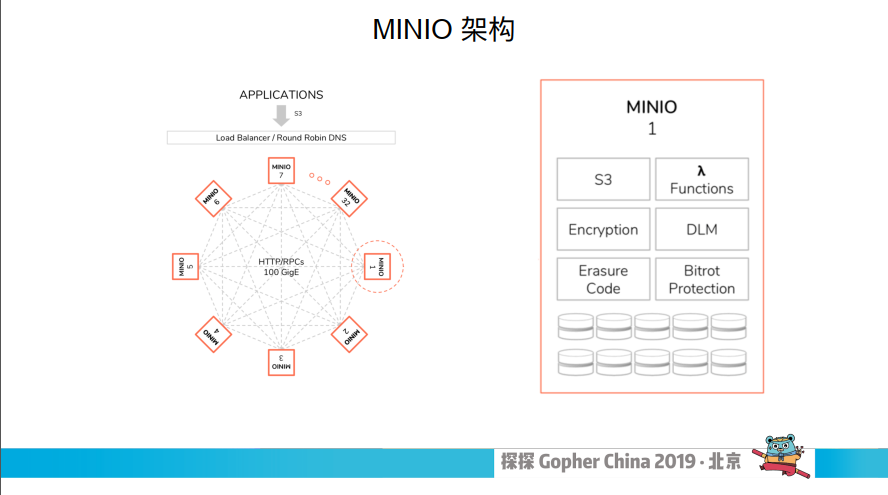
左边是 MINIO 集群的示意图,整个集群是由多个角色完全相同的节点所组成的。因为没有特殊的节点,所以任何节点宕机都不会影响整个集群节点之间的通信。通过 rest 跟 RPC 去通信的,主要是实现分布式的锁跟文件的一些操作。
右边这张图是单个节点的示意图,每个节点都单独对外提供兼容 S3 的服务。我们对 MINIO 有一个初步认识以后,再来看它的数据是怎么存储的。
2. MINIO 概念介绍

这块有几个概念比较重要,我们来看右边 MINIO 集群存储示意图,每一行是一个节点机器,这有 32 个节点,每个节点里有一个小方块我们称之 Drive,Drive 可以简单地理解为一个硬盘。一个节点有 32 个 Drive,相当于 32 块硬盘。Set 是另外一个概念,Set 是一组 Drive 的集合,所有红色标识的就组成了一个 Set,这两个概念是 MINIO 里面最重要的两个概念,一个对象最终是存储在 Set 上面的。
MINIO 是通过数据编码,将原来的数据编码成 N 份,N 就是一个 Set 上面 Drive 的数量,后面多次提到的 N 都是指这个意思。然后编码把数据写到对应的 Drive 上面,这就是把一个对象存储在整个 Set 上。一个集群包含多个 Set,每个对象最终存储在哪个 Set 上是根据对象的名称进行哈希,然后影射到唯一的 Set 上面,这个方式从理论上保证数据可以均匀的分布到所有的 Set 上。根据我们的观测,数据分布的也非常均匀,一个 Set 上包含多少个 Driv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









