







我爬取了30页拉勾上安卓的招聘数据告诉你 安卓岗位究竟要一个什么样的人

我知道没图你们是不会看的



如图:以上是抓取了30页拉勾上关于招聘安卓相关的内容 然后根据词频 制作出词云图 出现最多的词是 开发经验
整体流程总共分为2步
1.爬虫爬取相关的招聘信息
2.根据获取到的招聘信息 生成词云图
这里的爬虫采用的是scrapy框架 编辑器使用的是PyCharm,本次不是针对零基础,如果对爬虫感兴趣推荐大家看这本 我就是看的这本书
链接:爬虫书籍的链接
先对拉勾网的数据进行分析 发现其中链接的规律:
变化的是2 也就是页数
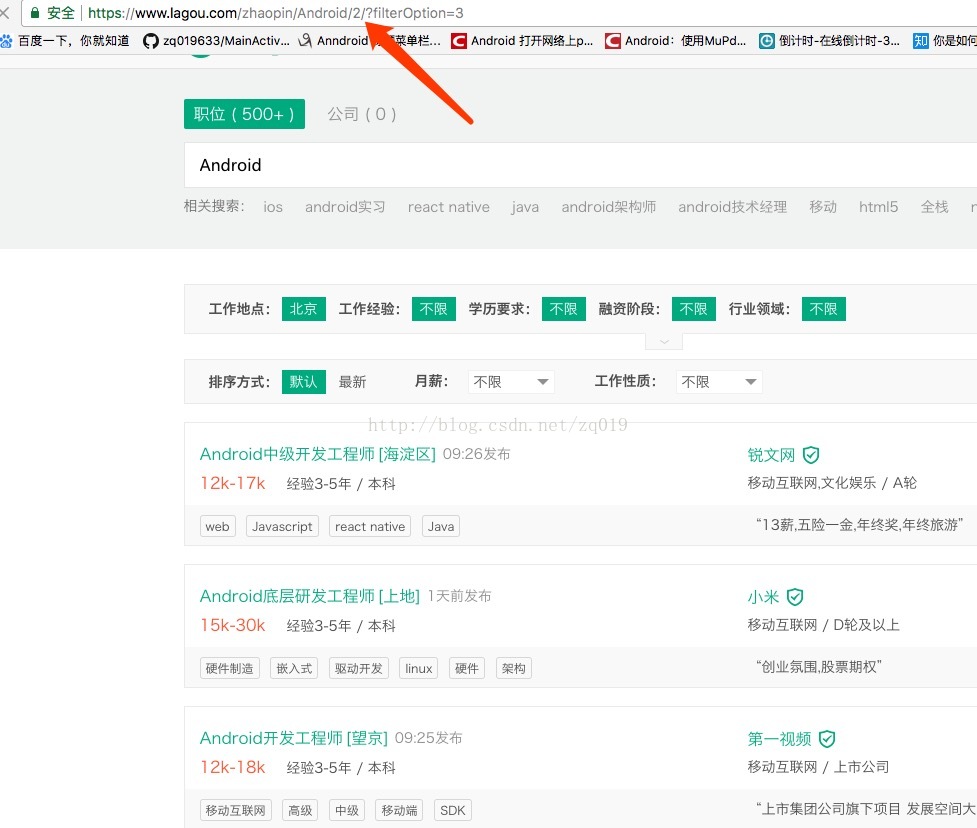
随便点进去一个条目 又发现了这样的规律
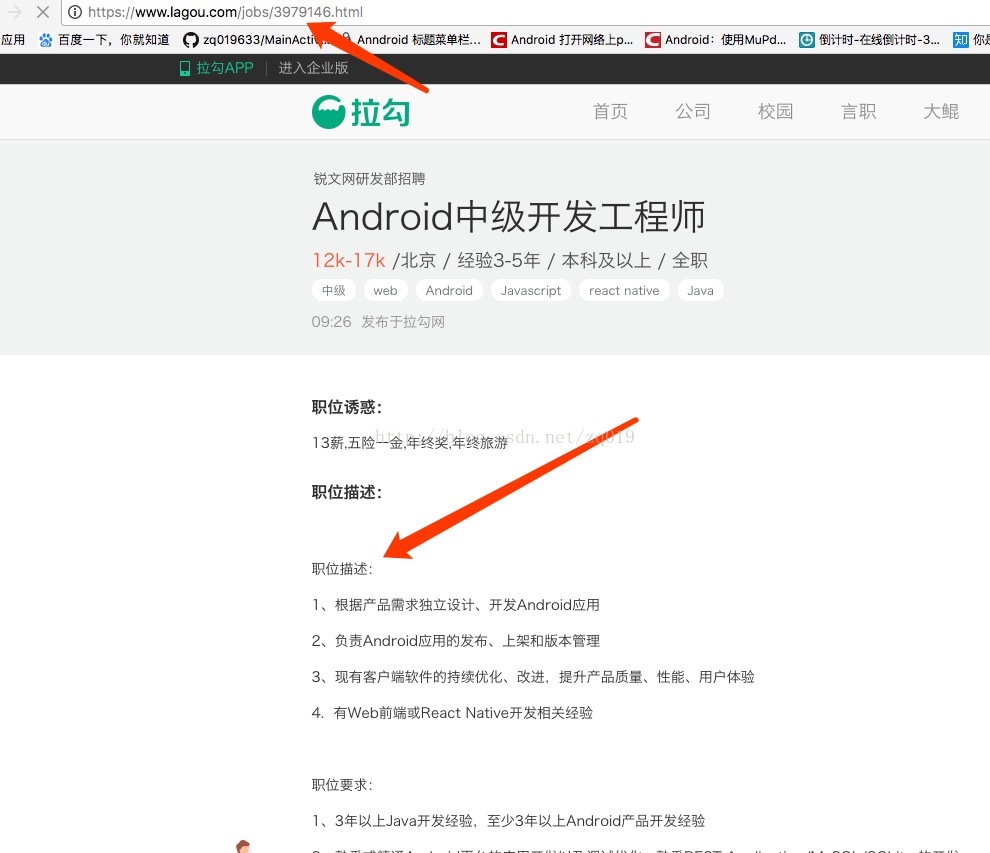
找到规律后 核心代码也就是2个正则表达式:
class LagouspiderSpider(scrapy.Spider):
name = 'lagouspider'
allowed_domains = ['www.lagou.com']
start_urls = ['http://www.lagou.com/']
def start_requests(self):
for i in range(2,30):
yield scrapy.Request(url='https://www.lagou.com/zhaopin/Android/'+str(i)+'/?filterOption=3')
def parse(self, response):
string = str(response.body)
# print string
pattern=r'https://www.lagou.com/jobs.\d*?.html'
result=re.findall(pattern=pattern,string=string)
for url in result:
print url
yield scrapy.Request(url=url,callback=self.parse_info)
def parse_info(self,response):
strZhiwei=response.css('.job_bt div').extract()[0]
strZhiwei=strZhiwei.encode('utf-8')
if os.path.exists('lagou.txt'):
f=open('lagou.txt','ab')
f.write(strZhiwei)
f.close()
else:
f=open('lagou.txt','wb')
f.write(strZhiwei)
f.close()
然后下载第三方词云的库 生成词云图的核心代码
# -*- coding: utf-8 -*-
from os import path
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
d = path.dirname(__file__)
# Read the whole text.
text = open(path.join(d, 'lagou.txt')).read().decode('utf-8')
# read the mask / color image taken from
# hp://jirkavinse.deviantart.com/art/quot-Real-Life-quot-Alice-282261010
alice_coloring = np.array(Image.open(path.join(d, "a.png")))
stopwords = set(STOPWORDS)
stopwords.add("said")
# wc = WordCloud(font_path=font,background_color="white", max_words=2000, mask=alice_coloring,
# stopwords=stopwords, max_font_size=40, random_state=42, )
# generate word cloud
wc = WordCloud(
background_color = 'white', # 设置背景颜色
mask = alice_coloring, # 设置背景图片
max_words = 7000, # 设置最大显示的字数
font_path = 'AdobeHeitiStd-Regular.otf',# 设置字体格式,如不设置显示不了中文
max_font_size = 95, # 设置字体最大值
random_state = 100, # 设置有多少种随机生成状态,即有多少种配色方案
)
def stop_words(texts):
words_list = []
words_list = jieba.cut(texts, cut_all=False) # 返回的是一个迭代器
return ' '.join(words_list) # 注意是空格
text = stop_words(text)
wc.generate(text)
# create coloring from image
image_colors = ImageColorGenerator(alice_coloring)
# show
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.figure()
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
plt.imshow(wc.recolor(color_func=image_colors), interpolation="bilinear")
plt.axis("off")
plt.figure()
plt.imshow(alice_coloring, cmap=plt.cm.gray, interpolation="bilinear")
plt.axis("off")
plt.show()
wc.to_file("zq——zjl.jpg")
当然 同样找规律 更改相关的链接可以爬取其他岗位 的招聘信息,或者重写正则表达式 获取其他自己需要的内容
注意:如果请求的次数过多 拉勾 会有反爬虫的相关措施,比如封禁ip
解决方案会在下次更新
代码下载链接















 1481
1481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









