









今天心情不错,继续来填我的爬虫项目的坑,在这里我已经拿到了优酷动漫上的数据了,大约有3000条左右。正是数据量有点多,不可能人工用手填入数据库的,不然还不累死,而且还会出错,这样子做不靠谱是最笨的方法。所以这里面我第一个想到的就是直接使用sql语句插入,一条条的插入数据库。
我的数据具体是这个样子的:

//$v[0]===>动漫简介 //$v[1]===>动漫图片url //$v[2]===>动漫名称 //$v[3]===>动漫外链数组
(1)直接插入
所以具体的实现代码如下:
//方法1:直接插入
foreach($json as $k=>$v){
//$v[0]===>动漫简介
//$v[1]===>动漫图片url
//$v[2]===>动漫名称
//$v[3]===>动漫外链数组
//插入数据到list表
$sql="INSERT INTO `v_list` (`id`,`type`,`title`,`img_url`,`abstract`,`episode`)
VALUES ($k,0,'$v[2]','$v[1]','$v[0]',".sizeof($v[3]).")";
if($conn->query($sql)){
echo '插入数据成功!';
}else{
die('插入数据失败:'.$conn->error);
}
foreach($v[3] as $kk=>$vv){
//插入数据到vediolist
$sql="INSERT INTO `v_vediolist` (`belong`,`vedio_url`,`title`)VALUES($k,'$vv[1]','$vv[0]')";
if($conn->query($sql)){
echo '插入数据成功!';
}else{
die('插入数据失败:'.$conn->error);
}
}
}
这种方法真的是慢,花了70秒左右。
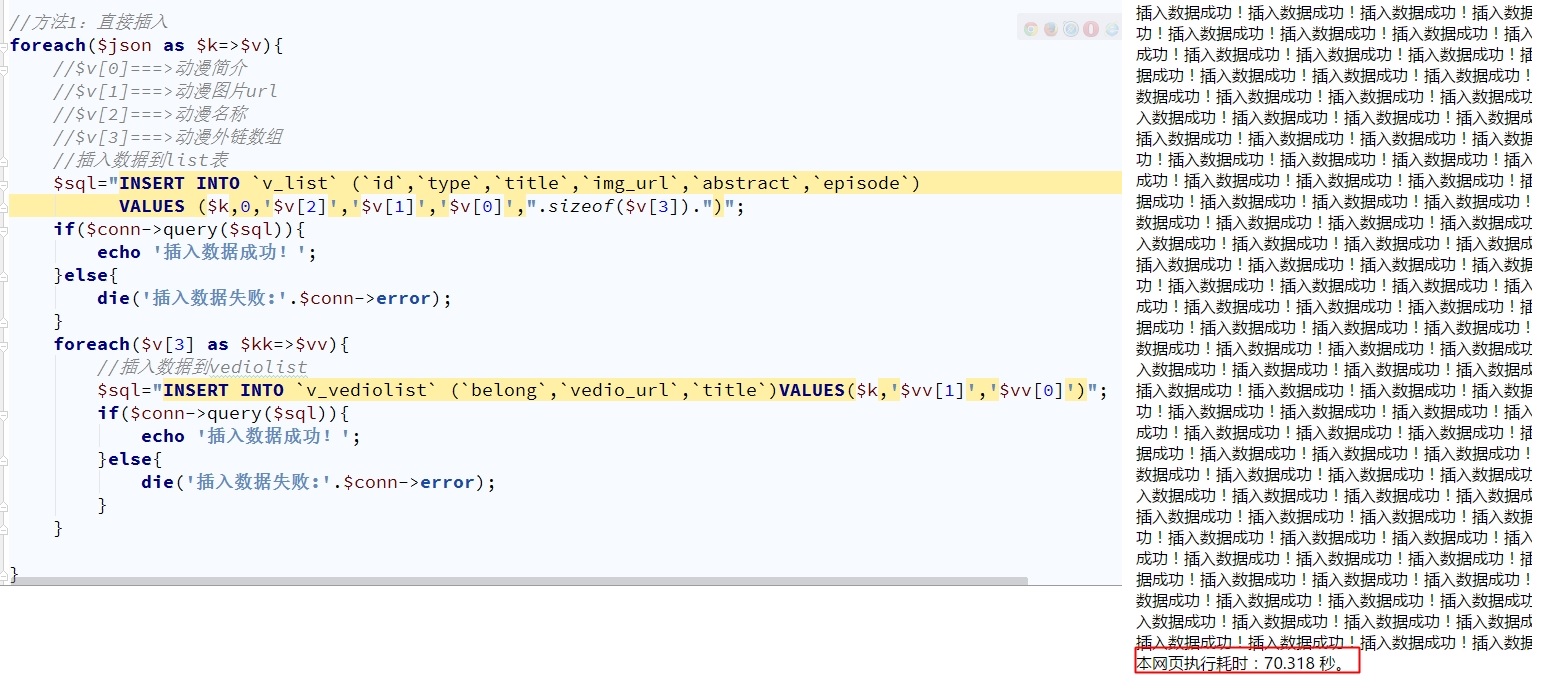
3000条数据就70秒,那数据多起来不就等几天几夜也没录完。所以开始找另外一种方法。
(2)MySQLi预处理
//方法2:MySQLi 预处理
$stmt1 = $conn->prepare("INSERT INTO `v_list` (`id`,`type`,`title`,`img_url`,`abstract`,`episode`)
VALUES (?,?,?,?,?,?)");
$stmt2 = $conn->prepare("INSERT INTO `v_vediolist` (`belong`,`vedio_url`,`title`)VALUES(?,?,?)");
foreach($json as $k=>$v){
//$v[0]===>动漫简介
//$v[1]===>动漫图片url
//$v[2]===>动漫名称
//$v[3]===>动漫外链数组
//插入数据到list表
$ref1["id"] = $k;
$ref1["type"] = 0;
$ref1["title"] = $v[2];
$ref1["img_url"] = $v[1];
$ref1["abstract"] = $v[0];
$ref1["episode"] = count($v[3]);
$stmt1->bind_param("ddsssd",$ref1["id"],$ref1["type"],$ref1["title"],$ref1["img_url"],$ref1["abstract"],$ref1["episode"]);
$stmt1->execute();
foreach($v[3] as $kk=>$vv){
//插入数据到vediolist
$stmt2->bind_param("dss",$k,$vv[1],$vv[0]);
$stmt2->execute();
}
}结果如下图:
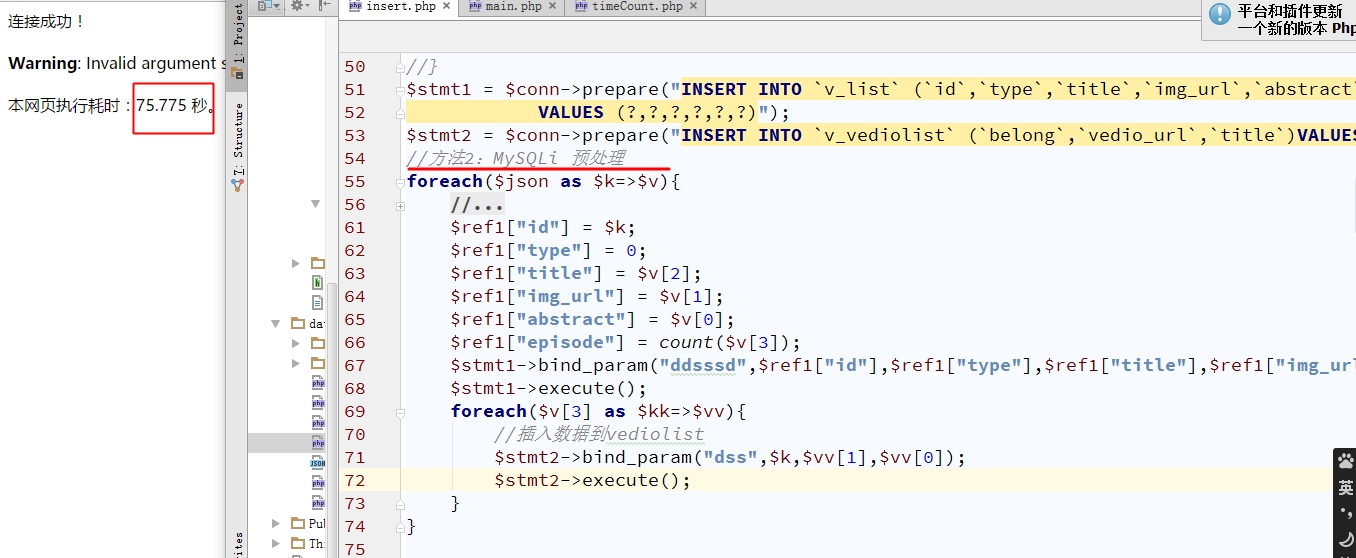
所以没有办法,又要找一种方法才行。之后这次的效果非常好。
(3)逗号拼接法
//方法3:逗号隔开
//INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....),(值1, 值2,....),(值1, 值2,....)
$sql1="INSERT INTO `v_list` (`id`,`type`,`title`,`img_url`,`abstract`,`episode`)VALUES";
$sql2="INSERT INTO `v_vediolist` (`belong`,`vedio_url`,`title`)VALUES";
foreach($json as $k=>$v){
//$v[0]===>动漫简介
//$v[1]===>动漫图片url
//$v[2]===>动漫名称
//$v[3]===>动漫外链数组
//插入数据到list表
$sql1.="($k,0,'$v[2]','$v[1]','$v[0]',".sizeof($v[3])."),";
foreach(@$v[3] as $kk=>$vv){
$sql2.="($k,'$vv[1]','$vv[0]'),";
}
}
//从字符串右侧移除字符
$sql1 = rtrim($sql1,',');
$sql2 = rtrim($sql2,',');
if($conn->query($sql1)){
echo '插入数据成功!';
}else{
die('插入数据失败:'.$conn->error);
}
if($conn->query($sql2)){
echo '插入数据成功!';
}else{
die('插入数据失败:'.$conn->error);
}使用这个方法后,速度快到不要不要的,简直是指数级的优化呀。
结果如下图:
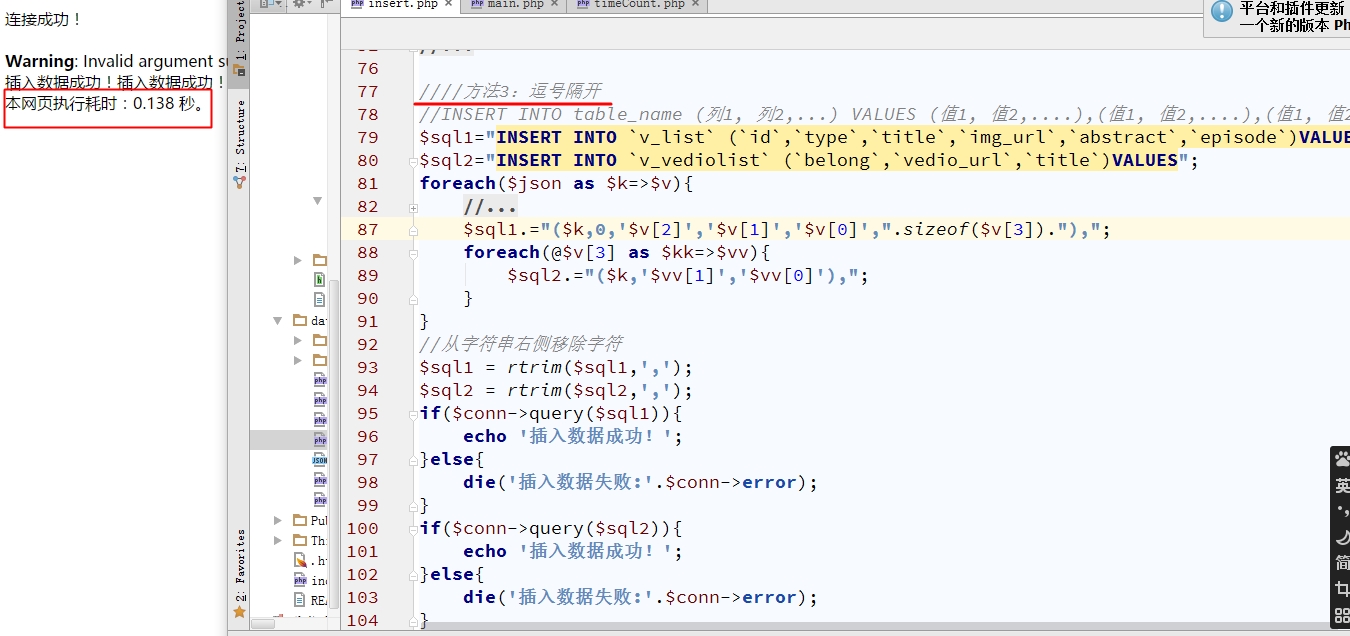
这种方法只要0.1秒左右就全部数据都导入了,速度真的是太快了。虽然好办法已经找到了,但是做技术要不断的探索才能不断进步,所以我又使用了事务的方法来导入数据。
(4)事务
方法4:事务
//关闭自动提交
$conn->autocommit(false);
foreach($json as $k=>$v){
//$v[0]===>动漫简介
//$v[1]===>动漫图片url
//$v[2]===>动漫名称
//$v[3]===>动漫外链数组
//插入数据到list表
$sql1="INSERT INTO `v_list` (`id`,`type`,`title`,`img_url`,`abstract`,`episode`)
VALUES ($k,0,'$v[2]','$v[1]','$v[0]',".sizeof($v[3]).")";
$conn->query($sql1);
foreach($v[3] as $kk=>$vv){
//插入数据到vediolist
$sql2="INSERT INTO `v_vediolist` (`belong`,`vedio_url`,`title`)VALUES($k,'$vv[1]','$vv[0]')";
$conn->query($sql2);
}
}
//上面的操作无错时执行事务提交
if(!$conn->errno){
$conn->commit();
echo 'ok';
}else{//错误的话回滚
echo 'err';
$conn->rollback();
}
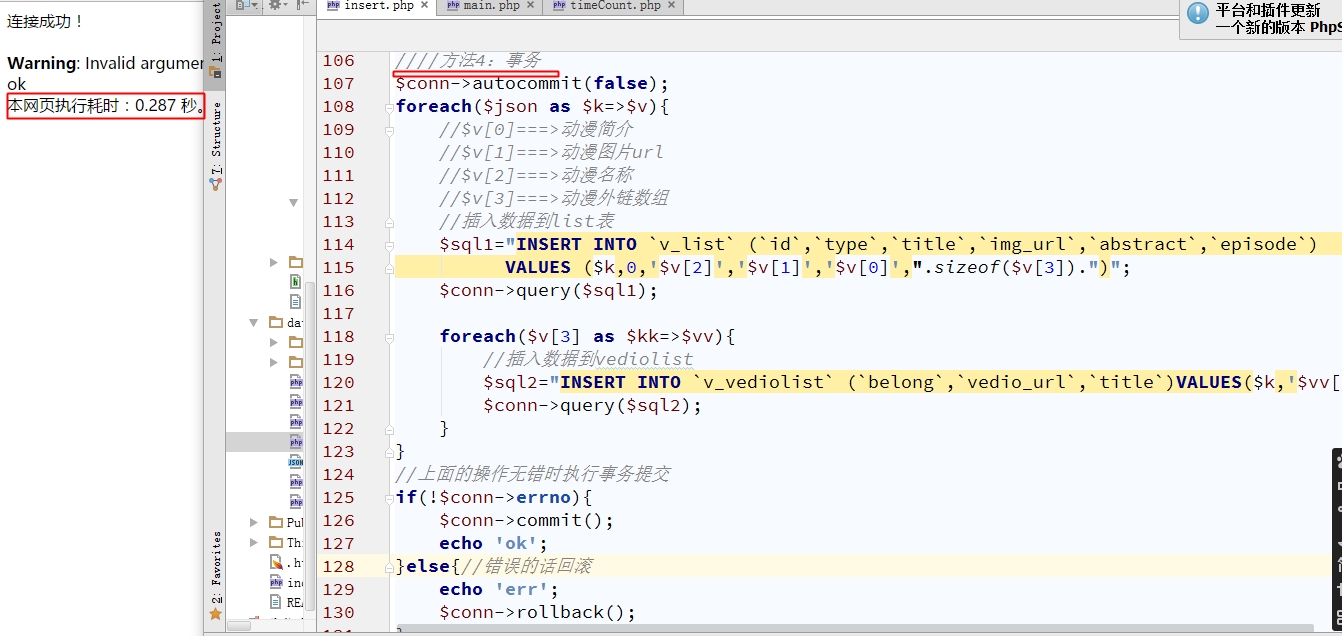
这种方法是第3种的两倍左右,但是这个方法有个好处是可以回滚,只要有一个地方出错了,就全部都放弃不要,回到刚开始要进行插入数据时的状态。
总结:
这四种的方式第1,2是最慢的不可取,所以第3,4这两种可以自己衡量一下,数据允许出点小错误的话,那第3是一个非常好的选择,不然就第4种吧。
最后,我的视频网站上的动画栏目的数据也能运行了,效果如下:
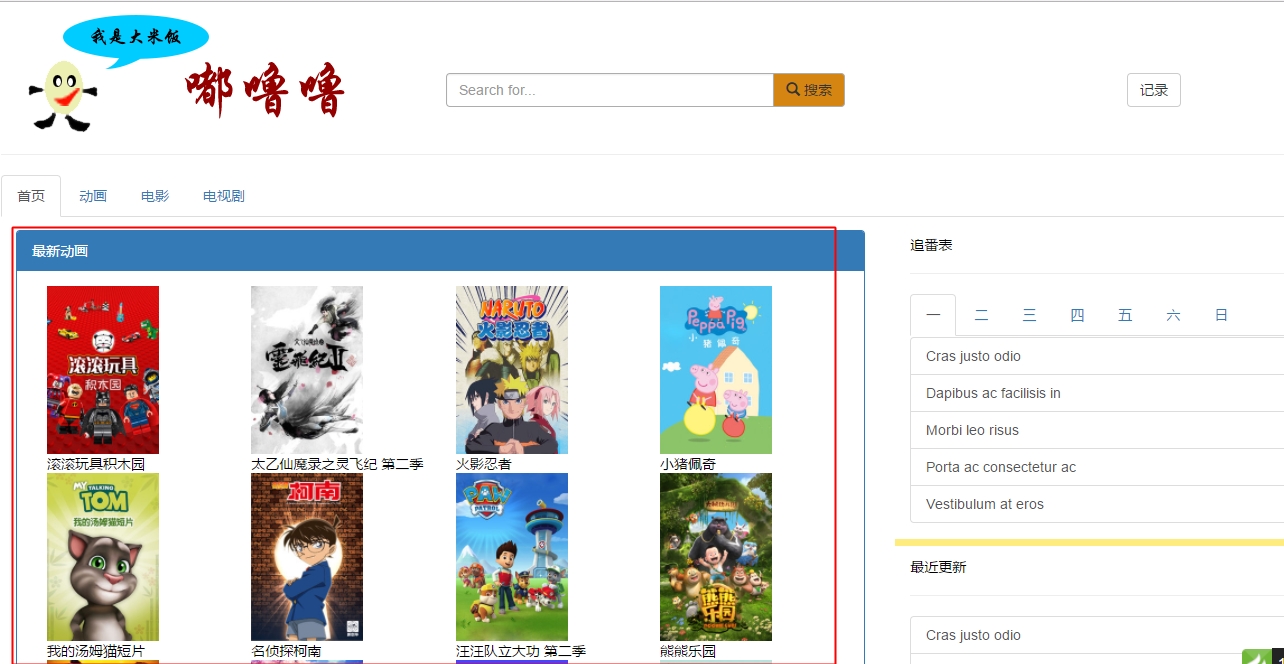
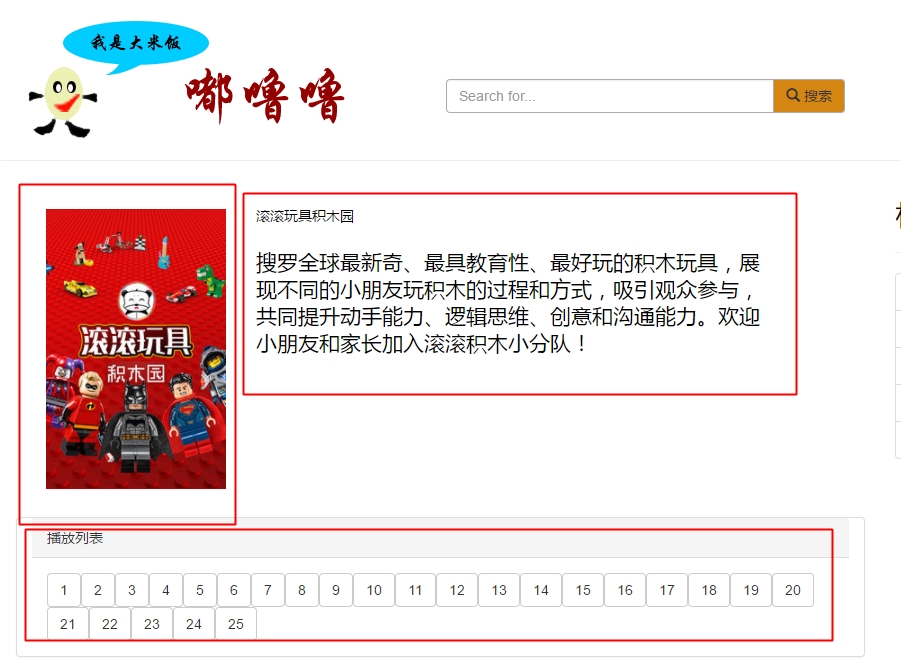
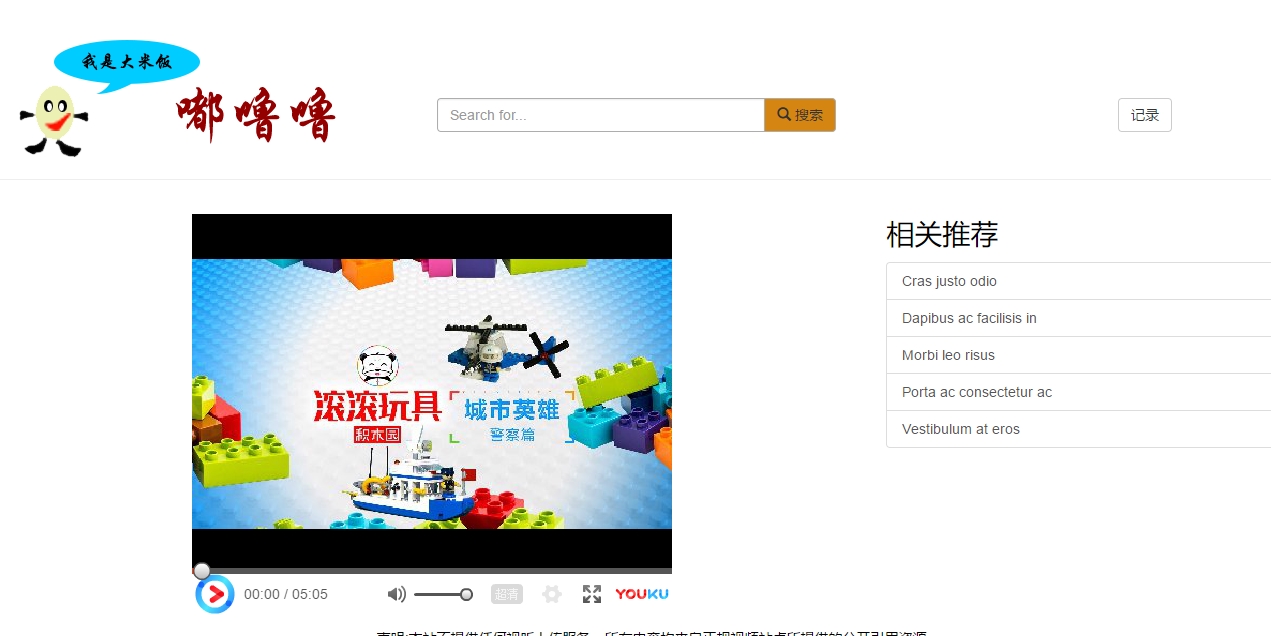














 9556
9556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









