







在介绍海量文件存储之前,需要先介绍一下常见的系统里面文件是如何存储的
文件inode
在linux下,每个文件或者目录,都会分配一个inode(index node),它不存储具体的文件内容,而是记录该文件的基础信息。每个inode大小一半是100-200kb(画重点,下面会用)。inode下会记录:
- 文件大小、类型;
- 权限信息,比如所属组,用户,访问控制;
- 文件的操作时间;
- 具体数据在磁盘的位置;
文件系统初始化的时候,磁盘空间一般都会分俩部分。一部分就是存储inode,一部分是真正的存储文件内容。需要注意的系统的inode数量是有上限的,即系统最多可以存储多少个文件。有可能磁盘空间还有很多,但inode已经被用完;那此时系统无法再分配新的inode,你也依旧无法再存储新的文件。查看文件占用多少inode,和系统还有多少inode可以用如下俩个命令:
#某一文件inode占用
[root@why /]# stat my_file
File: my_file
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
Device: xx Inode: 17 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-03-26 11:30:27
Modify: 2024-03-26 11:30:27
Change: 2024-03-26 11:30:27
#系统inode使用个数情况,注意是个数。
[root@why /]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
tmpfs 203330 100 203230 1% /dev/shm
tmpfs 203330 100 203230 1% /run
tmpfs 203330 200 203130 1% /sys/fs/cgroup
#当使用率100%,那系统则无法再新曾文件。
#
海量文件存储
海量文件的元数据管理
海量文件存储就是数亿数十亿上百亿的文件存储,在如今互联网上,海量文件基本是个常态。图片、视频、商品等,很容易达到这个量级。在这个量级下,当前单机系统存储,是肯定存不下的。比如一个100亿的文件,先不考虑inode数量,光inode的存储大概就得1个TB,再加上具体的文件内容,很容易就超出单机系统了。这是海量文件要解的第一个问题,就是海量文件的元数据管理。
海量文件下如何高速支撑文件读取
假如存储支撑了这么多的元数据,比如单独搞到机器存储元数据,1TB其实压力还是可以的;或者多找几台机器分布式存储机器。此时会引入第二个问题,海量的文件下如何快速访问文件。对于一次文件读取是要先加载inode,找到真实文件存储位置再去读具体文件。一般系统为了加速文件访问,会把inode缓存在系统里(vfscache:https://www.science.unitn.it/~fiorella/guidelinux/tlk/node110.html)。如果这么大量的inode,很难缓存住的,海量文件下如何高速支撑文件读取。
ceph存储系统
对于海量文件业务场景,当前行业一般都会采用对象存储组件。比如腾讯云的cos,其他云厂商的对象存储,还有开源的ceph。
对于ceph来说,常见的块存储,文件存储和对象存储三种业务场景,都可以很好的支持。
整体架构
直接搬运自官方
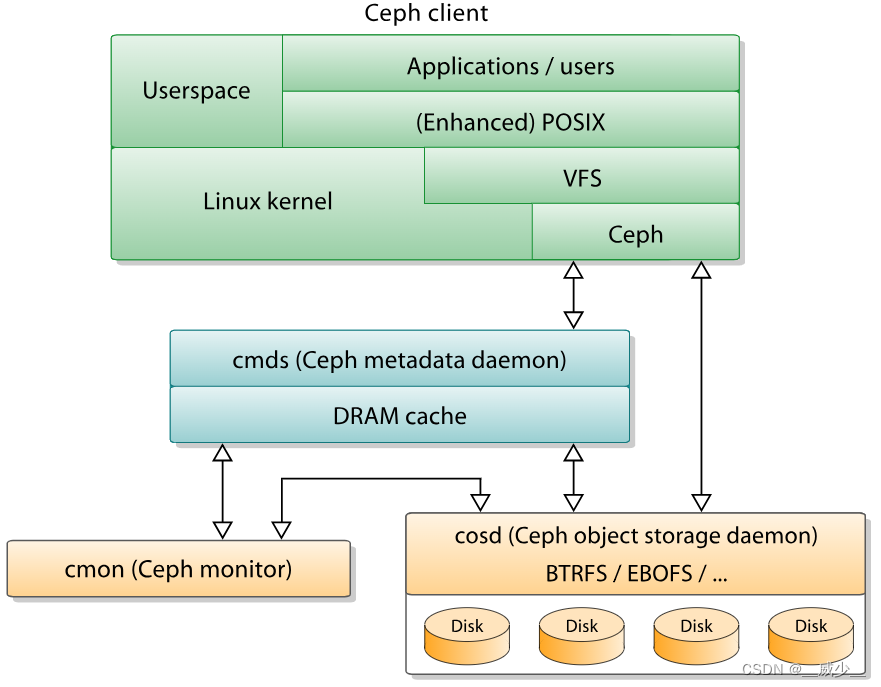
- 客户端:ceph自己的客户端。
- 监视器:Ceph监视器(Ceph-mon)维护集群状态的映射,包括监视器自身,下边提到的管理器、OSD、MDS和CRUSH。为了容灾设计,通常至少需要三个监视器。
- 管理器:Ceph Manager守护进程(Ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率、当前性能指标和系统负载。
- Ceph OSD:对象存储守护程序(Ceph OSD,cosd)存储数据,处理数据复制、恢复、再平衡,并通过检查其他Ceph OSD守护程序的心跳来向Ceph监视器和管理器提供一些监控信息。通常至少需要三个Ceph OSD来实现高可用。
- MDSs:Ceph元数据服务器(MDS,Ceph-MDS)存储Ceph文件系统的元数据。Ceph元数据服务器允许CephFS用户运行基本命令(如ls、find等),而不会给Ceph存储集群带来负担。
对于客户端和监视器来说,俩者都需要知道整个集群状态。对于ceph来说,他为了避免单点瓶颈,取消了集中式的某个组件来管理集群。
高可用
ceph容灾和管理都是以pg(Placement Group)为单位。一个对象存储隶属于一个pg,一个pg在一个osd或者多个osd。以pg为管理单位,相比管理海量的存储对象,复杂性要小很多。在介绍pg之前,就不得不先说下pool。
先介绍一下pool,可以认为是ceph集群对于存储空间的一个逻辑管理单元。对于用户来说,可以按照业务场景,定义N多个pool,定义原则可以按照业务自己应用特点。比如你可以建立一个pool面向对象的存储,可以建另外一个pool存块格式的数据;甚至你可以因为权限,针对不同的用户创建不同的pool。
对于一个pool来说,下面有多个pg。
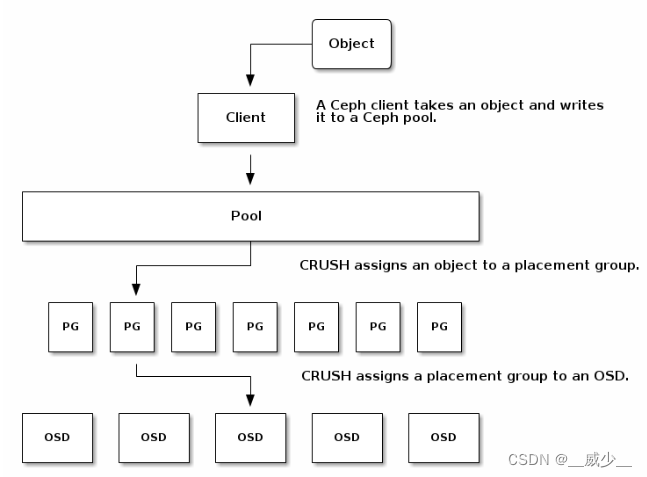
1、ceph对数据保证高可用
有俩种方式一个是数据拷贝。对于数据拷贝有俩种实现方式:
- 多副本
把同一份数据原封不动拷贝复制到多个osd,简单理解。 - 纠错码
每一份数据按照纠错码原理,切割成多块,然后把多块内容存储到多个osd。
复制的原理对于俩种场景是类似的,只不过拷贝复制的内容有差别。一种是同样的数据存在多份,一种是按照纠错码存错多个地方。具体选用哪种方式,可用在创建pool的时候选定数据复制方式。
数据复制的流程大致是:当写入一个对象的时候,集群crush会先把对象分配到一个pg下面。对于一个pg,集群会首先计算出一个首席的osd,当确定了首席osd之后,算法会接着计算次要的俩个osd。接下来首席osd,会把整个pg复制到另外俩个osd上。
2、集群高可用
ceph有monitor模块时刻监听和收集集群情况,当客户端需要和集群交互的时候,可以通过monitor获取当前集群最新情况。为了应对monitor模块的单点问题,ceph针对monitor设置了一个集群,来避免monitor自身的稳定性。monitor集群内部的状态一致性通过多数同意常见的算法来决策。
继续补充中…














 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









