









问题现象
ETCD作为我们管理面(基于Java)的异步任务同步媒介,在管理面压力测试时,发现任务状态不更新了。
问题定位流程
而业务线程日志正常(INFO级别),数据库没有死锁,并且top -c命令和sar命令等查看CPU,内存,硬盘IO都正常。
于是,利用jstack定时十秒打印线程方法调用栈,打印六次。
发现定时线程方法栈很奇怪:

发现这个线程池里面的所有线程都处于WAITING状态,并且调用栈一直在加深,和死循环似的,在EtcdResponsePromise.get()这个方法纠结(看上去是个异步get请求)。
将日志级别设为Debug级别,复现场景。
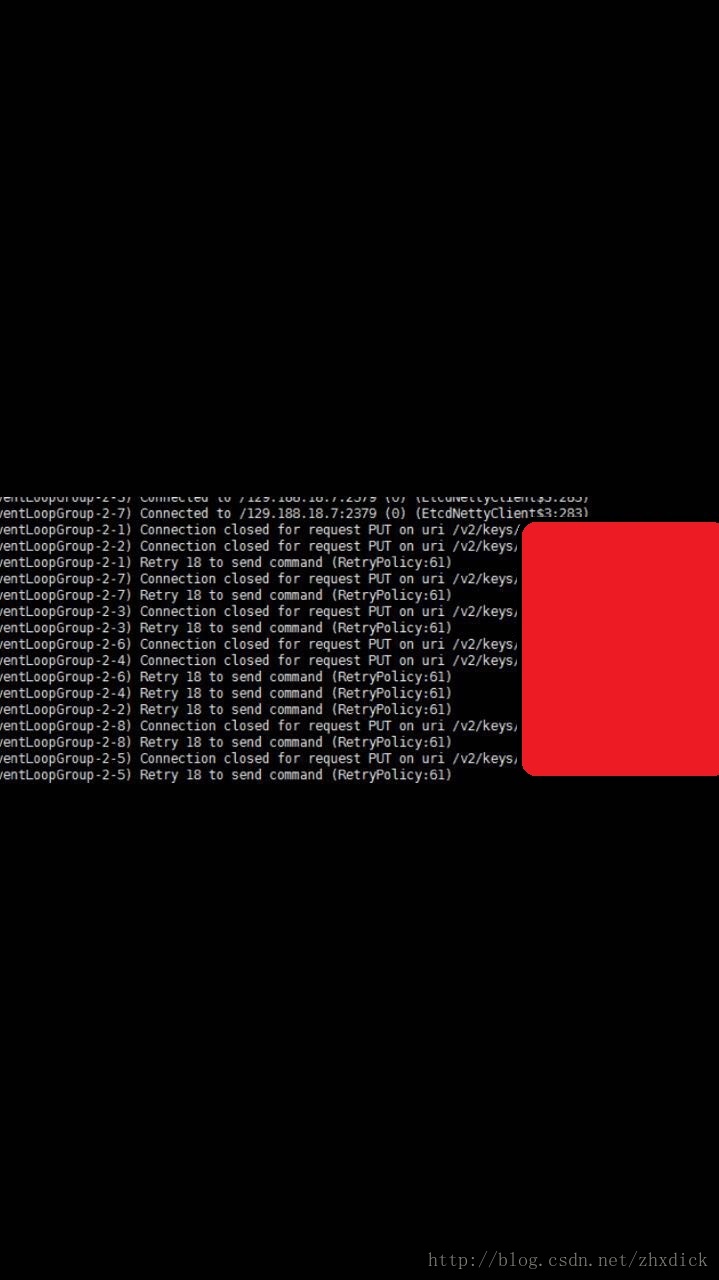
从日志中看出,这个通过 HTTP PUT到ETCD的请求一直失败,并且一直重试,查阅资料得知,我去,ETCD4J的默认配置是无限重试(参考资料: https://github.com/jurmous/etcd4j/issues/31)
那么,为何会PUT失败呢?
PUT会失败,推测三个原因:
- ETCD挂了
- 这个路径在PUT过程中被删掉了
- ETCD4J请求限制(ETCD4J基于Netty,Netty的Client默认有超时时间和请求大小限制),包括超时时间限制和大小限制
排除了1,2,我推测原因是3
查看ETCD4J官网:
https://github.com/jurmous/etcd4j#custom-parameters-on-etcdnettyclient

的确有限制(默认100K),再看我们的路径目前存储的数据大小推测我们的请求大小,嗯,的确快大于了100K
解决方案
- 调整ETCD4J配置,参考业界配置和我们的应用场景,配置超时时间为1S,大小为1MB,参考:https://coreos.com/etcd/docs/latest/dev-guide/limit.html
- 调整重试次数,不能无限重试,无限重试的结果就是一个错误导致线程池任务队列满了无法响应处理其他正常的状态业务,雪崩。而且这个重试最好不要立刻重试n次,而是以幂函数的时间间隔重试(1S后重试一次,2S后重试一次,4S后重试一次。。。),减轻组件错误带来的某一个压力尖峰时刻















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









