






概要: 索引(MySQL中的key)是存储引擎用于快速找到记录的一种数据结构
索引文件的存储是独立与存储的数据的一部分 就像是书的目录与内容的关系
索引本身也很大 因此索引往往以索引文件的形式存储的磁盘上 因此索引查找过程中就要产生磁盘I/O消耗 I/O读取直接地影响了数据库的效率 所以索引要尽量减少 查找过程中磁盘I/O的存取次数
索引优点
1.减少了服务器所需要扫描的数据量
2.避免了排序和生成临时表
3.随机的I/O变为顺序I/O
B-Tree索引
说道最基础的当然是B-Tree索引 它使用B-Tree数据结构来存储数据
(1.MySQL将一个节点的大小设为等于一个页 这样每个节点只需要一次I/O就可以完全载入)
B-tree又叫平衡多路查找树 关于他的定义各种百科资料非常全 也如图所示:
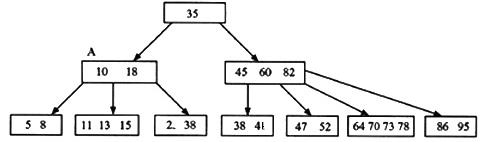
简单的概括 一个m阶的B-tree
1.每个节点最多有有m-1个关键字
2.每个节点有m个孩子
3.叶子节点到根的距离相同
4.每个节点最少有floor(m/2)个关键字 最少有ceil(m/2)个孩子
5.如图所示根据关键字来决定插入的位置
叶子结点不包含关键字 存储指针
InooDB的二级索引在叶子节点保存了主键值
..................................................................
( B E G )
/ / \ \
A ( B C D) (E F ) (G............Z)
.....以下略
............................................................................. 就像这样
只有叶子节点是指向被索引的数据的
如果建立一个表有如下索引
create table xxx(
....
key(last_name,first_name,dob)
);
如图所示
此索引对于如下查询类型有效
1.全值匹配
2.匹配最左前缀
3.匹配列前缀
4.匹配范围值
5.精确匹配某一列并范围匹配某一列
6.只访问索引的查询(覆盖查询)
因为索引树中的节点有序,所以可以order by顺序查找
相应的有如下限制
1.必须按照索引最左列开始查找
2.不能跳过索引的列
3.如果某个列是范围查找 右边的列无法使用索引优化查找
B+ Tree是B Tree的变种
和B-Tree基本概念差不多 具体可以看资料
1.非叶子结点的子树指针与关键字个数相同;
2.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
3为所有叶子结点增加一个链指针;
4所有关键字都在叶子结点出现;
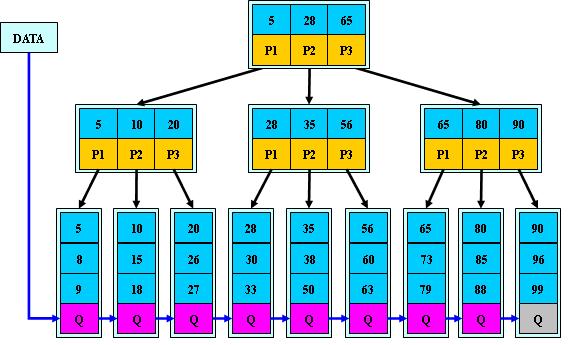
B+Tree支持两种搜索
1循叶结点链顺序搜索
2从根结点开始,进行自顶向下,直至叶结点的随机搜索。
Hash索引
(暂略)
索引策略
1.独立的列
where xx= 4 而不是 where xx+1=4 应该把列单独放在符号一侧
2.前缀索引
当查找很长的字符列(hash为佳) 或所以开始的部分字符 (索引的选择性 不重复索引数x/记录总数n)1/n-1 1为最佳
前缀要足够长(保证选择性) 但又不能太长
create table user (user_name varchar(50) not null);
select left(user_name,N) as shu from user 可以通过计算选择性 选择N的值
3.多列索引
....
4.选择合适的索引列顺序
...
5.聚簇索引
聚簇索引不是一种单独的索引类型 而是一种存储方式
最简单的理解就是 聚簇索引的顺序就是数据物理存储的顺序
普通的索引 叶子页是指向数据的位置 而聚簇是数据行存放在所以的叶子页中 (聚簇就是数据行和键值存储在一起)
因为一个表只能以一种顺序存储 所以聚簇索引也只能有一个
因为数据和索引都保存在B-Tree中 所以读取往往比非聚簇要快 (缺点是插入与更新时遇到的问题)
InooDB通过主键聚集数据(不可改变) 如果没有主键 InnoDB会选择一个非空所以代替 如果没有这样的索引 会隐式定义一个主键作为聚簇索引
explain (某某查询语句) 可以得到查询的部分信息
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 30
Extra: Using where; Using index
1 row in set (0.00 sec)
是覆盖查询时,extra会有using index
覆盖查询只需要读取索引 极大减少数据访问量
只需要扫描索引而不需要回表
使用索引扫描来做排序
生成有序结果有两个方法 1通过排序操作 2按索引顺序扫描
只有当索引列的顺序和order by子句属性怒完全一致 并且所有列排序顺序一致(正序或反序)
压缩前缀
...
create table 指定pack_keys参数来控制索引压缩
利用索引排序,order a,b 必须顺序一致 ,如都是asc都是desc
另外对于一些选择性低的索引列 可以添加一个不设限制的默认值
如 key(xx,male,xx) ;
xx=b,male in (男,女) ,xx=c这样 不管性别有没有限制索引都可用















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









