




 本文介绍了如何使用WebMagic爬虫爬取拉勾网的职位信息。通过分析页面请求,利用Chrome和火狐抓包,理解Ajax请求的原理。详细讲解了设置Cookie、User-Agent、Referer等请求头的重要性,并展示了如何处理Content-Length。最后,通过发送POST请求实现分页爬取,获取1-30页的JSON数据。
本文介绍了如何使用WebMagic爬虫爬取拉勾网的职位信息。通过分析页面请求,利用Chrome和火狐抓包,理解Ajax请求的原理。详细讲解了设置Cookie、User-Agent、Referer等请求头的重要性,并展示了如何处理Content-Length。最后,通过发送POST请求实现分页爬取,获取1-30页的JSON数据。
我好久没来csdn写文章了,为什么呢?说句实话,其实不是自己不来写文章了,而是自己太关注形式化的东西了,有一段时间把文章写在github上面,感觉有自己的站点很特殊,很与众不同。其实用github来写文章确实是很不错的,使用mackdown标记语言给人一种高效编写的感觉。所以打算好好利用这两个平台,csdn的简洁性,可以让自己在使用windows系统时写一写技术文章同时很好地与他人进行评论交流。在使用linux系统时,可以利用终端的特性,使用git,写一写博客。行了,自己不在纠结了,就这么定了。编程练习固然重要,但是不总结也难以有收获。只希望把自己所遇、所悟、所感都记录成文字,这样一步一步积累,最终希望自己有一个质的蜕变。
————————————————————————————————————————————————————
下面介绍webmagic爬虫,爬取拉勾网的职位信息。
第一步:利用chrome和火狐检查链接
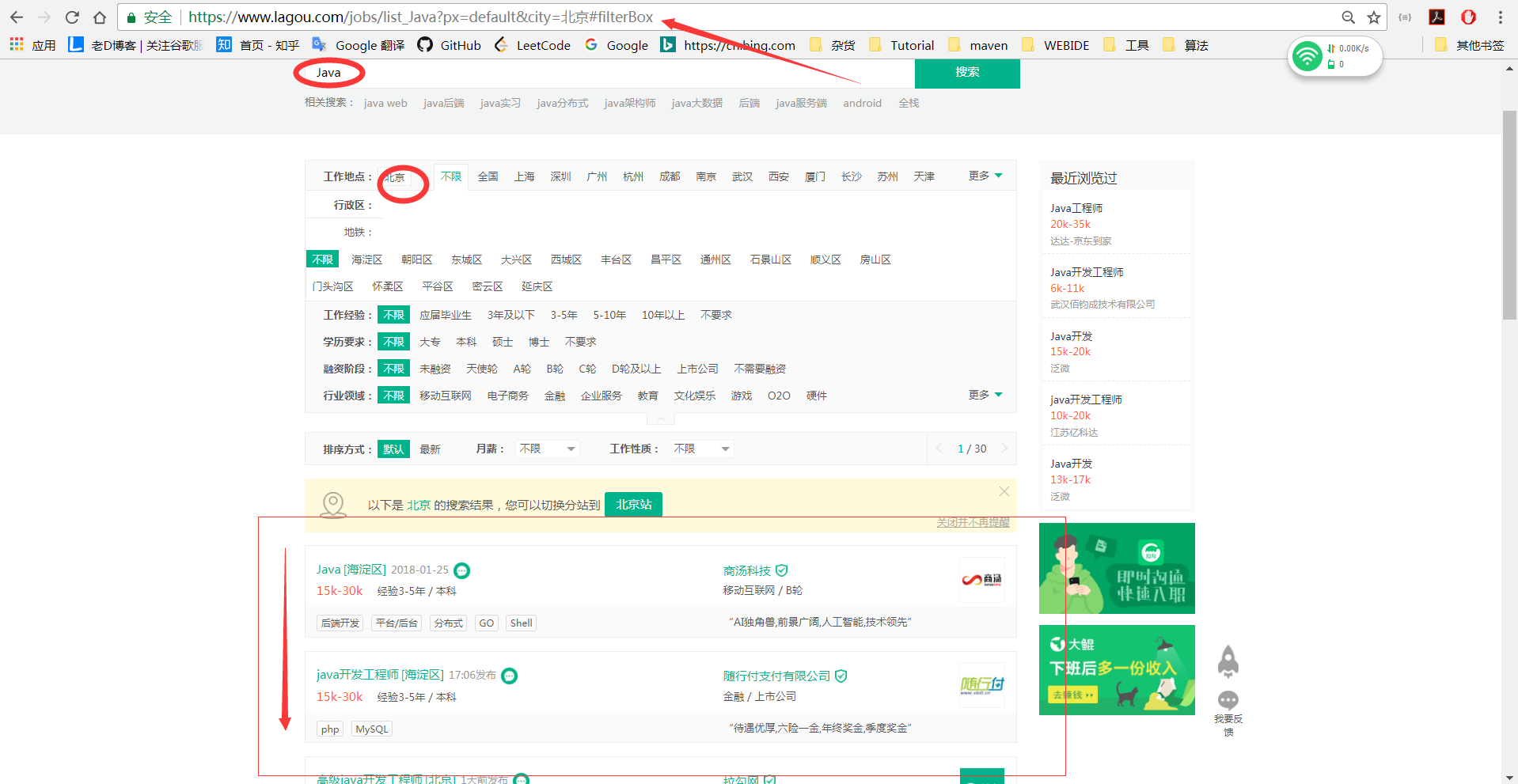
查看链接后,我们检查元素会发现这个链接不是我们需要的,因为类似于这种网站,数据的传输都是利用ajax的,所以进行第二步。
第二步:启用chrome调试,抓包分析
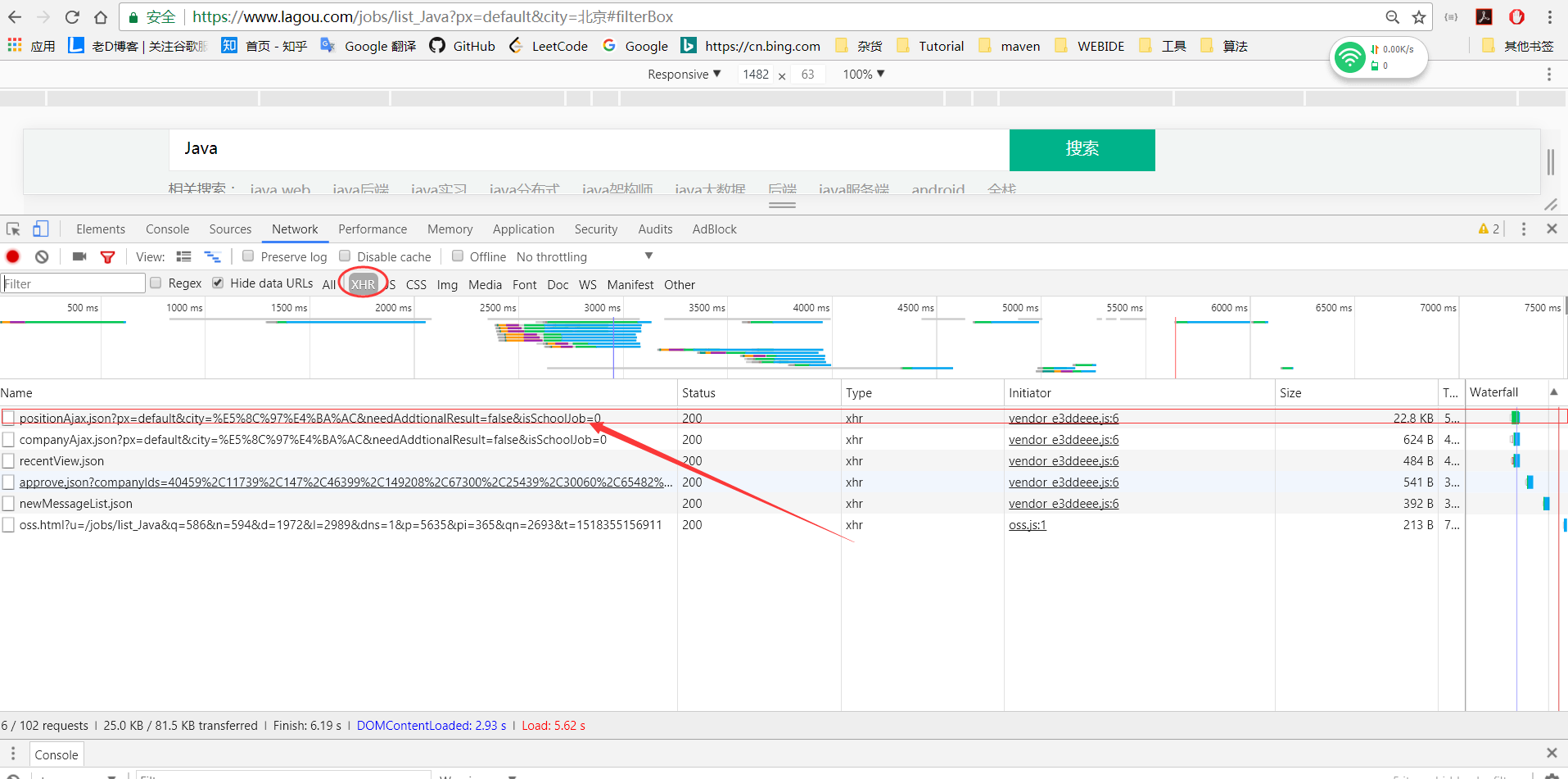
点击xhr(XmlHttpRequrest)F12后,可以看见以上ajax链接,从名字便可以看出来,第一个便是我们所需要的职位信息,点击链接查看详细信息。
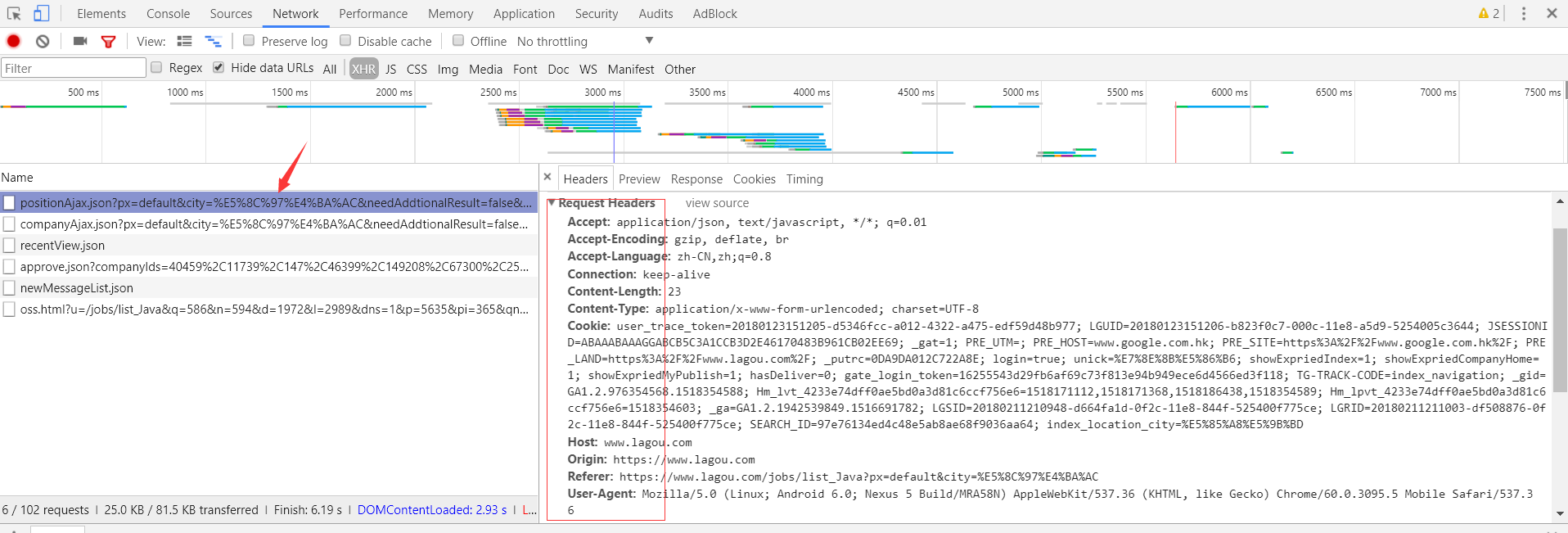
如上图所示,request-header信息全部显示在右侧,这个信息至关重要,因为这是你能够访问这个链接的重要认证。下面看一下此链接所传输的数据,点击Preview如下图所示:
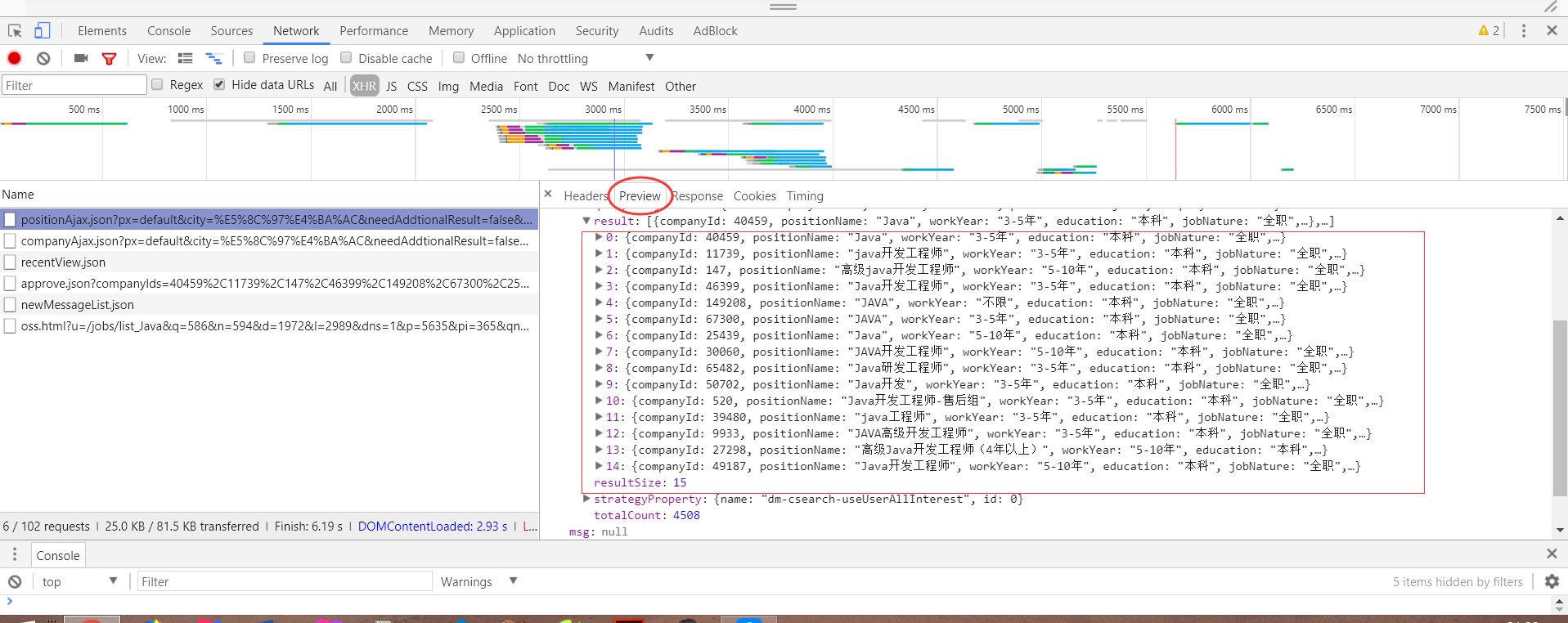
所有的职位信息都在这了,当然这也是固定页的职位信息,当页数不一样时,传递的职位信息不一样,这个需要考虑到post请求,后面会讲到。好,接下来,正式爬取。请看代码
private Site site = Site.me()
.setRetryTimes(3)
.setSleepTime(1000)
.addHeader("Accept","application/json, text/javascript, */*; q=0.01")
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5630
5630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









