







0x00 前言
数据截至:2016.02.23
你应该猜到是哪个网站了,用python3写了个多线程(异步也不错)+多代理爬虫,大致实现是在运行中不断往数据库加入新代理,在获取中把无效代理去掉及将任务ID添加回队列,最后剩下稳定的代理循环使用,也要限制一下每个代理的访问频率,这样可突破反爬虫机制,数据库用mysql(数据量小,感觉用什么没多大关系),抓取了招聘公司+招聘信息(含岗位需求),其实也就想看看一些信息汇总数据!
有效信息比
- 公司信息:71488/105958
- 招聘信息:813023/1445026
0x01 数据处理
按首页分类及工作年限分组统计最低平均、最高平均及两者平均
抓取分类
使用urllib.reuquest抓取后用BeautifulSoup解析
html = rullib.request.urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html, 'lxml')然后解析为树形结构数据,类似如下
技术
- 后端开发
- - Java
- - Python
- - PHP
- - .NET
- - C#
- - C++
······
- - Shell
- - 后端开发其它
- 移动开发
- - HTML5
- - Android
- - iOS
- - WP
- - 移动开发其它
- 前端开发
- - web前端
- - Flash
······这里取最后一层进行like匹配,匹配之前得处理以下顺序,比如C在C++前,匹配时C++就会归类到C里(like ‘%C%’),所以需将长度短的放后边,排序一下(上面有两个HTML5(前端开发和移动开发)及大小写区分没有处理,也可以试试按长度)
for i in range(len(menu)):
for j in range(len(menu)):
if menu[j] in menu[i]:
menu[i], menu[j] = menu[j], menu[i]分组统计
排完后用python循环拼接成SQL语句放数据库查询
CASE WHEN (`title` LIKE "%JavaScript%") THEN "JavaScript"
······
WHEN (`title` LIKE "%副总裁%") THEN "副总裁"
ELSE '其他'
END AS "title"工作经验类似,也用CASE处理以下,有些记录字段不规范,比如会出现1-3年、1-3 年这种情况
CASE WHEN (`seniority` LIKE "%应届毕业生%") THEN "应届毕业生"
WHEN (`seniority` LIKE "%1年以下%") THEN "1年以下"
WHEN (`seniority` LIKE "%1-3%") THEN "1-3年"
WHEN (`seniority` LIKE "%3-5%") THEN "3-5年"
WHEN (`seniority` LIKE "%5-10%") THEN "5-10年"
WHEN (`seniority` LIKE "%10年以上%") THEN "10年以上"
ELSE "经验不限"
END AS "seniority"然后按这两个进行分组平均统计薪资(ct字典是记录数量)
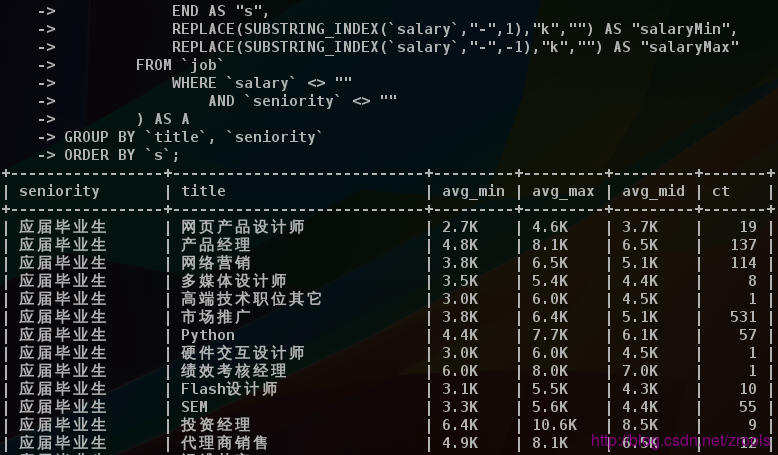
数据整合
最后把数据与前边的分类连接到一起,形成的json数据如下
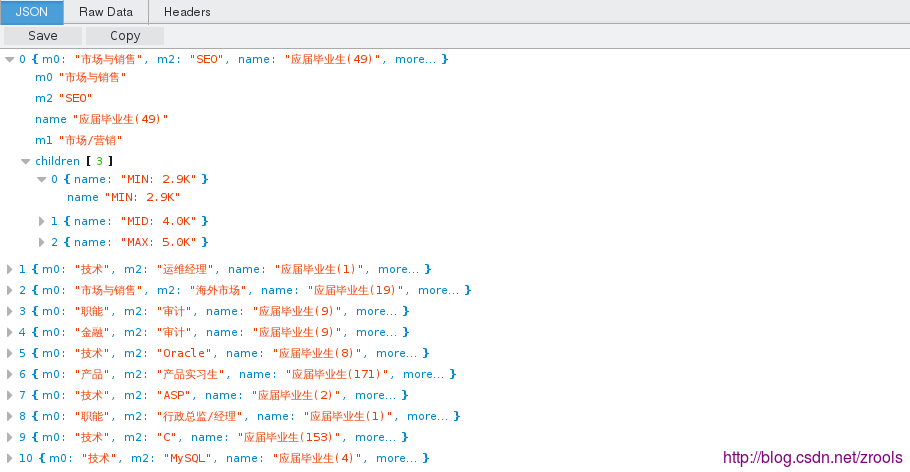
因为还不是树形结构,还需要使用d3js.nest()来处理(因为我嫌麻烦,就按一条一条记录封装扔前端处理)
0x02 数据可视化
d3js可视化除了能放大缩小之外,还有个好处是可以使用CTRL+F快速搜索定位
平均薪资
有了树形json,可以d3官方demo直接传入就可以了(数据有点量大,不然可以精确到城市整个大图),经验后的数量是统计的记录数

生成图像1280x96000尺寸刚合适,还可以玩玩其他姿势,比如打包图、圆形图等
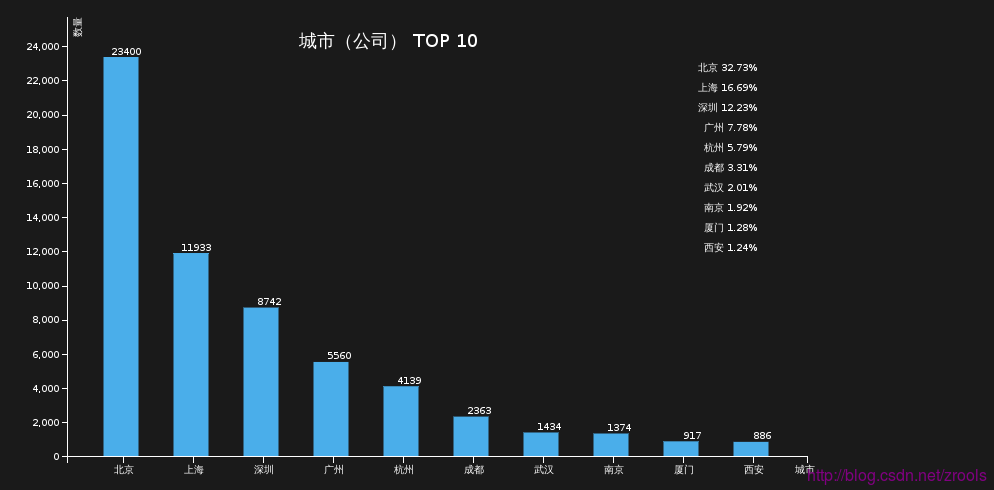
城市(公司)TOP 10
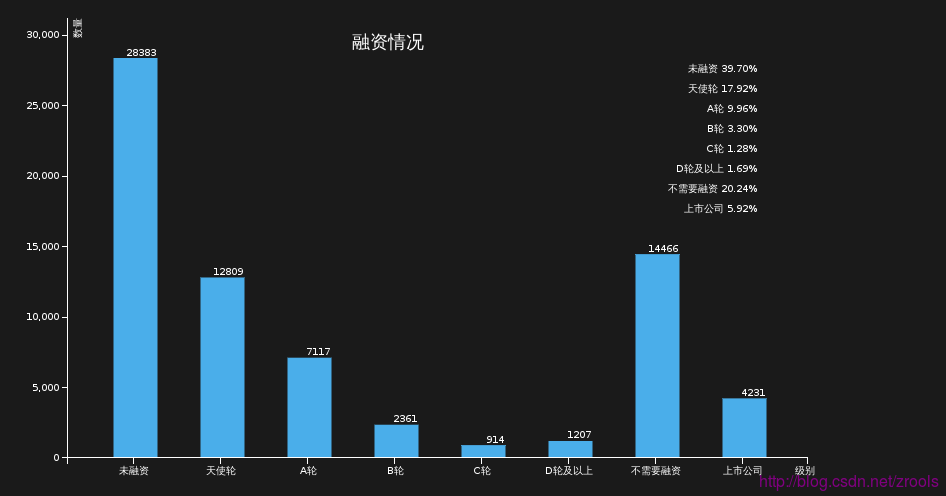
融资比例
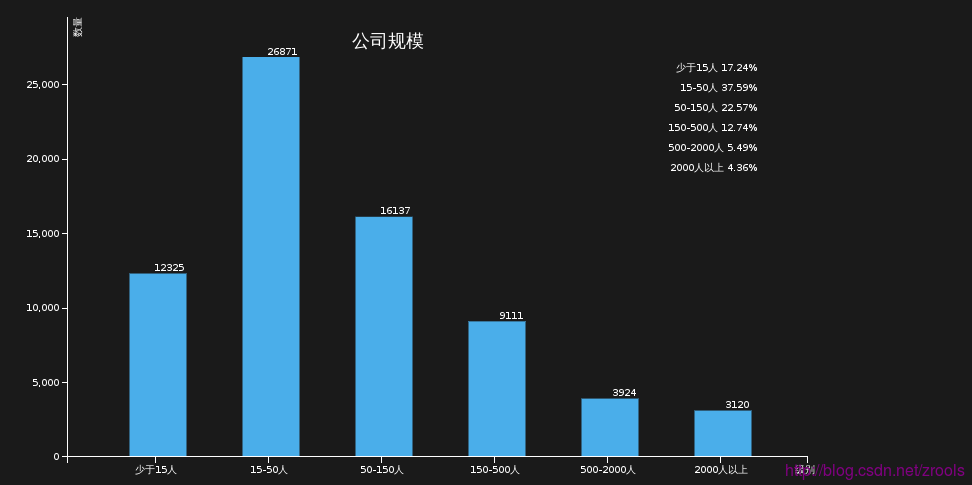
公司规模
其他
其他的还可以分析下走向、各职位关键字频率等。。。















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









