







 本文介绍了Hadoop的YARN框架,包括其基本概念、架构解析,详细讲解了ResourceManager、ApplicationMaster、NodeManager和Container的角色。还提供了HDFS的安装配置步骤,特别是JobHistory服务的启动方法,用于查看任务运行详情。最后,文章涵盖了关闭Hadoop集群的操作。
本文介绍了Hadoop的YARN框架,包括其基本概念、架构解析,详细讲解了ResourceManager、ApplicationMaster、NodeManager和Container的角色。还提供了HDFS的安装配置步骤,特别是JobHistory服务的启动方法,用于查看任务运行详情。最后,文章涵盖了关闭Hadoop集群的操作。
一 背景介绍
自从Hadoop推出以来,在大数据计算上得到广泛使用。其他
分布式计算框架也出现,比如spark等。随着Hadoop的使用和研究越来越透彻,它暴漏出来的问题也越来越明显。比如NameNode的单点故障,任务调度器JobTracker的单点故障和性能瓶颈。各个公司对这几个问题都做出了对源代码的改变,比如阿里对NameNode做出修改使Hadoop的集群可以
跨机房,而腾讯也做出了改变让Hadoop可以
管理更多的节点。
相对于各个企业对Hadoop做出改变以适应应用需求,Apache基金也对Hadoop做出了升级,从Hadoop 0.2.2.0推出了Hadoop二代,即YARN。YARN对原有的Hadoop做出了多个地方的升级,对资源的管理与对任务的调度更加精准。下面就对YARN从集群本身到集群的安装做一个详细的介绍。
二 YARN介绍
在介绍YARN之前,Hadoop内容请查看相关附注中的连接。
2.1 框架基本介绍
相对于第一代Hadoop,YARN的升级主要体现在两个方面,一个是代码的重构上,另外一个是功能上。通过代码的重构不在像当初一代Hadoop中一个类的源码几千行,使源代码的阅读与维护都不在让人望而却步。除了代码上的重构之外,最主要的就是功能上的升级。
功能上的升级主要解决的一代Hadoop中的如下几个问题:
1:JobTracker的升级。这个其中有两个方面,一个是代码的庞大,导致难以维护和阅读;另外一个是功能的庞大,导致的单点故障和消耗问题。这也是YARN对原有Hadoop改善最大的一个方面。
2:资源的调度粗粒度。在第一代Hadoop中,资源调度是对map和reduce以slot为单位,而且map中的slot与reduce的slot不能相互更换使用。即就算执行map任务没有多余的slot,但是reduce有很多空余slot也不能分配给map任务使用。
3:对计算节点中的任务管理粒度太大。
针对上述相应问题,YARN对Hadoop做了细致的升级。YARN已经不再是一个单纯的计算平台,而是一个资源的监管平台。在YARN框架之上可以使用MapReduce计算框架,也可以使用其他的计算或者数据处理,通过YARN框架对计算资源管理。升级后的YARN框架与原有的Hadoop框架之间的区别可以用下图解释:
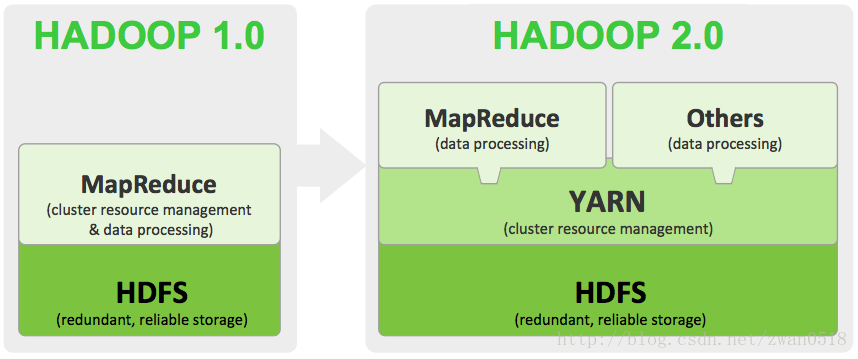
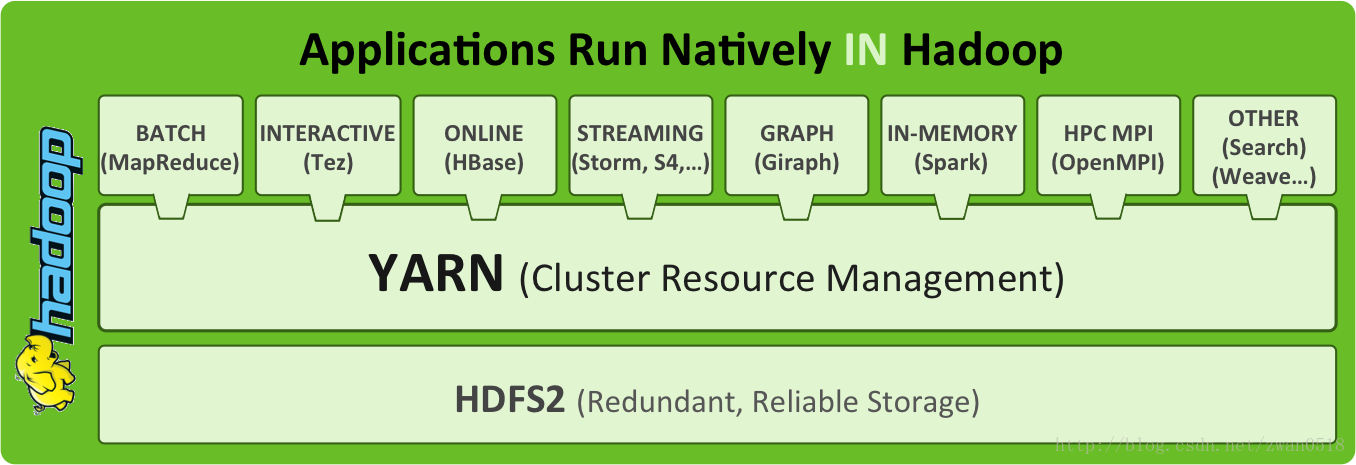
细节内容待补充。
2.2 框架架构解读
相对于一代Hadoop中计算框架的JobTracker与TaskTracker两个主要通信模块,YARN的模块变的更加丰富。在一代Hadoop中JobTracker负责资源调度与任务分配,而在YARN中则把这两个功能拆分由两个不同组件完成,这不仅减少了单个类的代码量(单个类不到1000行),也让每个类的功能更加专一。原有的JobTracker分为了如今的ResourceManager与
ApplicationMaster 两个功能组件,一个负责任务的管理一个负责任务的管理。有人会问那任务的调度与计算节点的谁来负责。任务的调度有可插拔的调
度器ResourceScheduler,计算节点有NodeManager来完成。这在下面会细说。
YARN的架构设计如下图所示:
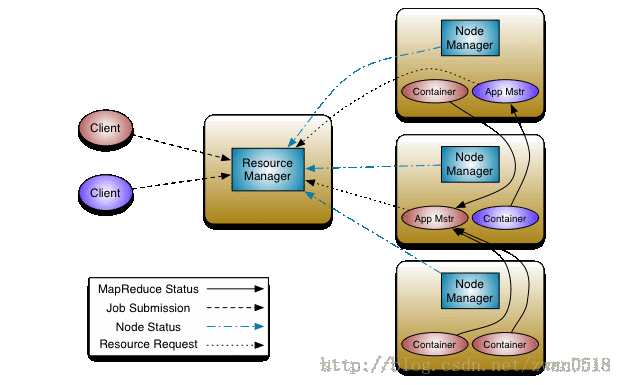
相对于第一代Hadoop,YARN把Hadoop中的资源控制、任务调度和具体任务计算的JobTracker/TaskTracker架构,变为下述的四个功能组件,让资源调度和任务调度更加细粒化。
- 集群唯一的ResourceManager
- 每个任务对应的ApplicationMaster
- 每个机器节点上的NodeManager
- 运行在每个NodeManager上针对某个任务的Container
通过上述四个功能组件的合作,解决了第一代Hadoop中JobTracker负责所有资源的调度和任务的调度的重任。除此之外还解决了,资源分配简单粗暴的问题。
2.3 功能组件细讲
ResourceManager
ResourceManager是这一代Hadoop升级中最主要的一个功能组件。
NodeManager
ResourceScheduler
三 安装
相对于Hadoop的安装,YARN的安装稍微繁琐一点,因为它的组件更
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4736
4736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









