







每天一点数据库之-----Day 6 数据分组与数据分页
----转载请注明出处:coder-pig
本节引言:
本节继续来学习SQL中的数据查询中的数据分组~
先建个表,录几条数据,顺道复习下之前学的内容~
之前建立的T_Worker都用了几天了,今天就来弄个新的表吧T_Product商品表:
建表SQL:
CREATE TABLE T_Product
(
PId INTEGER,
PName VARCHAR(20),
PKind VARCHAR(20),
PCity VARCHAR(10),
PPrice NUMERIC(10,2),
FNum INTEGER,
PRIMARY KEY(PId)
)
往里面插入几条记录:
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(1,'德芙巧克力','糖果类','北京',33.80,100);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(2,'53度茅台飞天','酒水类','贵州',839.00,20);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(3,'伊利纯牛奶*24','牛奶类','内蒙古',72.00,50);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(4,'洁柔抽纸','日用品类','广州',17.90,100);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(5,'维达抽纸','日用品类','中山',13.90,100);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(6,'太阳卷纸','日用品类','中山',20.80,100);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(7,'费列罗巧克力','糖果类','意大利',89.00,100);
INSERT INTO T_Product (PId,PName,PKind,PCity,PPrice,FNum)VALUES(8,'金龙鱼玉米油1L','粮油副食类','广州',59.90,100);
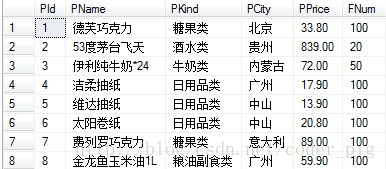
查询下表中的所有记录:
SELECT * FROM T_Product最后结果:
恩,那么素材就准备好了~
1.何为数据分组:
答:在前面我们已经学过COUNT这个聚合运算的函数了,要你查询表中某个年龄段,比如公司
18岁的员工有多少,直接SELECT COUNT(*) FROM T_Worker WHERE FAge = 18;
但是假如你想看每个年龄段的人数,这样的方法显得效率很低,这个时候就是数据分组大显神威
的时候了!
数据分组就是将表中的数据,按照个人需求,按表中的字段来进行分组,然后再对这些分组进行聚合
运算,就是前面讲的MIN,MAX,SUM,AVG,COUNT的计算~可以把这个分组看成一个临时的结果集,
而在SQL中,我们可以使用GROUP BY子句来完成数据的分组!
当然,也不是说绝对要和聚合函数一起使用,不过分组的目的也是为了进行聚合运算,下面比较下,直接取数据与
数据分组
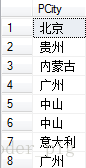
普通:
SELECT PCity FROM T_Product
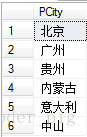
按产地分组:
SELECT PCity FROM T_Product GROUP BY PCity
看一看运行后的结果:
或许看到这里你有点眉目了,那么,把这个SQL语句写得复杂一点:
SELECT PCity,COUNT(PCity) AS '数量' FROM T_Product GROUP BY PCity
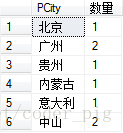
相信看到这里,你已经体会到了数据分组的便利了~
2.数据分组与聚合函数
①带WHERE的分组
比如:我们要查询表中"日用品"类所在城市的分组以及数目,只需要加上WHERE语句:
SELECT PCity,COUNT(PCity) AS '数量' FROM T_Product WHERE PKind = '日用品类' GROUP BY PCity 运行上述SQL:

如上述,很简单,只需假如WHERE子句,但是有一点要注意的是:
GROUP BY子句需要放在SELECT语句后,还要放在WHERE语句后,不然可是会报错的!
把上面的SQL语句将WHERE子句与GROUP BY子句交换,就会出现下述的错误!

②指定多个列
前面写的都是按照一个列来分组,当然你可以i可以指定多个列,实现"组种组"的效果,
按顺序,先按第一个分组列进行分组,接着到第二个...以此类推
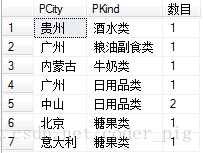
比如以下的SQL
SELECT PCity,PKind,COUNT(*) AS '数目' FROM T_Product GROUP BY PCity,PKind
运行上述SQL:
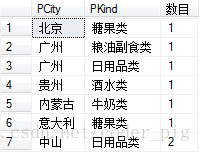
假如调转下PCity与PKind的位置
SELECT PCity,PKind,COUNT(*) AS '数目' FROM T_Product GROUP BY PKind,PCity
运行上述SQL:
另外,SELECT查询的字段,需要在聚合函数或者GROUP BY的子句中,比如上述SQL写成这样:
SELECT PCity,PKind,PPrice FROM T_Product GROUP BY PKind,PCity ORDER BY PPrice ASC是会报下述错误的:

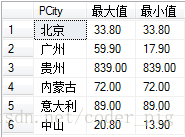
③实例:求出按产地分组,最大与最小值
SQL如下:
SELECT PCity,MAX(PPrice) AS '最大值',MIN(PPrice) AS '最小值'
FROM T_Product GROUP BY PCity
运行SQL:
3.HAVING语句:
从上面两点我们学会了将数据分组,接着下来再学习对分组进行过滤
使用到SQL中的HAVING语句!比如筛选记录数大于1的分组
直接使用WHERE COUNT(*) > 1是错误的,因为聚合函数不能在WHERE语句中使用!
而要使用HAVING语句:
SELECT PCity FROM T_Product GROUP BY PCity HAVING COUNT(*) > 1
运行上述的SQL语句:
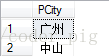
上述SQL的功能就是:先把表中数据按PCity来分组,然后筛选出记录条数大于1的部分!
另外,使用HAVING语句,要注意的:
1.HAVING子句需要放在GROUP BY子句之后!
2.HAVING子句不能包含未分组的列名,就是没写在GROUP BY后面的~
如果你还是需要包含它的话,这个时候你可以用WHERE!
4.数据库分页
相信大家都听过这个名词吧,因为我们再查询数据的时候,查询的结果很多的时候,我们
通常会将查询结果进行分页,比如,每页显示10条记录,用户可以点击"下一页","上一页"
等来查看不同的页,实现原理就是限制查询的结果集行数!鉴于不同DBMS实现数据分页
的原理不同,这里仅演示MYSQL限制结果集的示范,使用的是LIMIT关键字,而SQLITE也
支持这个关键字,所以,你懂的~,大体代码如下:
//定义两个变量:当前的页码与每页显示数据数目
int goIndex = 0;
int PageSize = 10;
//定义一个显示数据的方法
private void ShowData()
{
//按自己的需求显示数据
}
//计算表中总共有多少条数据
private int GetCount()
{
ResultSet rs = ExecuteSQL("SELECT COUNT(*) AS ITEMCOUNT FROM T_Product");
return rs.getInt("ITEMCOUNT");
}
//定义一个查询当前页中
private void DoSearch()
{
//计算查询页的起始行数
String beginIndex = (goIndex * PageSize).toString();
String size = PageSize.toString();
Result rs = ExecuteSQL("SELECT * FROM T_Product LIMIT" + startIndex + "," + size);
ShowData();
}
//按钮的事件处理
class MyClick implements OnClickListener
{
private void OnClick(View v)
{
switch(v.getId())
{
//点击首页
case R.id.btnFirst:
goIndex = 0;
DoSearch();
//点击尾页
case R.id.btnLast:
goIndex = GetCount()/PageSize;
DoSearch();
//下一页
case R.id.btnNext:
goIndex = goIndex + 1;
DoSearch();
//上一页
case R.id.btnFirst:
goIndex = goIndex - 1;
DoSearch();
}
}
}分页实现原理大体如上述代码,看自己需求进行改进啦~
5.抑制数据重复
比如我们要检索表中有哪些类别的商品,我们可以直接
SELECT PCity FROM T_Product 运行SQL:
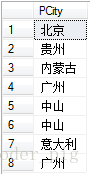
这时候发现结果有重复的,这个时候就可以使用SQL提供的
DISTINCT即可,用法也很简单,直接在SELECT后加上它就可以了!
SELECT DISTINCT PCity FROM T_Product 运行SQL语句:
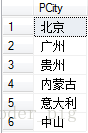
另外要注意一点:
DISTINCT是针对整个结果集来进行数据重复抑制的,而不是针对每一个列!!!
比如:
SELECT DISTINCT PKind,PCity FROM T_Product 运行SQL:
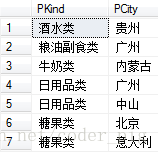














 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









